pipeline 步骤
一.简介
步骤是pipeline里执行的最小单位了,这里列举内置的相关步骤方便使用,省的去写很多shell,也不方便维护。
二.文件相关
删除当前目录
无参步骤,删除的是当前工作目录。通常它与dir步骤一起使用,用于删除指定目录下的内容。
deleteDir
切换到目录
默认pipeline工作在工作空间目录下(/root/.jenkins/workspace/xx项目名),dir步骤可以让我们切换到其他目录。
dir('/xx') {
deleteDir
}
判断文件是否存在
判断/tmp/a.jar文件是否存在
fileExists('/tmp/a.jar')
输出状态
script {
def status=fileExists('/tmp/a.jar')
print "${status}"
}
判断是否为类Unix
如果当前pipeline运行在一个类Unix系统上,则返回true
script {
def status=isUnix
print "${status}"
}
返回当前目录
pwd与Linux的pwd命令一样,返回当前所在目录
script {
def dir=pwd
print "dir"
}
将内容写入文件
writeFile支持的参数有:
- file:文件路径,可以是绝对路径,也可以是相对路径。
- text:要写入的文件内容。
- encoding(可选):目标文件的编码。如果留空,则使用操作系统默认的编码。如果写的是Base64的数据,则可以使用Base64编码。
writeFile(file: "/etc/pass", text: "xxxx", encoding: "UTF-8")
读取文件内容
readFile支持的参数有:
- file:路径,可以是绝对路径,也可以是相对路径。
- encoding(可选):读取文件时使用的编码。
当前例子,用writeFile写入内容,再用readFile读取内容到变量,最终打印变量
fileContents = readFile(file: "/etc/passwd", encoding: "UTF-8")
echo "$fileContents"
二.制品相关
存取临时文件
stash步骤可以将一些文件保存起来,以便被同一次构建的其他步骤或阶段使用。如果整个pipeline的所有阶段在同一台机器上执行,则stash步骤是多余的。所以,通常需要stash的文件都是要跨Jenkins node使用的。
stash步骤会将文件存储在tar文件中,对于大文件的stash操作将会消耗Jenkins master的计算资源。Jenkins官方文档推荐,当文件大小为5∼100MB时,应该考虑使用其他替代方案。
stash步骤的参数列表如下:
- name:字符串类型,保存文件的集合的唯一标识。
- allowEmpty:布尔类型,允许stash内容为空。
- excludes:字符串类型,将哪些文件排除。如果排除多个文件,则使用逗号分隔。留空代表不排除任何文件。
- includes:字符串类型,stash哪些文件,留空代表当前文件夹下的所有文件。
- useDefaultExcludes:布尔类型,如果为true,则代表使用Ant风格路径默认排除文件列表。
除了name参数,其他参数都是可选的。excludes和includes使用的是Ant风格路径表达式。
unstash步骤取出之前stash的文件。只有一个name参数,即stash时的唯一标识。通常stash与unstash步骤同时使用。
stash步骤在master节点上执行,而unstash步骤在node2节点上执行。
pipeline {
agent none
stages {
stage('stash') {
agent { label "master" }
steps {
script {
writeFile file: "a.txt", text: "$BUILD_NUMBER"
stash(name: "abc", include: "a.txt")
}
}
}
stage("unstash") {
agent { label "node2" }
steps {
script {
unstash("abc")
def content = readFile("a.txt")
echo "${content}"
}
}
}
}
}
三.命令相关
script
