centos 6.4-linux环境配置,安装hadoop-1.1.2(hadoop伪分布环境配置)
1 Hadoop环境搭建
hadoop 的6个核心配置文件的作用:
- core-site.xml:核心配置文件,主要定义了我们文件访问的格式hdfs://。
- hadoop-env.sh:主要配置我们的java路径。
- hdfs-site.xml:主要定义配置我们的hdfs的相关配置。
- mapred-site.xml:主要定义我们的mapreduce相关的一些配置。
- slaves:控制我们的从节点在哪里,datanode nodemanager在哪些机器上。
- yarn-site.xml:配置我们的resourcemanager资源调度。
2 Hadoop部署方式:本地模式、伪分布模式、集群模式
- 安装前准备工作:virtualbox、jdk、hadoop-1.1.2.tar.gz
- 本文主要是通过伪分布模式进行安装,伪分布模式安装步骤:关闭防火墙、修改ip、修改hostname、设置SSH自动登录、安装jdk、安装hadoop
2.1 Hadoop伪分布具体安装步骤
——前提条件:【使用root用户登录】
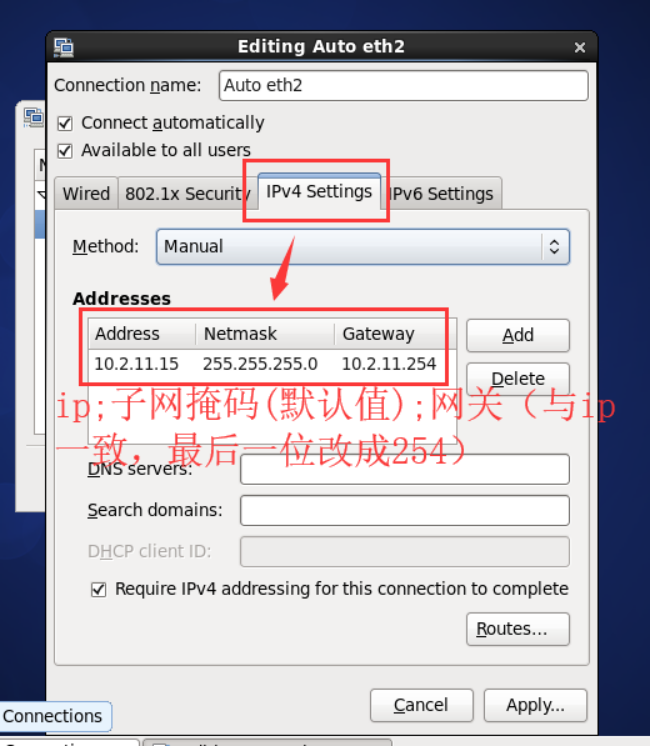
A.设置静态ip
在centos桌面右上角的图标上,右键修改,或者执行命令 vi /etc/sysconfig/network-scripts/ifcfg-eth2
重启网卡 执行命令service network restart
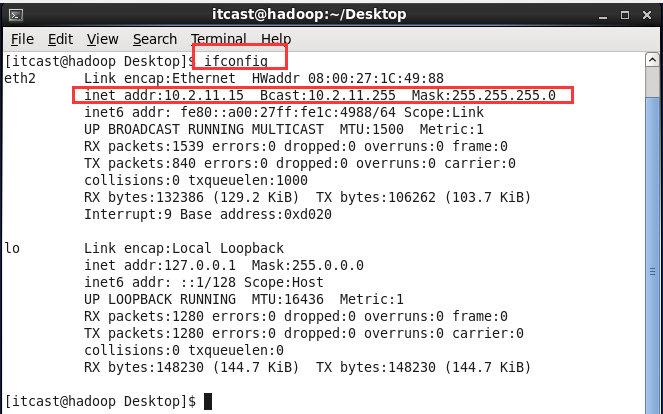
验证:执行命令ifconfig
B.修改主机名
步骤(1)和(2)最好操作步骤二
