日志收集系统系列(四)之LogAgent优化
实现功能
logagent根据etcd的配置创建多个tailtasklogagent实现watch新配置logagent实现新增收集任务logagent删除新配置中没有的那个任务logagent根据IP拉取自己的配置
代码实现
config/config.ini[kafka]
address=127.0.0.1:9092
chan_max_size=100000
[etcd]
address=127.0.0.1:2379
timeout=5
collect_log_key=/logagent/%s/collect_configconfig/config.gopackage conf
type Config struct {
Kafka Kafka `ini:"kafka"`
Etcd Etcd `ini:"etcd"`
}
type Kafka struct {
Address string `ini:"address"`
ChanMaxSize int `ini:"chan_max_zise"`
}
type Etcd struct {
Address string `ini:"address"`
Key string `ini:"collect_log_key"`
Timeout int `ini:"timeout"`
}main.gopackage main
import (
"fmt"
"gopkg.in/ini.v1"
"logagent/conf"
"logagent/etcd"
"logagent/kafka"
"logagent/taillog"
"logagent/tools"
"strings"
"sync"
"time"
)
var config = new(conf.Config)
// logAgent 入口程序
func main() {
// 0. 加载配置文件
err := ini.MapTo(config, "./conf/config.ini")
if err != nil {
fmt.Printf("Fail to read file: %v", err)
return
}
// 1. 初始化kafka连接
err = kafka.Init(strings.Split(config.Kafka.Address, ";"), config.Kafka.ChanMaxSize)
if err != nil {
fmt.Println("init kafka failed, err:%v\n", err)
return
}
fmt.Println("init kafka success.")
// 2. 初始化etcd
err = etcd.Init(config.Etcd.Address, time.Duration(config.Etcd.Timeout) * time.Second)
if err != nil {
fmt.Printf("init etcd failed,err:%v\n", err)
return
}
fmt.Println("init etcd success.")
// 实现每个logagent都拉取自己独有的配置,所以要以自己的IP地址实现热加载
ip, err := tools.GetOurboundIP()
if err != nil {
panic(err)
}
etcdConfKey := fmt.Sprintf(config.Etcd.Key, ip)
// 2.1 从etcd中获取日志收集项的配置信息
logEntryConf, err := etcd.GetConf(etcdConfKey)
if err != nil {
fmt.Printf("etcd.GetConf failed, err:%v\n", err)
return
}
fmt.Printf("get conf from etcd success, %v\n", logEntryConf)
// 2.2 派一个哨兵 一直监视着 zhangyafei这个key的变化(新增 删除 修改))
for index, value := range logEntryConf{
fmt.Printf("index:%v value:%v\n", index, value)
}
// 3. 收集日志发往kafka
taillog.Init(logEntryConf)
var wg sync.WaitGroup
wg.Add(1)
go etcd.WatchConf(etcdConfKey, taillog.NewConfChan()) // 哨兵发现最新的配置信息会通知上面的通道
wg.Wait()
}kafka/kafka.gopackage kafka
import (
"fmt"
"github.com/Shopify/sarama"
)
// 专门往kafka写日志的模块
type LogData struct {
topic string
data string
}
var (
client sarama.SyncProducer // 声明一个全局的连接kafka的生产者client
logDataChan chan *LogData
)
// init初始化client
func Init(addrs []string, chanMaxSize int) (err error) {
config := sarama.NewConfig()
config.Producer.RequiredAcks = sarama.WaitForAll // 发送完数据需要leader和follow都确认
config.Producer.Partitioner = sarama.NewRandomPartitioner // 新选出⼀个partition
config.Producer.Return.Successes = true // 成功交付的消息将在success channel返回
// 连接kafka
client, err = sarama.NewSyncProducer(addrs, config)
if err != nil {
fmt.Println("producer closed, err:", err)
return
}
// 初始化logDataChan
logDataChan = make(chan *LogData, chanMaxSize)