直接执行groovy的命令会报错,需要用script括起来。与命令相关的步骤其实是Pipeline:Nodes and Processes插件提供的步骤。由于它是Pipeline插件的一个组件,所以基本不需要单独安装。
script {
def browsers = ['chrome', 'firefox']
for (int i = 0; i < brosers.size(); ++i) {
echo "this is ${browsers[i]}"
}
}
sh
执行shell命令
sh步骤支持的参数有:
- script:将要执行的shell脚本,通常在类UNIX系统上可以是多行脚本。
- encoding:脚本执行后输出日志的编码,默认值为脚本运行所在系统的编码。
- returnStatus:布尔类型,默认脚本返回的是状态码,如果是一个非零的状态码,则会引发pipeline执行失败。如果returnStatus参数为true,则不论状态码是什么,pipeline的执行都不会受影响。
- returnStdout:布尔类型,如果为true,则任务的标准输出将作为步骤的返回值,而不是打印到构建日志中(如果有错误,则依然会打印到日志中)。除了script参数,其他参数都是可选的。
- returnStatus与returnStdout参数一般不会同时使用,因为返回值只能有一个。如果同时使用,则只有returnStatus参数生效。
sh "ls"
sh(script: "/root/test.sh", returnStdout: true)
bat、powershell
bat步骤执行的是Windows的批处理命令。powershell步骤执行的是PowerShell脚本,支持3+版本。这两个步骤支持的参数与sh步骤的一样。
四.调用其它pipeline
在Jenkins pipeline中可以使用build步骤实现调用另一个pipeline功能。build步骤是pipeline插件的一个组件,所以不需要另外安装插件,可以直接使用。
build步骤其实也是一种触发pipeline执行的方式,它与triggers指令中的upstream方式有两个区别:
1.build步骤是由上游pipeline使用的,而upstream方式是由下游pipeline使用的。
2.build步骤是可以带参数的,而upstream方式只是被动触发,并没有带参数。
调用本章开头的例子,可以steps部分这么写:
steps {
build(
job:"parameters-example",
parameters: [
booleanParam(name:'userFlag', value:true)
]
)
}
build步骤的基本2个参数
job(必填):目标Jenkins任务的名称
parameters(可选):数组类型,传入目标pipeline的参数列表。传参方法与定参方法类似
parameters: [
booleanParam(name:'DEBUG_BUILD', value:true),
password(name:'PASSWORD', value:'prodSECRET'),
string(name:'DEPLOY_ENV', value:'prod'),
text(name:'DEPLOY_TEXT', value:'a\n\b\nc\n'),
string(name:'CHOICES00', value:'dev')
]
我们注意到choice类型的参数没有对应的传参方法,而是使用string传参方法代替的。
除此之外,build步骤还支持其他三个参数
propagate(可选): 布尔类型,如果值为true,则只有当下游pipeline的最终结构状态为SUCCESS时,上游pipeline才算成功;如果值为flase,则不论下游pipeline的最终构建状态是什么,上游pipeline都忽略。默认值为true
quietPeriod(可选): 整形,触发下游pipeline后,下游pipeline等待多久执行。如果不设置此参数,则等待时长由下游pipeline确定,单位为秒。
wait(可选): 布尔类型,是否等待下游pipeline执行完成。默认值为true。
如果你使用了Folder插件,那么就需要注意build步骤的job参数的写法了。
