Databricks 第8篇:把Azure Data Lake Storage Gen2 (ADLS Gen 2)挂载到DBFS
DBFS使用dbutils实现存储服务的装载(mount、挂载),用户可以把Azure Data Lake Storage Gen2和Azure Blob Storage 账户装载到DBFS中。mount是data lake storage和 blob storage的指针,因此数据不会同步到本地。
一,创建Azure Data Lake Storage Gen2
从Azure Portal中搜索Storage Account,开始创建Data Lake V2
1,创建Data Lake V2的详细步骤
Step1:从Basics选项卡中,选择Account Kind为:StorageV2(General purpose v2)
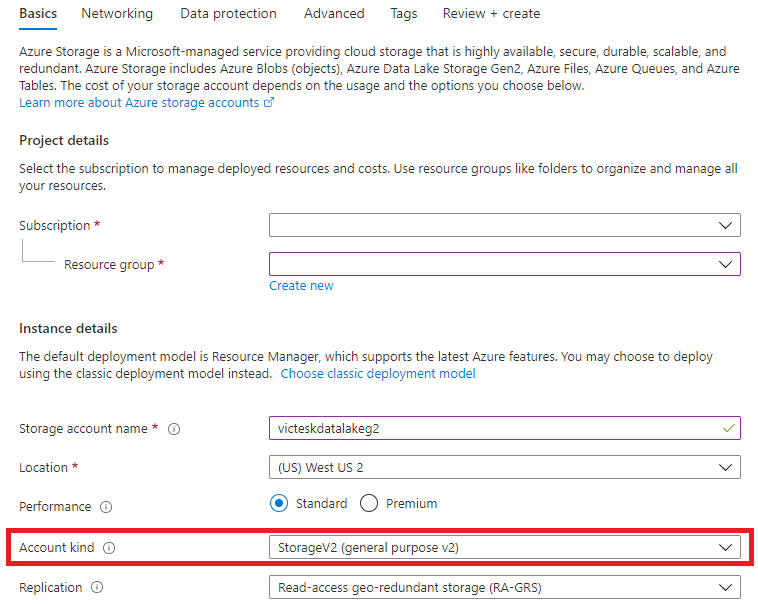
Step2:Networking 使用默认值
Step3:Data Protection 使用默认值
Step4:Advanced选项卡,启用"Hierarchical namespace"
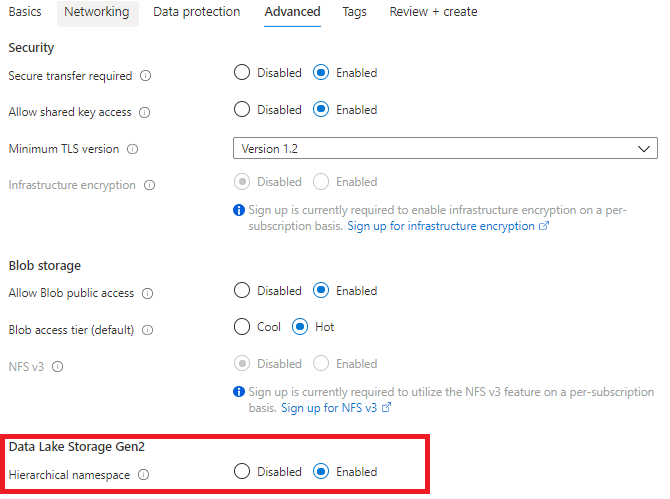
2,为Data Lake V2创建文件系统
进入到Data Lake V2的资源页面中,从“Tools and SDKs”中选择“Storage Explorer”,
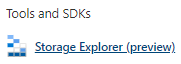
进入到Storage Explorer中,右击CONTAINERS,选择“Create file system”:

二,创建App registraation
为了在ADLS Gen 2和Azure Databricks之间建立连接,需要应用程序连接,如果在Azure Active Directory中将应用程序注册配置为“是”,则非管理员用户可以注册自定义开发的应用程序以在此目录中使用。
1,创建App
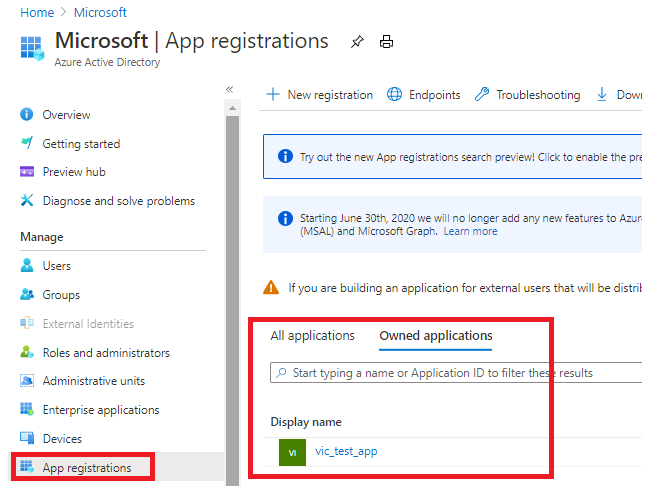
从Azure Portal中搜索“Azure Active Directory”,选择“App registration”,创建vic_test_app

创建完成之后,点击“App registrations”,从“Owned applications”中点击vic_test_app。
2,为该app添加app secret(验证密钥),以访问该app

复制Client Secret 的Value字段,因为执行其他操作之后,这个值将无法再查看到。
3,得到的数据

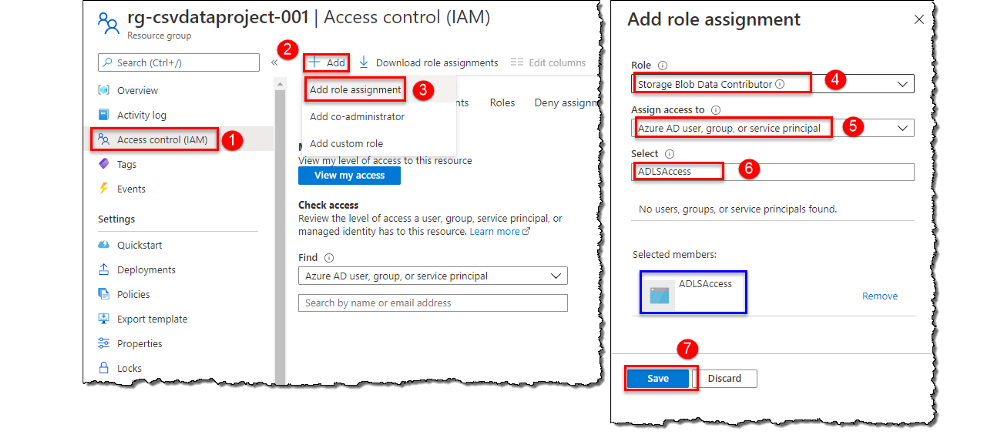
三,把Service Principal的权限授予Data Lake V2账户
我们需要为Service Principal分配访问角色,该Service Principal是在注册App时自动创建,以访问存储账户中的数据。
四,创建Key Vault
Key Vault服务用于安全地存储key、密码、证书等secret,需要把从已注册的app中获取到的密钥存储到Key Vault中。
1:创建Key Vault
在Key Vault创建完成之后,向Key Vault中添加一个Secret,
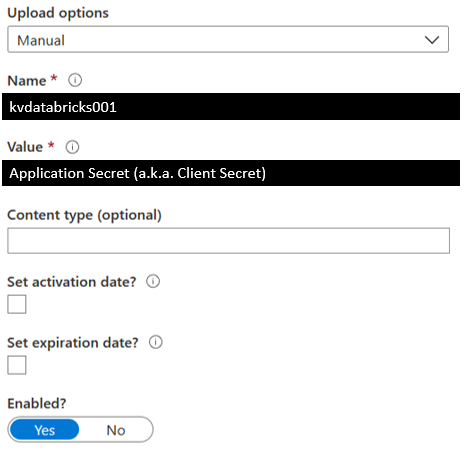
2:保存Secret
