用户RFM模型及应用
RMF含义
R(Recency)(用户粘性,越小越好):用户最近一次交易时间的间隔。R值越大,表示用户交易发生的日期越久,反之则表示用户交易发生的日期越近
F(Frequency)(用户忠诚度,越大越好):用户在最近一段时间内交易的次数,F值越大,表示客户交易越频繁,反之则表示用户交易不够活跃。
M(Monetary)(用户贡献度,越大越好):用户在最近一段时间内交易的金额。M值越大,表示用户价值越高,反之则表示用户价值越低。
| R | F | M | 用户群体类型 |
|---|---|---|---|
| 0 | 1 | 1 | 重要价值用户 |
| 1 | 1 | 1 | 重要唤回用户 |
| 0 | 0 | 1 | 重要深耕用户 |
| 1 | 0 | 1 | 重要挽留用户 |
| 0 | 1 | 0 | 潜力用户 |
| 1 | 1 | 0 | 一般维持用户 |
| 0 | 0 | 0 | 新用户 |
| 1 | 0 | 0 | 流失用户 |
用户RMF模型的用途
针对不同类型用户,提出可落地的策列建议,采取不同运营手段措施。
用户RMF模型处理思路
以电商数据为例
1、确认待分析数据
不同业务R、F、M指标定义不同。
例如:
在电商销售案例中,通过最后一次消费时间间隔(R)、消费频率(F)和消费金额(M)进行定义;
在用户使用产品案例中,通过用户最后一次使用的时间间隔(R)、使用频率(F)、和对产品功能的使用(M)进行定义;
在借贷平台的与其用户案例中,通过最后一次进入还款页面的时间间隔(R)、进入还款页面的次数(F)、应还款的账单金额(M)进行定义
| 值 | 计算方法 | 计算需要的数据 |
|---|---|---|
| R | 最后一次订单日期据今天(或设定时间)的间隔 | 用户ID、订单日期 |
| F | 一年内用户下单次数 | 用户ID |
| M | 一年内用户下单总额 | 用户ID、销售额 |
2、计算需要的数据
3、给R、F、M按值划分高低维度
方法一:平均值
平均值作为依据进行划分,(R值计算的大小和用户价值呈反比,故高于依据的作为低值)
注:由于大部分数据呈长尾分布,导致平均数被拔高或压低,此时以平均数作为参考并不合适。例如:有一用户的消费金额达到100K,普遍用户消费1K,此时平均值被拔高。
方法二:中位数或四分位数(推荐)
选择四分位数作为依据进行划分,(R值计算的大小和用户价值呈反比,故高于依据的作为低值)
4、量化用户价值
将RFM总值量化为用户价值
方法一:字符串对应法
方法二:数值计算法
将R、F、M三组数据分别无量纲化处理映射到[0,1]区间再合理放大然后相加。(即跳过了给第三步给RFM划分高低维度的步骤)
无量纲化处理具体原理和方法
min-max归一化
公式:\(x^{'}=\frac{x-min}{max-min}\)
通过无量纲化处理将不同量级的数据归一化至同一量级,一般将该数放大100倍
RFM计算公式:RFM总值 = R值 * (-1) + F值 + M值 +100
注:-1是由于R值大小和用户质量成反比,+100是为了保证数据结果不会出现负数,该数不是固定的,如果RFM归一化未放大100倍,此处+1即可
RFM模型案例
现有一电商销售订单的数据表,使用用户RFM模型对用户数据进行分析
# 以2014年为时间段,计算F、M值
# 获取2014年数据
df_14 = df[df['Order_Year']==2014]
'''
|R|最后一次订单日期据今天(或设定时间)的间隔|用户ID、订单日期|
|F|一年内用户下单次数|用户ID|
|M|一年内用户下单总额|用户ID、销售额|
提取出需要的数据
'''