使用Folder插件,可以让我们像管理文件夹下的文件一样来管理Jenkins项目。我们的Jenkins项目可以创建在这些文件夹下。如果目标pipeline与源pipeline在同一目录下,则可以直接使用名称; 如果不在同一目录下,则需要指定相对路径,如 ../sister-folder/downstream 或绝对路径。
五.处理复杂判断逻辑
有些场景要求我们根据传入的参数做一些逻辑判断。很自然的,就想到在script函数内实现
stage("deploy to test"){
steps{
script {
if (params.CHOICES == 'test') {
echo "deploy to test"
}
}
}
}
这样写起来很不优雅,Conditional BuildStep插件可以让我们像使用when指令一样进行条件判断。一下代码是安装后的写法
pipeline {
agent any
parameters {
choice(name:'CHOICES', choices:'dev\ntest\nstaging', description:'请选择部署的环境')
}
stages {
stage("deploy test") {
when {
expression {return params.CHOICES == 'test'}
}
steps {
echo "deploy to test"
}
}
stage("deploy staging") {
when {
expression {return params.CHOICES == 'staging'}
}
steps {
echo "deploy to staging"
}
}
}
}
现实中,我们会面对更复杂的判断条件。而expression表达式本质上就是一个Groovy代码矿,大大提高了表达式的灵活性。
或逻辑
when {
// A or B
expression {return A || B}
}
与逻辑
when {
// A or B
expression {return A && B}
}
从文件中取值
when {
expression {return readFile('pom.xml').contains('mycomponent')}
}
正则表达式
when {
expression {return token ==~ /(?i)(Y|YES|T|TRUE|ON|RUN)/}
}
六.其他步骤
error
主动报错,中止当前pipeline。error 步骤的执行类似于抛出一个异常。它只有一个必需参数:message。
error("there's an error")
tool
使用预定义的工具。
如果在Global Tool Configuration(全局工具配置)中配置了工具,那么可以通过tool步骤得到工具路径。
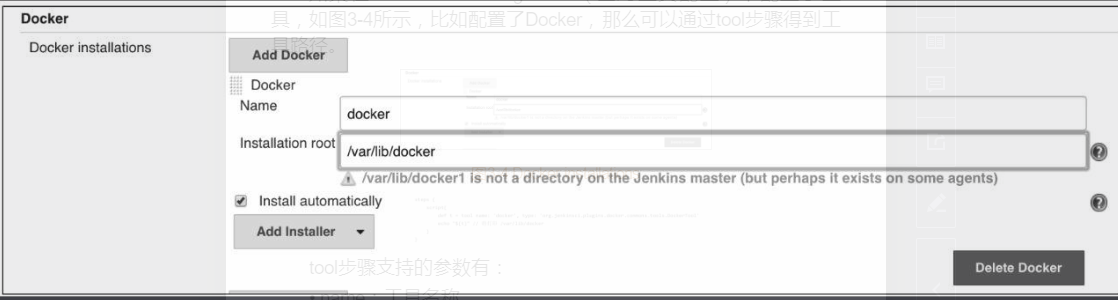
steps {
script{
def t = tool name: 'docker', type: 'org.jenkinsci.plugins.docker.commons.tiils.ockerTool'
echo "${t}" //打印 /var/lib/docker
}
}
tool步骤支持的参数有:
- name:工具名称。
- type(可选):工具类型,指该工具安装类的全路径类名。
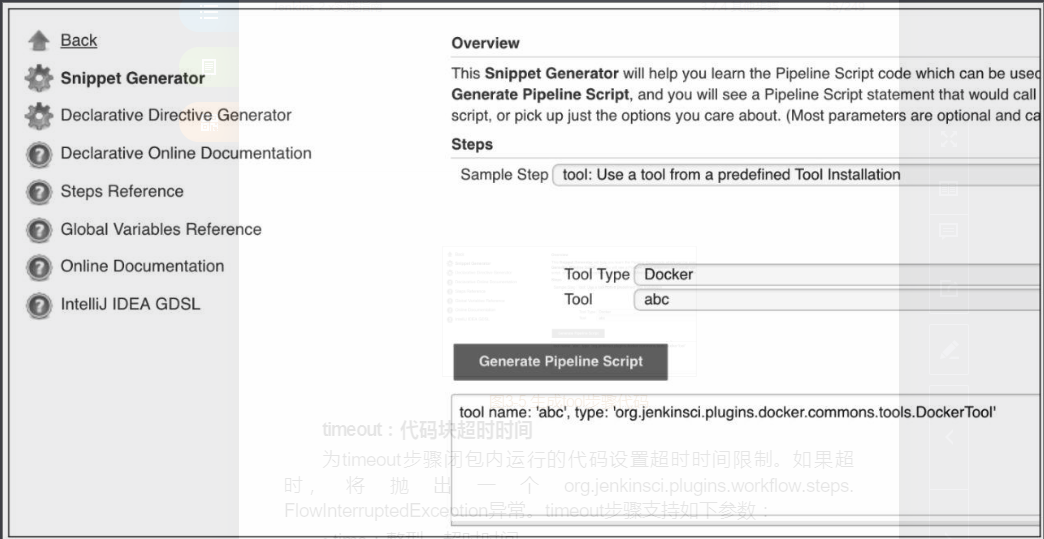
每个插件的type值都不一样,而且绝大多数插件的文档根本不写type值。除了到该插件的源码中查找,还有一种方法可以让我们快速找到type值,就是前往Jenkins pipeline代码片段生成器中生成该tool步骤的代码即可。
timeout
代码块超时时间。为timeout步骤闭包内运行的代码设置超时时间限制。如果超时,将抛出一个org.jenkinsci.plugins.workflow.steps.FlowInterruptedException异常。
timeout(5)
timeout步骤支持如下参数:
- time:整型,超时时间。
- unit(可选):时间单位,支持的值有NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS、MINUTES(默认)、HOURS、DAYS。
- activity(可选):布尔类型,如果值为true,则只有当日志没有活动后,才真正算作超时。
waitUntil
等待条件满足。