(1)修改当前会话中的主机名,执行命令 vi /etc/sysconfig/network
(2) 修改配置文件中的主机名,执行命令vi /etc/hosts
验证:重启机器 reboot -h now

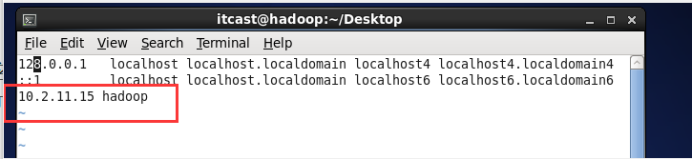
C.把hostname和ip绑定
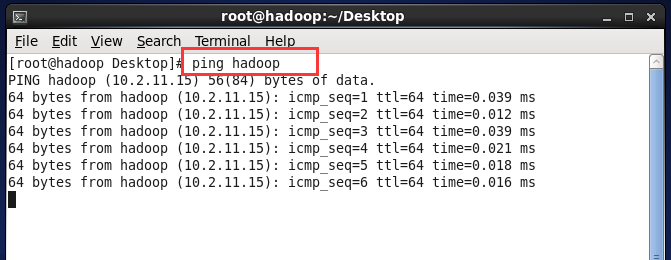
执行命令vi /etc/hosts,增加一行内容,如下:10.2.11.15 hadoop 保持退出
验证ping hadoop

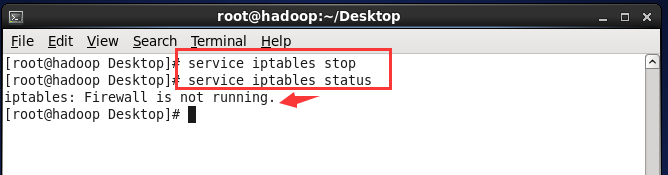
D.关闭防火墙
执行命令 service iptables stop
验证:service iptables status
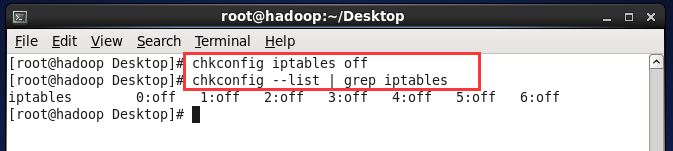
E.关闭防火墙的自动运行
执行命令 chkconfig iptables off
验证:chkconfig --list | grep iptables
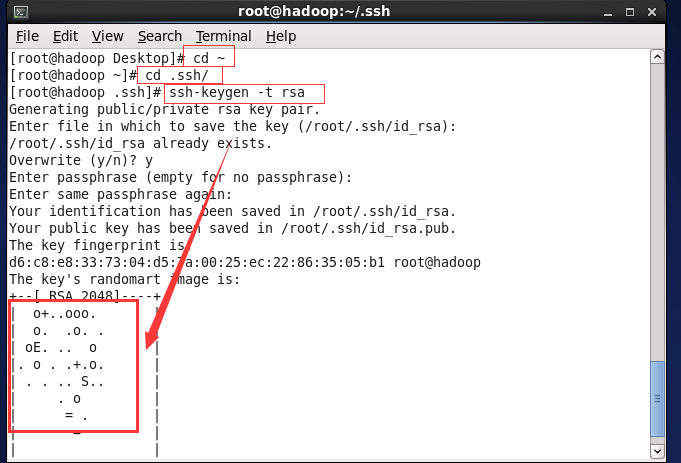
F.SSH(secure shell)的免密登录
存放在cd下的ssh目录下(cd ~ cd .ssh/)
(1) 执行命令 ssh-keygen -t rsa 产生秘钥,位于~/ .ssh 文件夹
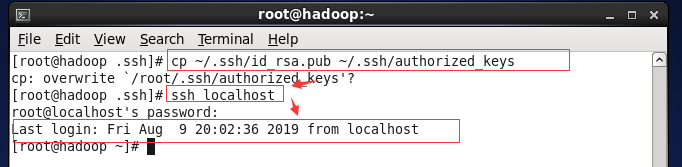
(2) 执行命令 cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
验证:ssh localhost
G.安装jdk