定义Secret的Name,把从已注册的app中获取到的Client Secret存储到Secret的Value中。
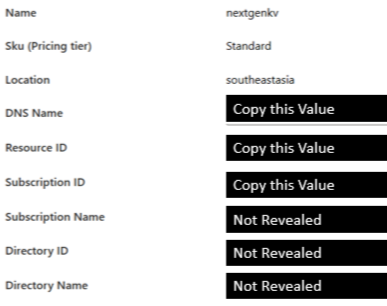
3,从Key Vault得到的数据
从Key Vault的Settings中点击“Properties”
五,创建Azure Key Vault-backed的Secret Scope
使用Secret Scope来管理Secret,Secret Scope是Secret构成的,该Secret是由name来唯一标识的。
Step1,导航到创建Secret Scope的页面
根据Databricks实例,导航到创建Secret Scope的页面,注意该URI是区分大小写的。
https://<databricks-instance>#secrets/createScope
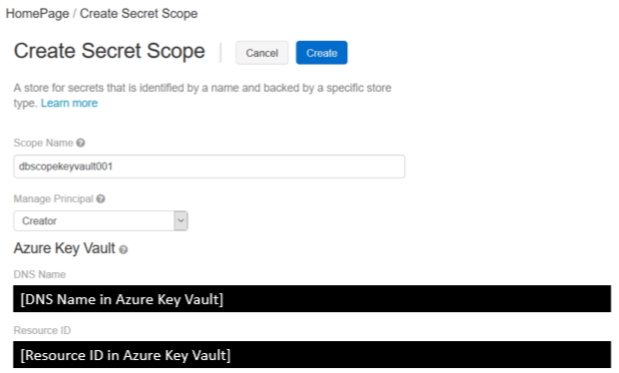
Step2,输入Secret Scope的属性
ScopeName是区分大小写的,并且DNS Name和Resource ID都必须从Key Vault中复制。
六 ,挂载Data Lake Storage Gen2
通过创建 Azure Data Lake Storage Gen2的文件系统,注册App、创建Key Vault、创建Secret Scope,我们完成了把Data Lake Gen2挂载到DBFS的所有准备工作,并获得了以下数据:
- Client ID (a.k.a. Application ID)
- Client Secret (a.k.a. Application Secret)
- Directory ID (a.k.a Tenant ID)
- Databricks Secret Scope Name
- Key Name for Service Credentials (from Azure Key Vault, it is the secret's name)
- File System Name
- Storage Account Name
- Mount Name
Databricks提供了挂载命令:dbutils.mount(),通过该命令,我们可以把Azure Data Lake Storage Gen2挂载到DBFS中。挂载操作是一次性的操作,一旦挂载操作完成,就可以把远程的Data Lake Gen2的file system当作本地文件来使用。
1,挂载Azure Data Lake Storage Gen2
使用服务主体(Service Principal)和OAuth 2.0进行身份验证,把Azure Data Lake Storage Gen2帐户装载到DBFS,该装载点(mount pointer)是数据湖存储的指针,数据不需要同步到本地,但是只要远程文件系统中的数据有更新,我们就能获得数据的更新。
挂载Data Lake Storage Gen2文件系统,目前只支持OAuth 2.0 Credential:
######################################################################################