不断重复waitUntil块内的代码,直到条件为true。waitUntil不负责处理块内代码的异常,遇到异常时直接向外抛出。waitUntil步骤最好与timeout步骤共同使用,避免死循环。示例如下:
timeout(50) {
waitUntil {
script {
def r = sh script: 'curl http://example', returnStatus: true
retturn (r == 0)
}
}
}
retry
重复执行块
执行N 次闭包内的脚本。如果其中某次执行抛出异常,则只中止本次执行,并不会中止整个retry的执行。同时,在执行retry的过程中,用户是无法中止pipeline的。
steps {
retry(20) {
script {
sh script: 'curl http://example', returnStatus: true
}
}
}
sleep
sleep步骤可用于简单地暂停pipeline
其支持的参数有:
- time:整型,休眠时间。
- unit(可选):时间单位,支持的值有NANOSECONDS、MICROSECONDS、MILLISECONDS、SECONDS(默认)、MINUTES、HOURS、DAYS。
sleep(120) //120秒
sleep(time:'2', unit:"MINUTES") //2分钟
自动清理空间
通常,当pipeline执行完成后,并不会自动清理空间。如果需要(通常需要)清理工作空间,则可以通过Workspace Cleanup插件实现。
注意:需要ws-cleanup插件
在post部分加入插件步骤
post {
always {
cleanWs()
}
}
七.ANT风格表达式
Ant是比Maven更老的Java构建工具。Ant发明了一种描述文件路径的表达式,大家都习惯称其为Ant风格路径表达式。Jenkins pipeline的很多步骤的参数也会使用此变道时。
| Path | Description |
|---|---|
| /app/*.x | 匹配(Matches)app路径下所有.x文件 |
| /app/p?ttern | 匹配(Matches) /app/pattern 和 /app/pXttern,但是不包括/app/pttern |
| /**/example | 匹配项目根路径下 /project/example, /project/foow/example, 和 /example |
| /app/**/dir/file. | 匹配(Matches) /app/dir/file.jsp, /app/foo/dir/file.html,/app/foo/bar/dir/file.pdf, 和 /app/dir/file.java |
| /**/*.jsp | 匹配项目根路径下任何的.jsp 文件 |
需要注意的是,路径匹配遵循最长匹配原则(has more characters),例如/app/dir/file.jsp符合/**/.jsp和/app/dir/.jsp两个路径模式,那么最终就是根据后者来匹配。
pipeline 步骤的更多相关文章
- Jenkins pipeline:pipeline 使用之语法详解
一.引言 Jenkins 2.0的到来,pipline进入了视野,jenkins2.0的核心特性. 也是最适合持续交付的feature. 简单的来说,就是把Jenkins1.0版本中,Project中 ...
- Jenkins pipeline:pipeline 语法详解
jenkins pipeline 总体介绍 pipeline 是一套运行于jenkins上的工作流框架,将原本独立运行于单个或者多个节点的任务连接起来,实现单个任务难以完成的复杂流程编排与可视化. ...
- 使用Jenkins pipeline流水线构建docker镜像和发布
新建一个pipeline job 选择Pipeline任务,然后进入配置页面. 对于Pipeline, Definition选择 "Pipeline script from SCM" ...
- [持续交付实践] pipeline使用:语法详解
一.引言 jenkins pipeline语法的发展如此之快用日新月异来形容也不为过,而目前国内对jenkins pipeline关注的人还非常少,相关的文章更是稀少,唯一看到w3c有篇相关的估计是直 ...