// 开启后台的goroutine,从通道中取数据发往kafka
go SendToKafka()
return
}
// 给外部暴露的一个函数,噶函数只把日志数据发送到一个内部的channel中
func SendToChan(topic, data string) {
msg := &LogData{
topic: topic,
data: data,
}
logDataChan <- msg
}
// 真正往kafka发送日志的函数
func SendToKafka() {
for {
select {
case log_data := <- logDataChan:
// 构造一个消息
msg := &sarama.ProducerMessage{}
msg.Topic = log_data.topic
msg.Value = sarama.StringEncoder(log_data.data)
// 发送到kafka
pid, offset, err := client.SendMessage(msg)
if err != nil{
fmt.Println("sned msg failed, err:", err)
}
fmt.Printf("send msg success, pid:%v offset:%v\n", pid, offset)
//fmt.Println("发送成功")
}
}
}etcd/etcd.gopackage etcd
import (
"context"
"encoding/json"
"fmt"
"go.etcd.io/etcd/clientv3"
"strings"
"time"
)
var (
cli *clientv3.Client
)
type LogEntry struct {
Path string `json:"path"` // 日志存放的路径
Topic string `json:"topic"` // 日志发往kafka中的哪个Topic
}
// 初始化etcd的函数
func Init(addr string, timeout time.Duration) (err error) {
cli, err = clientv3.New(clientv3.Config{
Endpoints: strings.Split(addr, ";"),
DialTimeout: timeout,
})
return
}
// 从etcd中获取日志收集项的配置信息
func GetConf(key string) (logEntryConf []*LogEntry, err error) {
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
resp, err := cli.Get(ctx, key)
cancel()
if err != nil {
fmt.Printf("get from etcd failed, err:%v\n", err)
return
}
for _, ev := range resp.Kvs {
//fmt.Printf("%s:%s\n", ev.Key, ev.Value)
err = json.Unmarshal(ev.Value, &logEntryConf)
if err != nil {
fmt.Printf("unmarshal etcd value failed,err:%v\n", err)
return
}
}
return
}
// etcd watch
func WatchConf(key string, newConfChan chan<- []*LogEntry) {
rch := cli.Watch(context.Background(), key) // <-chan WatchResponse
// 从通道尝试取值(监视的信息)
for wresp := range rch {
for _, ev := range wresp.Events {
fmt.Printf("Type: %s Key:%s Value:%s\n", ev.Type, ev.Kv.Key, ev.Kv.Value)
// 通知taillog.taskMgr
var newConf []*LogEntry
//1. 先判断操作的类型
if ev.Type != clientv3.EventTypeDelete {
// 如果不是是删除操作
err := json.Unmarshal(ev.Kv.Value, &newConf)
if err != nil {
fmt.Printf("unmarshal failed, err:%v\n", err)
continue
}
}
fmt.Printf("get new conf: %v\n", newConf)
newConfChan <- newConf
}
}
}taillog/taillog.gopackage taillog
import (
"context"
"fmt"
"github.com/hpcloud/tail"
"logagent/kafka"
)
// 专门收集日志的模块
type TailTask struct {
path string
topic string
instance *tail.Tail
// 为了能实现退出r,run()
ctx context.Context
cancelFunc context.CancelFunc
}
func NewTailTask(path, topic string) (t *TailTask) {
ctx, cancel := context.WithCancel(context.Background())
t = &TailTask{
path: path,
topic: topic,
ctx: ctx,
cancelFunc: cancel,
}
err := t.Init()
if err != nil {
fmt.Println("tail file failed, err:", err)
}
return
}
func (t TailTask) Init() (err error) {
config := tail.Config{
ReOpen: true, // 充新打开
Follow: true, // 是否跟随