# Set the configurations. Here's what you need:
## 1.) Client ID (a.k.a Application ID)
## 2.) Client Secret (a.k.a. Application Secret)
## 3.) Directory ID
## 4.) File System Name
## 5.) Storage Account Name
## 6.) Mount Name
######################################################################################
configs = {"fs.azure.account.auth.type": "OAuth",
"fs.azure.account.oauth.provider.type": "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider",
"fs.azure.account.oauth2.client.id": "<client-id>",
"fs.azure.account.oauth2.client.secret": dbutils.secrets.get(scope = "<scope-name>", key = "<key-name-for-service-credential>"),
"fs.azure.account.oauth2.client.endpoint": "https://login.microsoftonline.com/<directory-id>/oauth2/token"} ######################################################################################
# Optionally, you can add <directory-name> to the source URI of your mount point.
######################################################################################
dbutils.fs.mount(
source = "abfss://<file-system-name>@<storage-account-name>.dfs.core.windows.net/",
mount_point = "/mnt/<mount-name>",
extra_configs = configs)
参数注释:
- <Client-id>:App ID
- <scope-name>:Secret Scope的名称
- <key-name-for-service-credential>:Azure Key Vault
- <directory-id>:tenant Id
<mount-name>:是DBFS path,表示Data Lake Store或其中的一个Folder在DBFS中装载的位置dbutils.secrets.get(scope="<scope-name>",key="<service-credential-key-name>"):从Secret Scope中的Secret中获取服务凭证- <file-system-name>:文件系统的名称
- <storage-account-name>:存储账户的名称
2,访问挂载点
访问挂载点中的文件,可以通过pyspark.sql来访问:
df = spark.read.text("/mnt/%s/...." % <mount-name>)
df = spark.read.text("dbfs:/mnt/<mount-name>/....")