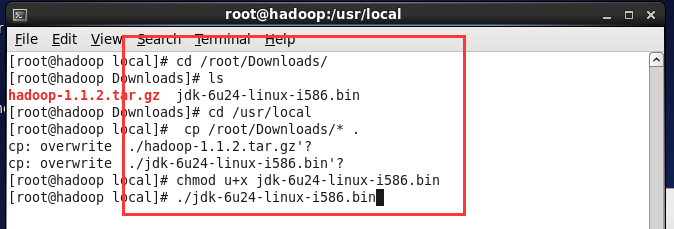
(1) 执行命令rm -rf /usr/local/* 删除所有内容

(2)使用winscp把jdk、hadoop文件从windows复制到/usr/downloads目录下

(3)执行命令 chmod u+x jdk-6u24-linux-i586.bin 赋予执行
(4)执行命令./jdk-6u24-linux-i586.bin 解压缩
(5)执行命令mv jdk1.6.0_24 jdk 重命名

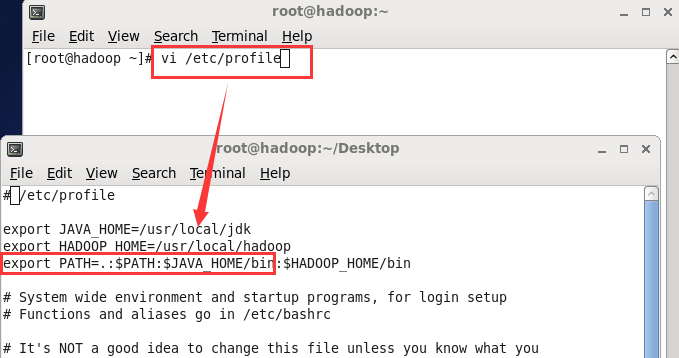
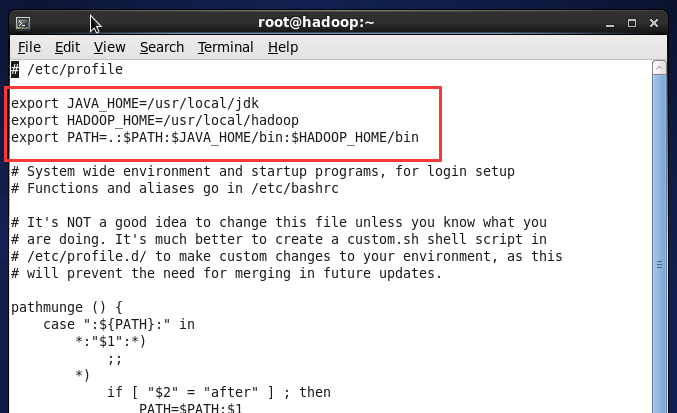
(6)执行命令vi /etc/profile 设置环境变量,增加2行内容
Export JAVA_HOME=/usr/local/jdk
Export PATH=.:$PATH:JAVA_HOME/bin
保持退出
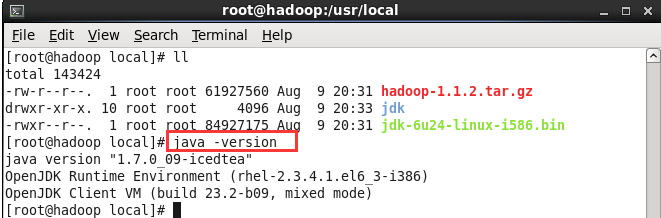
执行命令立即生效 source /etc/profile

H.安装hadoop
(1) 执行命令 tar -zxvf hadoop-1.1.2.tar
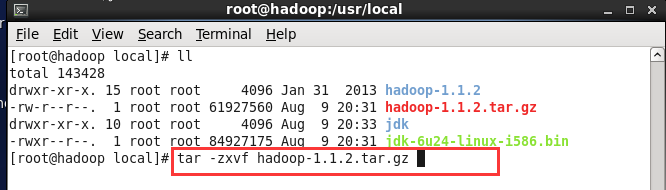
(2) 执行命令 mv hadoop-1.1.2 hadoop重命名
(3) 执行命令 vi /etc/profile 设置环境变量,增加了一行内:
export HADOOP_HOME=/usr/local/hadoop
修改一行内容:
Export PATH=.:$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin
保持退出
执行命令 source /etc/profile 让该设置立即生效

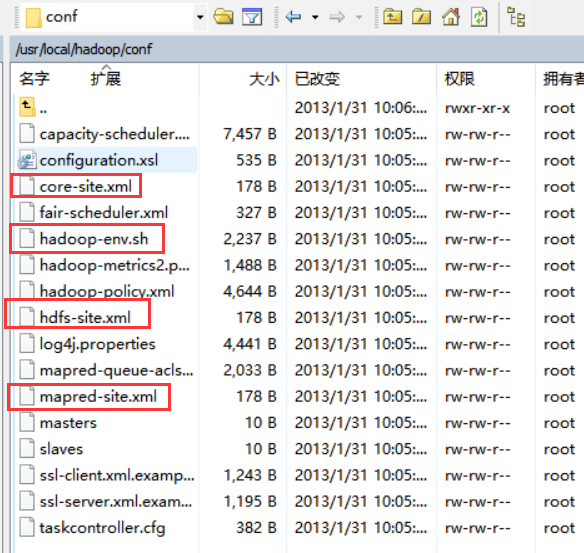
(4) 执行hadoop的配置文件,位于$HADOOP_HOME/conf目录下,修改配置文件hadoop-env.sh,core-site.xml,hdfs-site.xml、mapred-site.xml.
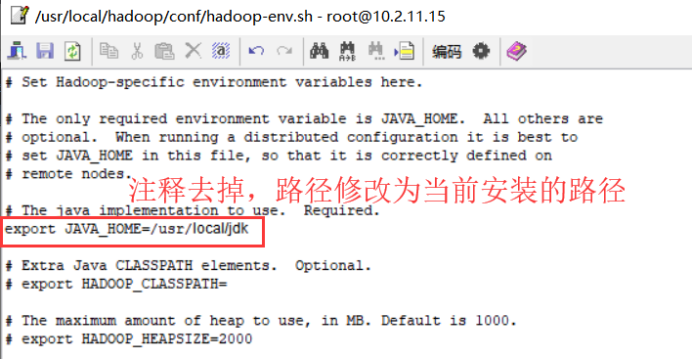
export JAVA_HOME=/usr/local/jdk
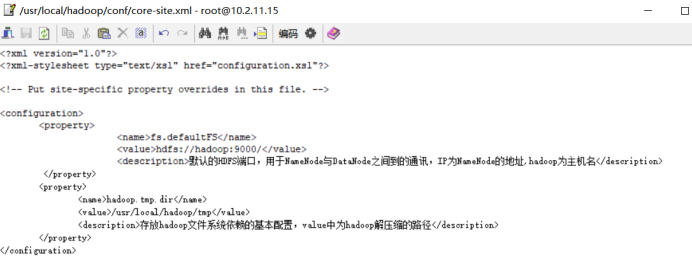
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop:9000/</value>
<description>默认的HDFS端口,用于NameNode与DataNode之间到的通讯,IP为NameNode的地址,hadoop为主机名</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
<description>存放hadoop文件系统依赖的基本配置,value中为hadoop解压缩的路径</description>
</property>
</configuration>
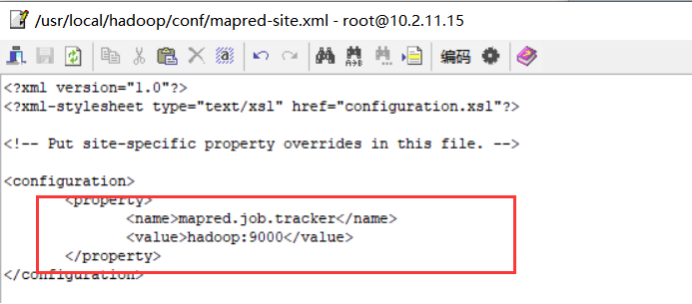
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>hadoop:9000</value>
</property>
</configuration>