Location: &tail.SeekInfo{Offset: 0, Whence: 2}, // 从文件哪个地方开始读
MustExist: false, // 文件不存在不报错
Poll: true}
t.instance, err = tail.TailFile(t.path, config)
// 当goroutine执行的函数退出的时候,goriutine就退出了
go t.run() // 直接去采集日志发送到kafka
return
}
func (t *TailTask) run() {
for {
select {
case <- t.ctx.Done():
fmt.Printf("tail task:%s_%s 结束了...\n", t.path, t.topic)
return
case line :=<- t.instance.Lines: // 从TailTask的通道中一行一行的读取日志
// 3.2 发往kafka
fmt.Printf("get log data from %s success, log:%v\n", t.path, line.Text)
kafka.SendToChan(t.topic, line.Text)
}
}
}taillog/taillog_mgrpackage taillog
import (
"fmt"
"logagent/etcd"
"time"
)
var taskMrg *TailLogMgr
type TailLogMgr struct {
logEntry []*etcd.LogEntry
taskMap map[string]*TailTask
newConfChan chan []*etcd.LogEntry
}
func Init(logEntryConf []*etcd.LogEntry) {
taskMrg = &TailLogMgr{
logEntry: logEntryConf,
taskMap: make(map[string]*TailTask, 16),
newConfChan: make(chan []*etcd.LogEntry), // 无缓冲区的通道
}
for _, logEntry := range logEntryConf{
// 3.1 循环每一个日志收集项,创建TailObj
// logEntry.Path 要收集的全日志文件的路径
// 初始化的时候齐了多少个tailTask 都要记下来,为了后续判断方便
tailObj := NewTailTask(logEntry.Path, logEntry.Topic)
mk := fmt.Sprintf("%s_%s", logEntry.Path, logEntry.Topic)
taskMrg.taskMap[mk] = tailObj
}
go taskMrg.run()
}
// 监听自己的newConfChan,有了新的配合过来之后就做对应的处理
func (t *TailLogMgr) run() {
for {
select {
case newConf := <- t.newConfChan:
// 1. 配置新增
for _, conf := range newConf {
mk := fmt.Sprintf("%s_%s", conf.Path, conf.Topic)
_, ok := t.taskMap[mk]
if ok {
// 原来就有,不需要操作
continue
}else {
// 新增的
tailObj := NewTailTask(conf.Path, conf.Topic)
t.taskMap[mk] = tailObj
}
}
// 找出原来t.logEntry有,但是newConf中没有的,删掉
for _, c1 := range t.logEntry{ // 循环原来的配置
isDelete := true
for _, c2 := range newConf{ // 取出新的配置
if c2.Path == c1.Path && c2.Topic == c1.Topic {
isDelete = false
continue
}
}
if isDelete {
// 把c1对应的这个tailObj给停掉
mk := fmt.Sprintf("%s_%s", c1.Path, c1.Topic)
// t.taskNap[mk] ==> tailObj
t.taskMap[mk].cancelFunc()
}
}
// 2. 配置删除
// 3. 配置变更
fmt.Println("新的配置来了!", newConf)
default:
time.Sleep(time.Second)
}
}
}
// 一个函数,向外暴露taskMgr的newConfChan
func NewConfChan() chan <-[]*etcd.LogEntry {
return taskMrg.newConfChan
}tools/get_ippackage tools
import (
"net"
"strings"
)
// 获取本地对外IP
func GetOurboundIP() (ip string, err error) {
conn, err := net.Dial("udp", "8.8.8.8:80")
if err != nil {
return
}
defer conn.Close()
localAddr := conn.LocalAddr().(*net.UDPAddr)
//fmt.Println(localAddr.String())
ip = strings.Split(localAddr.IP.String(), ":")[0]
return
}
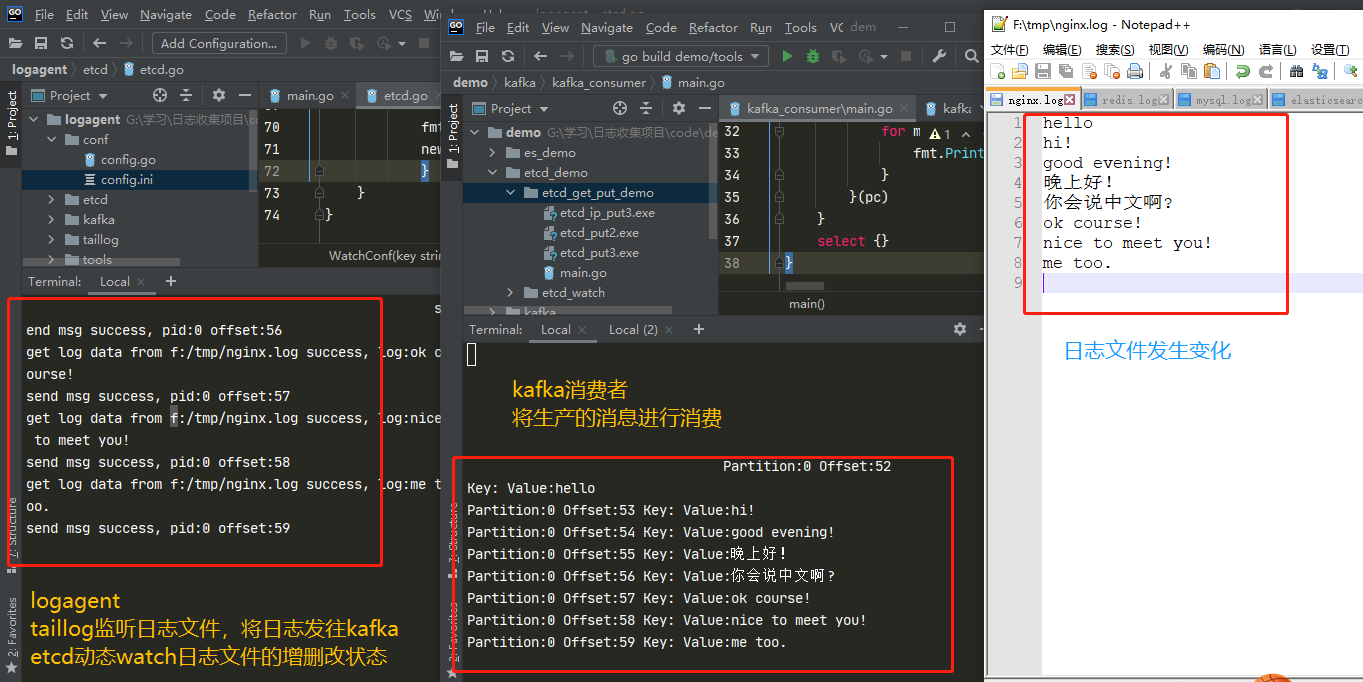
三. 连接kafka进行消费
将收集项配置放入etcd
package main
import (
"context"
"fmt"
"net"
"strings"
"time"
"go.etcd.io/etcd/clientv3"
)
// 获取本地对外IP
func GetOurboundIP() (ip string, err error) {
conn, err := net.Dial("udp", "8.8.8.8:80")
if err != nil {
return
}
defer conn.Close()