或者通过SQL命令来访问:
%sql
select *
from csv.`/mnt/mount_datalakeg2/stword.csv`
3,刷新挂载点
dbutils.fs.refreshMounts()
4,卸载挂载点:
dbutils.fs.unmount("/mnt/<mount-name>")
参考文档:
Mounting & accessing ADLS Gen2 in Azure Databricks using Service Principal and Secret Scopes
Mount an ADLS Gen 2 to Databricks File System Using a Service Principal and OAuth 2.0 (Ep. 5)
Databricks 第8篇:把Azure Data Lake Storage Gen2 (ADLS Gen 2)挂载到DBFS的更多相关文章
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(中)
引言 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 因此数据湖相关服务 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2实战体验(下)
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- 构建企业级数据湖?Azure Data Lake Storage Gen2不容错过(上)
背景 相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 数据湖的核心功能, ...
- Azure Data Lake Storage Gen2实战体验
相较传统的重量级OLAP数据仓库,“数据湖”以其数据体量大.综合成本低.支持非结构化数据.查询灵活多变等特点,受到越来越多企业的青睐,逐渐成为了现代数据平台的核心和架构范式. 作为微软Azure上最新 ...
- 【Azure 存储服务】Hadoop集群中使用ADLS(Azure Data Lake Storage)过程中遇见执行PUT操作报错
问题描述 在Hadoop集中中,使用ADLS 作为数据源,在执行PUT操作(上传文件到ADLS中),遇见 400错误[put: Operation failed: "An HTTP head ...
- Azure Data Lake(一) 在NET Core 控制台中操作 Data Lake Storage
一,引言 Azure Data Lake Storage Gen2 是一组专用于大数据分析的功能,基于 Azure Blob Storage 构建的.Data Lake Storage Gen2 包含 ...
- ADF 第一篇:Azure Data Factory介绍
Azure Data Factory(简写 ADF)是Azure的云ETL服务,简单的说,就是云上的SSIS.ADF是基于云的ETL,用于数据集成和数据转换,不需要代码,直接通过UI(code-fre ...
- Big Data Solution in Azure: Azure Data Lake
https://blogs.technet.microsoft.com/dataplatforminsider/2015/09/28/microsoft-expands-azure-data-lake ...
- data lake 新式数据仓库
Data lake - Wikipedia https://en.wikipedia.org/wiki/Data_lake 数据湖 Azure Data Lake Storage Gen2 预览版简介 ...
随机推荐
- React中JSX的理解
React中JSX的理解 JSX是快速生成react元素的一种语法,实际是React.createElement(component, props, ...children)的语法糖,同时JSX也是J ...
- NameVirtualHost *:80 has no VirtualHosts
服务器会包含所有的 .conf 后缀的文件 当出现如标题所示的错误的时候,检查所有 .conf 文件,是否端口占用,或者重复命令行的情况
- 精尽Spring MVC源码分析 - HandlerExceptionResolver 组件
该系列文档是本人在学习 Spring MVC 的源码过程中总结下来的,可能对读者不太友好,请结合我的源码注释 Spring MVC 源码分析 GitHub 地址 进行阅读 Spring 版本:5.2. ...
- Mysql技术内幕之InnoDB锁探究
自7月份换工作以来,期间一直在学习MySQL的相关知识,听了一些视频课,但是一直好奇那些讲师的知识是从哪里学习的.于是想着从书籍中找答案.毕竟一直 看视频也不是办法,不能形成自己的知识.于是想着看书汲 ...
- Linux下源码安装方式安装MySQL
1.下载安装包:https://downloads.mysql.com/archives/community/ 2.安装开发工具和安装包 因为要把源码编译成二进制数据,所以必须要有编译器和解释器 g ...
- Java学习_注解
使用注解 注解是放在Java源码的类.方法.字段.参数前的一种特殊"注释". 1 // this is a component: 2 @Resource("hello&q ...
- Java中常见的json序列化类库 - Jackson
Jackson 介绍 Jackson框架是基于Java平台的一套数据处理工具,被称为"最好的Java Json解析器". Jackson框架包含了3个核心库:streaming,d ...
- Java学习日报7.30
package dog;import java.util.*;public class Dog { private String dogName; private String dogColor; p ...
- Hive数据导入Hbase
方案一:Hive关联HBase表方式 适用场景:数据量不大4T以下(走hbase的api导入数据) 一.hbase表不存在的情况 创建hive表hive_hbase_table映射hbase表hbas ...
- Logstash学习之路(五)使用Logstash抽取mysql数据到kakfa
一.Logstash对接kafka测通 说明: 由于我这里kafka是伪分布式,且kafka在伪分布式下,已经集成了zookeeper. 1.先将zk启动,如果是在伪分布式下,kafka已经集成了zk ...