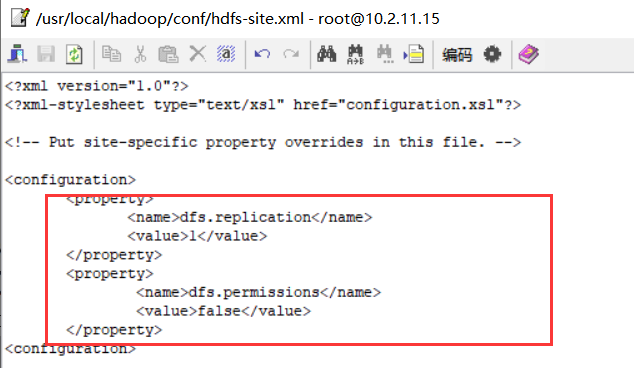
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<configuration>
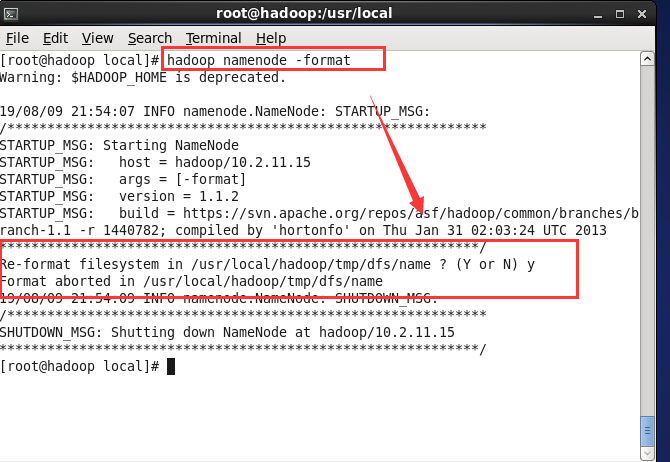
(5) 执行命令 hadoop namenode -format 对hadoop进行格式化
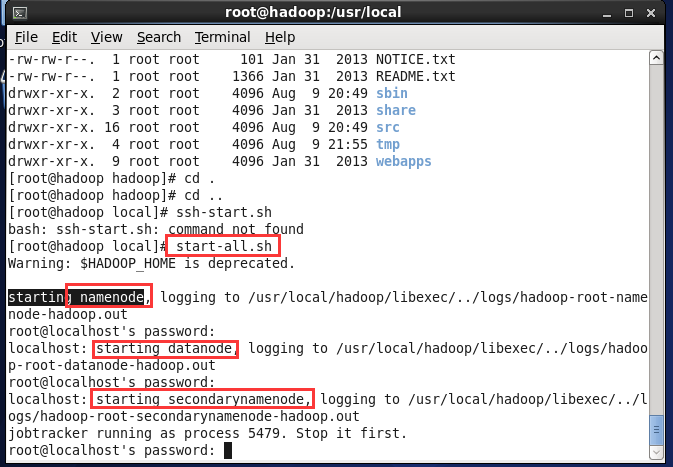
(6) 执行命令 start-all.sh 启动
验证:
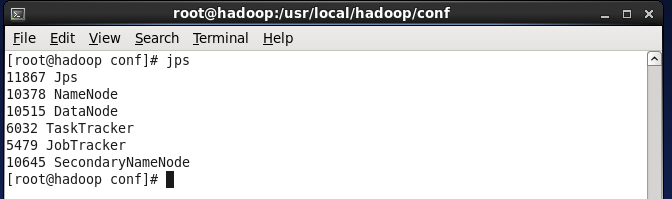
(1) 执行命令jps,发现5个java进程,分别是NameNode , DataNode , SecondaryNameNode, JobTracker, TaskTracker。
(2) 通过浏览器执行
NameNode:http://hadoop:50030
jobtracker:http://hadoop:50070
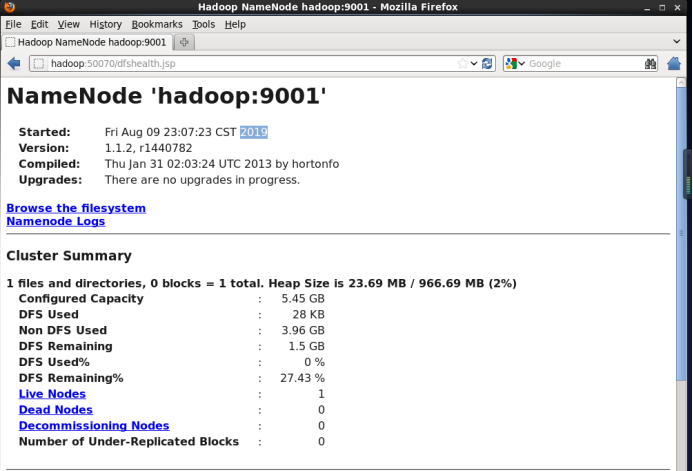
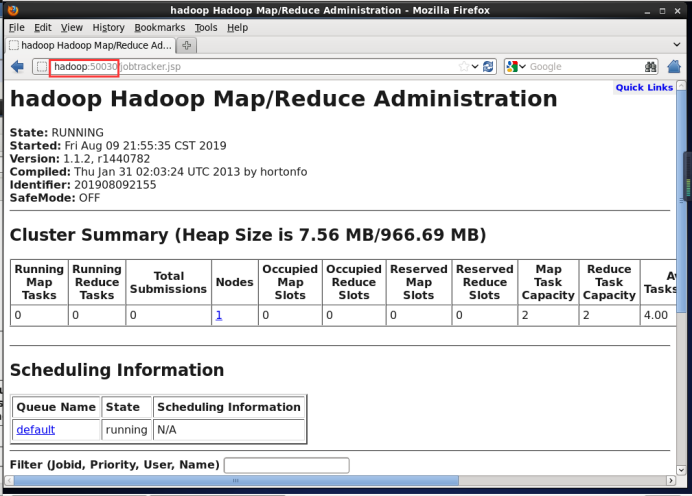
PS:9000和9001 不知道为什么,配置文件的时候这么修改,就能正常配置hadoop
疑问
1、为什么要配置静态IP?
在实际应用中,默认我们使用的是DHCP(动态主机分配协议)来分配地址的,那么ip地址有可能是会变动的。
而我们用Linux来搭建集群学习Hadoop的话,是希望IP固定不变的, 那么这个时候就需要我们配置静态IP。
2、配置ip,可以参考如下博文
https://baijiahao.baidu.com/s?id=1618628054855105015&wfr=spider&for=pc