localAddr := conn.LocalAddr().(*net.UDPAddr)
fmt.Println(localAddr.String())
ip = strings.Split(localAddr.IP.String(), ":")[0]
return
}
func main() {
// etcd client put/get demo
// use etcd/clientv3
cli, err := clientv3.New(clientv3.Config{
Endpoints: []string{"127.0.0.1:2379"},
DialTimeout: 5 * time.Second,
})
if err != nil {
// handle error!
fmt.Printf("connect to etcd failed, err:%v\n", err)
return
}
fmt.Println("connect to etcd success")
defer cli.Close()
// put
ctx, cancel := context.WithTimeout(context.Background(), time.Second)
value := `[{"path":"f:/tmp/nginx.log","topic":"web_log"},{"path":"f:/tmp/redis.log","topic":"redis_log"},{"path":"f:/tmp/mysql.log","topic":"mysql_log"}]`
//value := `[{"path":"f:/tmp/nginx.log","topic":"web_log"},{"path":"f:/tmp/redis.log","topic":"redis_log"}]`
//_, err = cli.Put(ctx, "zhangyafei", "dsb")
//初始化key
ip, err := GetOurboundIP()
if err != nil {
panic(err)
}
log_conf_key := fmt.Sprintf("/logagent/%s/collect_config", ip)
_, err = cli.Put(ctx, log_conf_key, value)
//_, err = cli.Put(ctx, "/logagent/collect_config", value)
cancel()
if err != nil {
fmt.Printf("put to etcd failed, err:%v\n", err)
return
}
// get
ctx, cancel = context.WithTimeout(context.Background(), time.Second)
resp, err := cli.Get(ctx, log_conf_key)
//resp, err := cli.Get(ctx, "/logagent/collect_config")
cancel()
if err != nil {
fmt.Printf("get from etcd failed, err:%v\n", err)
return
}
for _, ev := range resp.Kvs {
fmt.Printf("%s:%s\n", ev.Key, ev.Value)
}
}消费者代码
package main
import (
"fmt"
"github.com/Shopify/sarama"
)
// kafka consumer
func main() {
consumer, err := sarama.NewConsumer([]string{"127.0.0.1:9092"}, nil)
if err != nil {
fmt.Printf("fail to start consumer, err:%v\n", err)
return
}
partitionList, err := consumer.Partitions("web_log") // 根据topic取到所有的分区
if err != nil {
fmt.Printf("fail to get list of partition:err%v\n", err)
return
}
fmt.Println("分区: ", partitionList)
for partition := range partitionList { // 遍历所有的分区
// 针对每个分区创建一个对应的分区消费者
pc, err := consumer.ConsumePartition("web_log", int32(partition), sarama.OffsetNewest)
if err != nil {
fmt.Printf("failed to start consumer for partition %d,err:%v\n", partition, err)
return
}
defer pc.AsyncClose()
// 异步从每个分区消费信息
go func(sarama.PartitionConsumer) {
for msg := range pc.Messages() {
fmt.Printf("Partition:%d Offset:%d Key:%s Value:%s\n", msg.Partition, msg.Offset, msg.Key, msg.Value)
}
}(pc)
}
select {}
}运行步骤
开启zookeeper
开启kafka
开启etcd
设置收集项配置到etcd
运行logagent从etcd加载收集项配置,使用taillog监听日志文件内容,将新增的日志内容发往kafka
连接kafka进行消费
添加日志内容,观察logagent生产和kafka消费状态
项目地址:https://gitee.com/zhangyafeii/go-log-collect
日志收集系统系列(四)之LogAgent优化的更多相关文章
- 日志收集系统系列(三)之LogAgent
一.什么是LogAhent 类似于在linux下通过tail的方法读日志文件,将读取的内容发给kafka,这里的tailf是可以动态变化的,当配置文件发生变化时,可以通知我们程序自动增加需要增加的配置 ...