- 1. Tensorflow高效流水线Pipeline
1. Tensorflow高效流水线Pipeline 2. Tensorflow的数据处理中的Dataset和Iterator 3. Tensorflow生成TFRecord 4. Tensorflo ...
- Jenkins pipeline 语法详解
原文地址http://www.cnblogs.com/fengjian2016/p/8227532.html pipeline 是一套运行于jenkins上的工作流框架,将原本独立运行于单个或者多个节 ...
- 转~Jenkins pipeline:pipeline 使用之语法详解
一.引言 Jenkins 2.0的到来,pipline进入了视野,jenkins2.0的核心特性. 也是最适合持续交付的feature. 简单的来说,就是把Jenkins1.0版本中,Project中 ...
- Apache Beam实战指南 | 大数据管道(pipeline)设计及实践
Apache Beam实战指南 | 大数据管道(pipeline)设计及实践 mp.weixin.qq.com 策划 & 审校 | Natalie作者 | 张海涛编辑 | LindaAI 前 ...
- pipeline 结构设计
目录 一.pipeline步骤 二.案例 pipeline详解 只生成一次制品 不同环境部署 系统集成测试 指定版本部署 一.pipeline步骤 当团队开始设计第一个pipeline时,该如何下手呢 ...
随机推荐
- [loj3031]聚会
对于一棵树(初始仅包含节点0),不断加入一个不在树中的节点$u$(不需要随机),并维护这棵树 具体的,对这棵树点分治,假设当前重心$v$有$d$个子树,假设其中第$i$个子树根为$r_{i}$,子树大 ...
- [loj6088]可持久化最长不降子序列
考虑二分求LIS的过程,就是维护一个序列,其中第i个数表示长度为i的最小结尾,而插入操作就是查找第一个大于x的位置并替换掉 用线段树维护,二分的过程也可以用线段树来完成,对线段树可持久化即可 1 #i ...
- [loj3278]收获
人的移动之间会相互影响,因此不妨看成果树逆时针移动,显然果树之间独立 考虑建图:1.每一棵果树向其逆时针旋转后第一个人连边:2.每一个人向其逆时针旋转不小于$C$的第一个人连边(即下一个摘的人),边权 ...
- [nowcoder5666B]Infinite Tree
首先考虑由$1!,2!,...,n!$所构成的虚树的一些性质: 1.每一个子树内所包含的阶乘的节点都是一个连续的区间(证明:对于子树k,如果存在$x!$和$y!$,即说明$x!$和$y!$的前$\de ...
- ICCV2021 | SOTR:使用transformer分割物体
前言 本文介绍了现有实例分割方法的一些缺陷,以及transformer用于实例分割的困难,提出了一个基于transformer的高质量实例分割模型SOTR. 经实验表明,SOTR不仅为实例分割提供了 ...
- nginx反向代理出错:proxy_pass
问题描述: 一台服务器代理访问另一台服务器,代码如下图所示: 重新加载nginx后不会跳到该域名,而是出现error的页面. 查看error.log日志为以下报错: 2021/03/09 23:07: ...
- 在Winform框架的多文档界面中实现双击子窗口单独弹出或拖出及拽回的处理
在基于DevExpress的多文档窗口界面中,我们一般使用XtraTabbedMdiManager来管理多文档窗口的一些特性,如顶部菜单,页面的关闭按钮处理,以及一些特殊的设置,本篇随笔介绍这些特点, ...
- 洛谷 P7620 - CF1431J Zero-XOR Array(状压 dp)
洛谷题面传送门 首先显然题目等价于求有多少个长度 \(n-1\) 的序列 \(b\) 满足 \(a_i\le b_i\le a_{i+1}\),满足 \(b_1\oplus b_2\oplus\cdo ...
- 26-Palindrome Number
回文数的判定,不使用额外的空间 Determine whether an integer is a palindrome. Do this without extra space. 思路:将一个整数逆 ...
- 【Linux】CentOS下升级Python和Pip版本全自动化py脚本
[Linux]CentOS下升级Python和Pip版本全自动化py脚本 CentOS7.6自带py2.7和py3.6 想要安装其它版本的话就要自己重新下载和编译py其它版本并且配置环境,主要是软链接 ...