3.修改root密码,可以参考如下博文
https://www.cnblogs.com/wenrulaogou/p/9409251.html
执行命令:passwd root 修改完成后ctrl+d 进行重启
4.网络采用桥接方式(桥接的网络选择对应实际网络)

centos 6.4-linux环境配置,安装hadoop-1.1.2(hadoop伪分布环境配置)的更多相关文章
- Hadoop之伪分布环境搭建
搭建伪分布环境 上传hadoop2.7.0编译后的包并解压到/zzy目录下 mkdir /zzy 解压 tar -zxvf hadoop.2.7.0.tar.gz -C /zzy 配置hado ...
- (一)Hadoop1.2.1安装——单节点方式和单机伪分布方式
Hadoop1.2.1安装——单节点方式和单机伪分布方式 一. 需求部分 在Linux上安装Hadoop之前,需要先安装两个程序: 1)JDK 1.6(或更高版本).Hadoop是用Java编写的 ...
- 在CentOS/RHEL/Scientific Linux 6下安装 LAMP
LAMP 是服务器系统中开源软件的一个完美组合.它是 Linux .Apache HTTP 服务器.MySQL 数据库.PHP(或者 Perl.Python)的第一个字母的缩写代码.对于很多系统管理员 ...
- CentOS 6.4 linux下编译安装MySQL5.6.14
CentOS 6.4下通过yum安装的MySQL是5.1版的,比较老,所以就想通过源代码安装高版本的5.6.14. 正文: 一:卸载旧版本 使用下面的命令检查是否安装有MySQL Server rpm ...
