python爬虫——《瓜子网》的广州二手车市场信息
由于多线程爬取数据比单线程的效率要高,尤其对于爬取数据量大的情况,效果更好,所以这次采用多线程进行爬取。具体代码和流程如下:
import math
import re
from concurrent.futures import ThreadPoolExecutor
import requests
import lxml
import lxml.etree
# 获取网页源代码
def getHtml(url, header):
try:
response = requests.get(url, headers=header)
response.raise_for_status()
return response.content.decode('utf-8')
except:
return ''
# 获取翻页url
def getPageUrl(url, response):
mytree = lxml.etree.HTML(response)
# 页码
carNum = mytree.xpath('//*[@id="post"]/p[3]/text()')[0]
carNum = math.ceil(int(re.findall('(\d+)', carNum)[0]) / 40)
urlList = url.rsplit('/', maxsplit=1)
pageUrlList = []
if carNum != 0:
for i in range(1, carNum + 1):
pageUrl = urlList[0] + "/o" + str(i) + "/" + urlList[1]
pageUrlList.append(pageUrl)
return pageUrlList
# 获取汽车品牌
def getCarBrand(response):
mytree = lxml.etree.HTML(response)
# 汽车品牌url
carBrandUrl = mytree.xpath('//div[@class="dd-all clearfix js-brand js-option-hid-info"]/ul/li/p/a/@href')
# 汽车品牌名
carBrandName = mytree.xpath('//div[@class="dd-all clearfix js-brand js-option-hid-info"]/ul/li/p/a/text()')
carBrandDict = {}
for i in range(len(carBrandName)):
carBrandDict[carBrandName[i]] = "https://www.guazi.com" + carBrandUrl[i]
return carBrandDict
# 获取汽车信息
def getCarInfo(pageUrl, carBrandName):
response = getHtml(pageUrl, header)
mytree = lxml.etree.HTML(response)
for i in range(40):
# 汽车名称
carName = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/h2/text()')[i]
# 汽车图片
carPic = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/img/@src')[i]
carPic = carPic.rsplit("jpg", maxsplit=1)[0] + 'jpg'
# 汽车出产年份、里程数
carInfo = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/div[1]/text()')[i]
# 现价
carCurrentPrice = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/div[2]/p/text()')[i] + "万"
# 原价
carOriginPrice = mytree.xpath('//ul[@class="carlist clearfix js-top"]/li/a/div[2]/em/text()')[i]
print(carName, carPic, carInfo, carCurrentPrice, carOriginPrice)
# 写入文件
path = carBrandName + '.txt'
with open(path, 'a+') as f:
f.write(str((carName, carPic, carInfo, carCurrentPrice, carOriginPrice)) + '\n')
if __name__ == '__main__':
url = 'https://www.guazi.com/gz/buy/'
header = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.85 Safari/537.36",
}
# 获得初始页源代码
html = getHtml(url, header)
# 获取汽车品牌信息字典
carBrandDict = getCarBrand(html)
# 多线程(10条的线程池)
with ThreadPoolExecutor(10) as exT:
# 程序执行流程
# 根据汽车品牌进行爬取
for carBrandName, carBrandUrl in carBrandDict.items():
# 获取不同品牌页面源代码
html = getHtml(carBrandUrl, header)
# 获取当前品牌页面的页码url
pageUrlList = getPageUrl(carBrandUrl, html)
# 翻页
for pageUrl in pageUrlList:
# 获取汽车信息并写入文件
exT.submit(getCarInfo, pageUrl, carBrandName)![]()
结果如下:
![]()
![]()
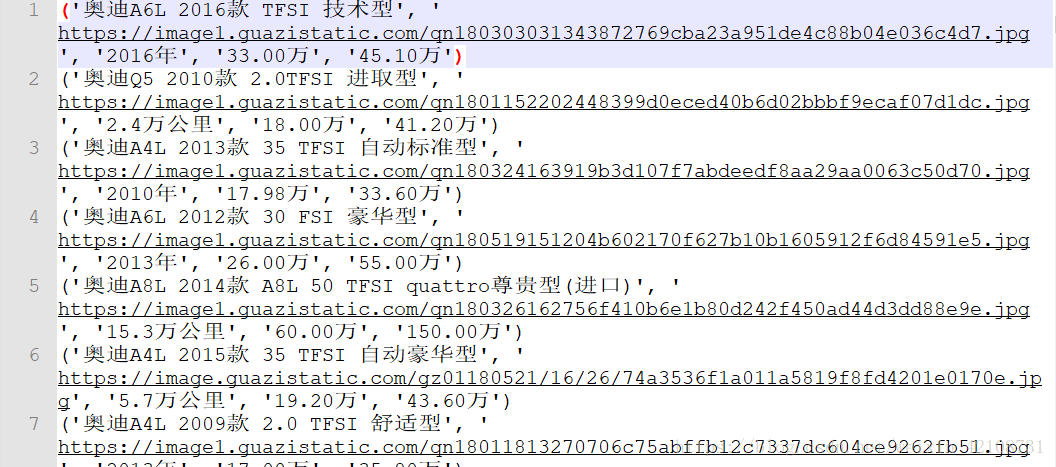
由于《瓜子网》更新过域名,所以之前有评论说网页打不开,现已做了处理,程序能正常爬取数据啦!