df_14=df_14[['CustomerID','OrderDate','Sales']]
df_14
# 将用户ID作为索引
df_14.set_index('CustomerID',inplace=True)
# 为了计算F,增加一列(因为需要累计同一用户订单个数
df_14['orders'] = 1
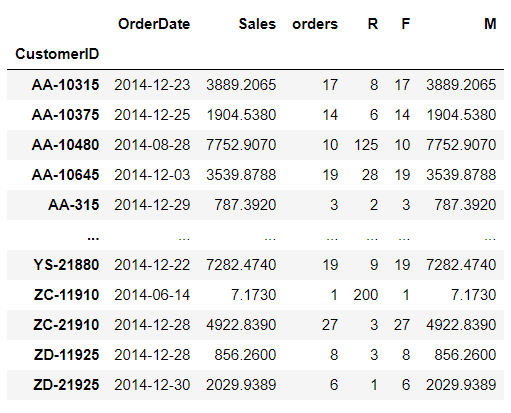
# 将同一用户的订单最大时间、下单次数总合、下单总额以数据透视表的方式计算并保存
customer_pivot = pd.pivot_table(df_14,
index = 'CustomerID',
values=['OrderDate','orders','Sales'],
aggfunc={'OrderDate':'max',
'orders':'sum',
'Sales':'sum'})
# R 以所用用户中最后下单的时间作为分析开始的一天
customer_pivot['R'] = (customer_pivot.OrderDate.max()-customer_pivot.OrderDate).dt.days
# F
# 新建一个F列,或者可以直接将orders列进行重命名(customer_pivot.rename(columns=,inplace=)
customer_pivot['F'] = customer_pivot.orders
# M
customer_pivot['M'] = customer_pivot.Sales
customer_pivot
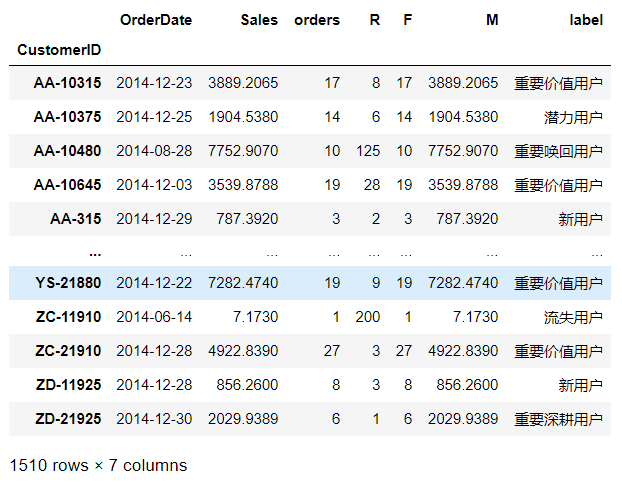
# 给RFM划分高低维度
def func(x):
# 根据正负,标记1,0
# level是一个DataFrame类型分别有R、F、M三列
level = x.apply(lambda x:'1' if x >=0 else '0')
# 将RFM值拼成一列 label是Series类型
label = level.R+level.F+level.M
# 构建字典 量化用户价值
d = {
'011':'重要价值用户',
'111':'重要唤回用户',
'001':'重要深耕用户',
'101':'重要挽留用户',
'010':'潜力用户',
'110':'一般维持用户',
'000':'新用户',
'100':'流失用户'
}
result = d[label]
return result
# 以中位数方式划分维度,以字符串对应法量化用户价值
customer_pivot['label']=customer_pivot[['R','F','M']].apply(lambda x:x-x.median()).apply(func,axis=1)
customer_pivot
用户RFM模型及应用的更多相关文章
- RFM用户分层模型简介
RFM用户分层模型在实际商业活动的数据分析中运用的还是挺多的,主要用于用户.商品.门店等等的分群和细分层次,分群之后就可以进行定向精准营销和推广以及促活和留存等等的运营活动. RFM是一种用户分层模型 ...
- 用户价值和RFM模型
什么是用户价值? 用户价值就是对公司来说有用的地方,比如有的公司看中用户的消费能力,有的公司则看中用户的忠诚度 .各公司的业务目的不同,用户价值的体现自然也不同.这里主要说一下适用于电商的RFM模型. ...
- 案例(一) 利用机器算法RFM模型做用户价值分析
一.案例背景 在产品迭代过程中,通常需要根据用户的属性进行归类,也就是通过分析数据,对用户进行归类,以便于在推送及转化过程中获得更大的收益. 本案例是基于某互联网公司的实际用户购票数据为研究对象, ...