- Hadoop.2.x_伪分布环境搭建
一. 基本环境搭建 1. 设置主机名.静态IP/DNS.主机映射.windows主机映射(方便ssh访问与IP修改)等 设置主机名: vi /etc/sysconfig/network # 重启系统生 ...
- Hadoop学习笔记1:伪分布式环境搭建
在搭建Hadoop环境之前,请先阅读如下博文,把搭建Hadoop环境之前的准备工作做好,博文如下: 1.CentOS 6.7下安装JDK , 地址: http://blog.csdn.net/yule ...
- hadoop: hbase1.0.1.1 伪分布安装
环境:hadoop 2.6.0 + hbase 1.0.1.1 + mac OS X yosemite 10.10.3 安装步骤: 一.下载解压 到官网 http://hbase.apache.org ...
- hadoop伪分布环境快速搭建
1.首先下载一个完成已经进行简单配置好的镜像文件(hadoop,HBASE,eclipse,jdk环境已经搭建好,tomcat为7.0版本,建议更改为tomcat8.5版本,运行比较稳定). 2安装V ...
- 启动原生Hadoop集群或伪分布环境
一:启动Hadoop 集群或伪分布安装成功之后,通过执行./sbin/start-all.sh启动Hadoop环境 通过jps命令查看当前启动进程是否正确~ [root@neusoft-master ...
随机推荐
- 【故障公告】博客站点再次出现故障,最终回退 .NET 5.0 恢复正常
自从博客系统升级 .NET 5.0 之后遇到的诡异故障(一.二.三.四),今天它又出现了,就在前天刚刚故障之后, 就在昨天 .NET 5.0 正式版刚刚发布之后,出现了. 今天晚上我们在 19:30 ...
- javascript中什么是函数
函数的定义 在javascript中函数是一段可以被执行或调用任意次数的JavasScript代码,在数据类型中属于"function".函数也拥有属性和方法,因此函数也是对象. ...
- haproxy 思考
通过代理服务器在两个TCP接连之间转发数据是一个常见的需求,然后通常部署的时候涉及到(虚拟)服务器.真实服务器.防护设备.涉及到多个ip地址相关联,改动一个IP就需要修改配置. 比如反向服务器部署的时 ...
- linux Netfilterr中扩展match target
Match: netfilter定义了一个通用的match数据结构struct xt_match /* 每个struct xt_match代表一个扩展match,netfilter中各个扩展match ...
- kernel——Makefile, head.S ...
在Makefile中找到的重要信息: (1)连接脚本 通过连接脚本,知道的信息: (1)入口符号 stext (2)入口连接地址 0xC0000000 + 0x00008000 根据入口符号,可以找到 ...
- Python_案例_斐波那契数
方法一: 1 #!/usr/bin/python3 2 3 # Fibonacci series: 斐波纳契数列 4 # 两个元素的总和确定了下一个数 5 a, b = 0, 1 6 while b ...
- CSS属性(字体与文本属性)
1.字体属性 (1)font-family 把要对这个网站要设置的字体都写上,如果这个浏览器支持第一个字体,则会用,如果不支持则会尝试第二个,如果设置的字体系统都不支持则会使用系统默认的字体作为网站的 ...
- FL Studio音频混音教程
FL Studio是一款音乐制作.编曲.混音软件,其内置众多电子合成音色,还支持第三方VST等格式插件.软件操作界面简洁易上手,即使你是零音乐基础小白,通过它也能轻松实现自己音乐梦想,很多人给他起了个 ...
- 教你在CorelDRAW中制作水印
水印是一种数字保护的手段,在图像上添加水印即能证明本人的版权,还能对版权的保护做出贡献.也就是在图片上打上半透明的标记,因其具有透明和阴影的特性,使之不管在较为阴暗或明亮的图片上都能完美使用,嵌入的水 ...
- Calendar类、 System类、 StringBulider类、 包装类
Calendar类 概念 java . util . Calendar 日历类,抽象类,在Date类后出现的,替换掉了很多Date类中的方法.该类将所有的可能用到的时间信息封装为静态成员变量. ...