- 日志收集系统系列(五)之LogTransfer
从kafka里面把日志取出来,写入ES,使用Kibana做可视化展示 1. ElasticSearch 1.1 介绍 Elasticsearch(ES)是一个基于Lucene构建的开源.分布式.RES ...
- 基于Flume的美团日志收集系统(二)改进和优化
在<基于Flume的美团日志收集系统(一)架构和设计>中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计.在本节中,我们将会讲述在实际部署和使用过程中遇到的问 ...
- 基于Flume的美团日志收集系统 架构和设计 改进和优化
3种解决办法 https://tech.meituan.com/mt-log-system-arch.html 基于Flume的美团日志收集系统(一)架构和设计 - https://tech.meit ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- GO学习-(33) Go实现日志收集系统2
Go实现日志收集系统2 一篇文章主要是关于整体架构以及用到的软件的一些介绍,这一篇文章是对各个软件的使用介绍,当然这里主要是关于架构中我们agent的实现用到的内容 关于zookeeper+kaf ...
- 用fabric部署维护kle日志收集系统
最近搞了一个logstash kafka elasticsearch kibana 整合部署的日志收集系统.部署参考lagstash + elasticsearch + kibana 3 + kafk ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- C语言实现鼠标绘图
使用C语言+EGE图形库(Easy Graphics Engine).思路是通过不断绘制直线来实现鼠标绘图的功能,前一个时刻鼠标的坐标作为直线的起点,现在时刻的坐标作为终点(严格意义是线段而不是直线) ...
- 关于og4j漏洞修复解决方案及源码编译
最近log4j爆出重大漏洞,程序员要赶紧修复了!文末提供已经编译好的jar包. 建议最好修复到log4j-2.15.0-rc2版本,临时解决方案还是存在jndi漏洞. 打开log4j官网https:/ ...
- pipeline parameters指令
目录 一.简介 二.类型 参数类型 多参数 一.简介 参数化pipeline是指通过传参来决定pipeline的行为.参数化让写pipeline就像写函数,而函数意味着可重用.更抽象.所以,通常使用参 ...
- GIT最基本使用
带'*':必须操作 不带'*':可能需要而且经常用的 常见步骤为下: *1.克隆项目:有两种不同类型的网址(https/ssh) git clone [url] *2.初始化本地仓库 git init ...
- Google Earth Engine 批量点击RUN任务,批量取消正在上传的任务
本文内容参考自: https://blog.csdn.net/qq_21567935/article/details/89061114 https://blog.csdn.net/qq_2156793 ...
- freeswitch APR-UTIL库消息队列实现
概述 freeswitch的核心源代码是基于apr库开发的,在不同的系统上有很好的移植性. APR库在之前的文章中已经介绍过了,APR-UTIL库是和APR并列的工具库,它们都是由APACHE开源出来 ...
- LuoguP1785 漂亮的绝杀 题解
Content 因太占排版,请自己去题面查看. Solution 声明:以下和题面相同的变量的意义均和题面相同. 这个题目 \(\texttt{if}\) 操作很多,其他的就是纯模拟. 首先,我们先判 ...
- Postman环境变量的使用
前言 请注意,Postman新版有ui上的改动,本文使用的Postman 版本8.4.0 for Mac, ui有调整,但是功能无改变. Postman是一款接口调测的软件,服务端开发的同学肯定会对自 ...
- Learning to Sample
此处主要提出几个疑问和想法: 疑问: 为什么需要这个匹配过程?虽然G可能不是P的子集,但是为什么一定需要他是子集呢? 如果一定要匹配的话,匹配过程是没法反向传播的,所以只可以在推理阶段使用,那么这个推 ...
- 谷歌protobuf(protocol-buffers)各种开发语言数据类型转换说明
官方文档:https://developers.google.cn/protocol-buffers/docs/proto proto2 proto3