- 数据分析-RFM模型用户分析
RFM模型 根据美国数据库营销研究所Arthur Hughes的研究,客户数据库中有3个神奇的要素,这3个要素构成了数据分析最好的指标: 最近一次消费 (Recency) 消费频率 (Frequenc ...
- RFM模型——构建数据库营销的商业战役!(转)
RFM模型:R(Recency)表示客户最近一次购买的时间有多远,F(Frequency)表示客户在最近一段时间内购买的次数,M (Monetary)表示客户在最近一段时间内购买的金额.一般原始数据为 ...
- RFM模型及R语言实现
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 一.基本概念 根据美国数据库营销研究所Arth ...
- RFM模型
python信用评分卡(附代码,博主录制) https://study.163.com/course/introduction.htm?courseId=1005214003&utm_camp ...
- 为啥我做的RFM模型被人说做错了,我错哪了?
本文转自知乎 作者:接地气的陈老师 ————————————————————————————————————————————————————— 有同学问:“为啥我做的RFM模型被客户/业务部门批斗,说 ...
- 用户价值模型 CITE :https://www.jianshu.com/p/34199b13ffbc
RFM用户价值模型的原理和应用 ▌定义 在众多的用户价值分析模型中,RFM模型是被广泛被应用的:RFM模型是衡量客户价值和客户创利能力的重要工具和手段,在RFM模式中,R(Recency)表示客户购 ...
随机推荐
- pt-online-schema-change 大数据表结构修改
使用场景: 在线修改大数据量表结构(ALTER tables without locking them) 文档参考:https://www.percona.com/doc/percona-toolki ...
- Django(33)Django操作cookie
前言 cookie:在网站中,http请求是无状态的.也就是说即使第一次和服务器连接后并且登录成功后,第二次请求服务器依然不能知道当前请求是哪个用户.cookie的出现就是为了解决这个问题,第一次登录 ...
- Docker —— 使用 Dockerfile 制作 Jdk + Tomcat 镜像
一.准备好Jdk和Tomcat apache-tomcat-8.5.50.tar.gz jdk-8u212-linux-x64.tar.gz 注意: Jdk 和 Tomcat 记得从官网下载,否则制作 ...
- python基础之进程、线程、协程篇
一.多任务(多线程) 多线程特点:(1)线程的并发是利用cpu上下文的切换(是并发,不是并行)(2)多线程执行的顺序是无序的(3)多线程共享全局变量(4)线程是继承在进程里的,没有进程就没有线程(5) ...
- SPI总线 通俗易懂讲解——(转载)
SPI总线 MOTOROLA公司的SPI总线的基本信号线为3根传输线,即SI.SO.SCK.传输的速率由时钟信号SCK决定,SI为数据输入.SO为数据输出.采用SPI总线的系统如图8-27所示,它包含 ...
- LT4020替代方案
国产 替代LT4020的方案 南芯 展讯的方案 https://item.taobao.com/item.htm?spm=a230r.1.14.21.6f27bf96rrAtci&id=56 ...
- 03-用三种方法设置CentOS7使用代理服务器上网
一.永久设置 编辑配置文件 vi /etc/profile 在文件后添加以下内容: export http_proxy='http://代理服务器IP:端口号' export https_proxy= ...
- Linux下RAID磁盘阵列的原理与搭建
RAID概念 磁盘阵列(Redundant Arrays of Independent Disks,RAID),有"独立磁盘构成的具有冗余能力的阵列"之意. 磁盘阵列是由很多价格较 ...
- GO学习-(22) Go语言之依赖管理
Go语言之依赖管理 Go语言的依赖管理随着版本的更迭正逐渐完善起来. 依赖管理 为什么需要依赖管理 最早的时候,Go所依赖的所有的第三方库都放在GOPATH这个目录下面.这就导致了同一个库只能保存一个 ...
- 使用ubuntu charmed kubernetes 部署一套生产环境的集群
官方文档: https://ubuntu.com/kubernetes/docs 搭建一个基本的集群 集群ip规划 hostname ip ubuntu-1 10.0.0.10 juju-contro ...