以上就是我的分享,如果有什么不足之处请指出,多交流,谢谢!
如果喜欢,请关注我的博客:https://www.cnblogs.com/qiuwuzhidi/
想获取更多数据或定制爬虫的请点击python爬虫专业定制
python爬虫——《瓜子网》的广州二手车市场信息的更多相关文章
- python爬虫实例--网易云音乐排行榜爬虫
网易云音乐,以前是有个api 链接的json下载的,现在没了, 只有音乐id,title , 只能看播放请求了, 但是播放请求都是加密的值,好坑... 进过各种努力, 终于找到了个大神写的博客,3.6 ...
- Python 爬虫 当当网图书 scrapy
目标站点需求分析 获取当当网每个图书名字和评论数 涉及的库 scrapy,mysql 获取解析单页源码 保存到数据库中 结果
- python爬虫 赶集网
#coding=utf-8import requestsfrom lxml import etreefrom sqlalchemy import create_enginefrom sqlalchem ...
- Python爬虫之爬取慕课网课程评分
BS是什么? BeautifulSoup是一个基于标签的文本解析工具.可以根据标签提取想要的内容,很适合处理html和xml这类语言文本.如果你希望了解更多关于BS的介绍和用法,请看Beautiful ...
- Python爬虫开源项目代码,爬取微信、淘宝、豆瓣、知乎、新浪微博、QQ、去哪网等 代码整理
作者:SFLYQ 今天为大家整理了32个Python爬虫项目.整理的原因是,爬虫入门简单快速,也非常适合新入门的小伙伴培养信心.所有链接指向GitHub,祝大家玩的愉快 1.WechatSogou [ ...
- python链家网高并发异步爬虫asyncio+aiohttp+aiomysql异步存入数据
python链家网二手房异步IO爬虫,使用asyncio.aiohttp和aiomysql 很多小伙伴初学python时都会学习到爬虫,刚入门时会使用requests.urllib这些同步的库进行单线 ...
- python爬虫:爬取慕课网视频
前段时间安装了一个慕课网app,发现不用注册就可以在线看其中的视频,就有了想爬取其中的视频,用来在电脑上学习.决定花两天时间用学了一段时间的python做一做.(我的新书<Python爬虫开发与 ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫教程-15-读取cookie(人人网)和SSL(12306官网)
Python爬虫教程-15-爬虫读取cookie(人人网)和SSL(12306官网) 上一篇写道关于存储cookie文件,本篇介绍怎样读取cookie文件 cookie的读取 案例v16ssl文件:h ...
随机推荐
- ch1_6_1求解两种排序方法问题
考拉有n个字符串字符串,任意两个字符串长度都是不同的. 考拉最近学习到有两种字符串的排序方法: 1.根据字符串的字典序排序.例如: "car" < "carr ...
- Java中的映射Map - 入门篇
前言 大家好啊,我是汤圆,今天给大家带来的是<Java中的映射Map - 入门篇>,希望对大家有帮助,谢谢 简介 前面介绍了集合List,这里开始简单介绍下映射Map,相关类如下图所示 正 ...
- FFMPEG编译问题记录
一.ffmpeg下载与配置 下载地址 FFmpeg/FFmpeg (https://github.com/FFmpeg/FFmpeg) ~$ git clone https://github.com/ ...
- HTML5-本地存储浅谈
Web Storage是HTML5里面引入的一个类似于cookie的本地存储功能,可以用于客户端的本地存储 sessionStorage && localStorage session ...
- 幻灯片放映模式切换windows terminal背景图片
目录 幻灯片放映模式切换windows terminal背景图片 脚本功能 开发需求 使用技术 操作说明 使用示例 查看帮助 输入参数使用 脚本详情 引用参考 幻灯片放映模式切换windows ter ...
- MyBatis-Plus日常工作学习
一:Mybatis-Plus概述 MyBatis-Plus (opens new window)(简称 MP)是一个 MyBatis (opens new window)的增强工具,在 MyBatis ...
- 字符串转成KB,MB, GB
import java.text.DecimalFormat; public class SizeUtil { public static String GetImageSize(String ima ...
- 自动化kolla-ansible部署openstack+GPU透传方法
自动化kolla-ansible部署openstack+GPU透传方法 欢迎加QQ群:1026880196 进行交流学习 1. CentOS7.x-8.x系列为虚拟机配置GPU直通 1. 编辑文件vi ...
- Python基础语法和数据类型最全总结
摘要:总结了Python最全基础语法和数据类型总结,一文带你学会Python. 本文分享自华为云社区<Python最全基础语法和数据类型总结>,原文作者:北山啦 . 人生苦短,我用Pyth ...
- sql指令,增,删,查,改
增 insert into table (name,sex,age) value('张三','男','20') 向表中的name,sex,age,分别添加张三,男,20的内容 查 select ...