python 爬虫 汽车之家车辆参数反爬
水平有限,仅供参考。
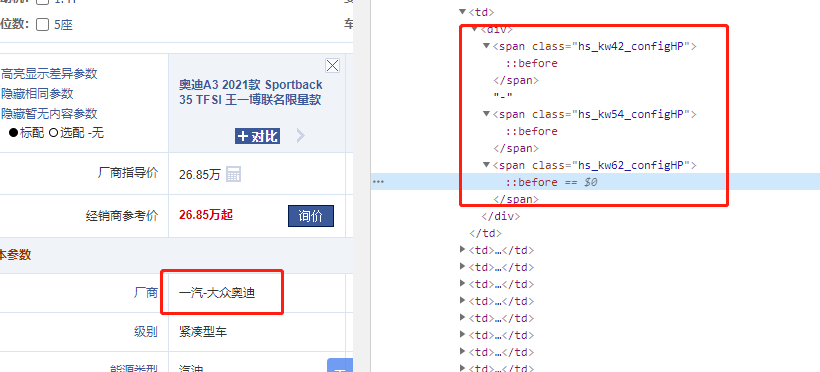
如图所示,汽车之家的车辆详情里的数据做了反爬对策,数据被CSS伪类替换。
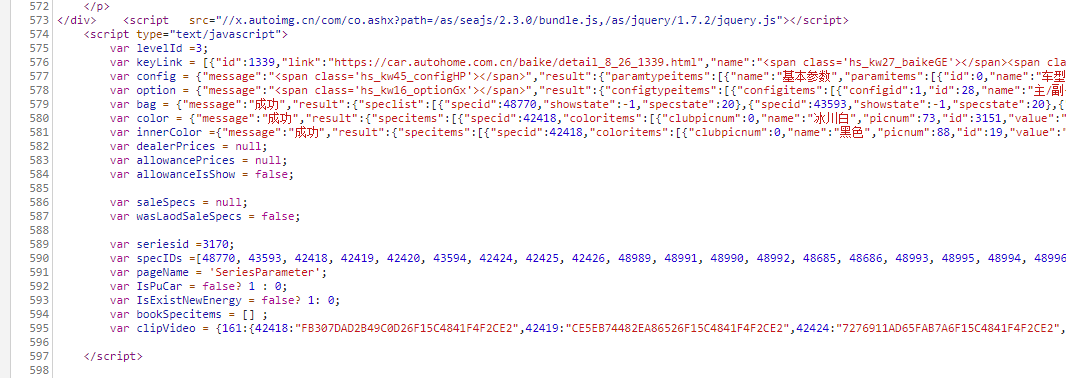
观察 Sources 发现数据就在当前页面。

发现若干条进行CSS替换的js
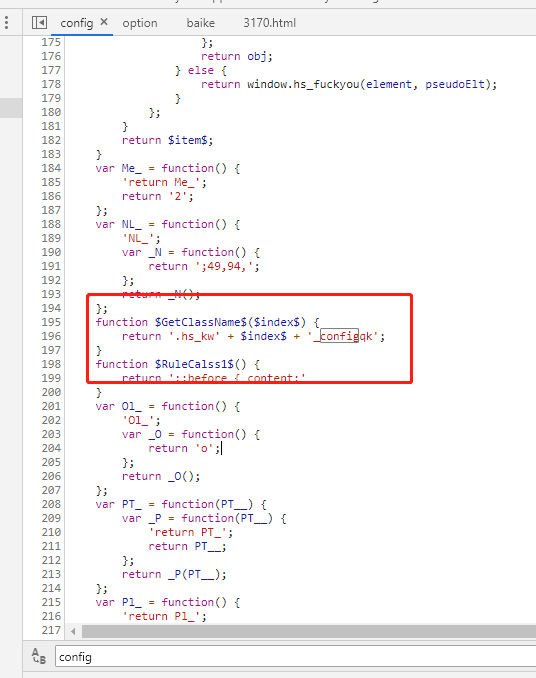
继续深入此JS
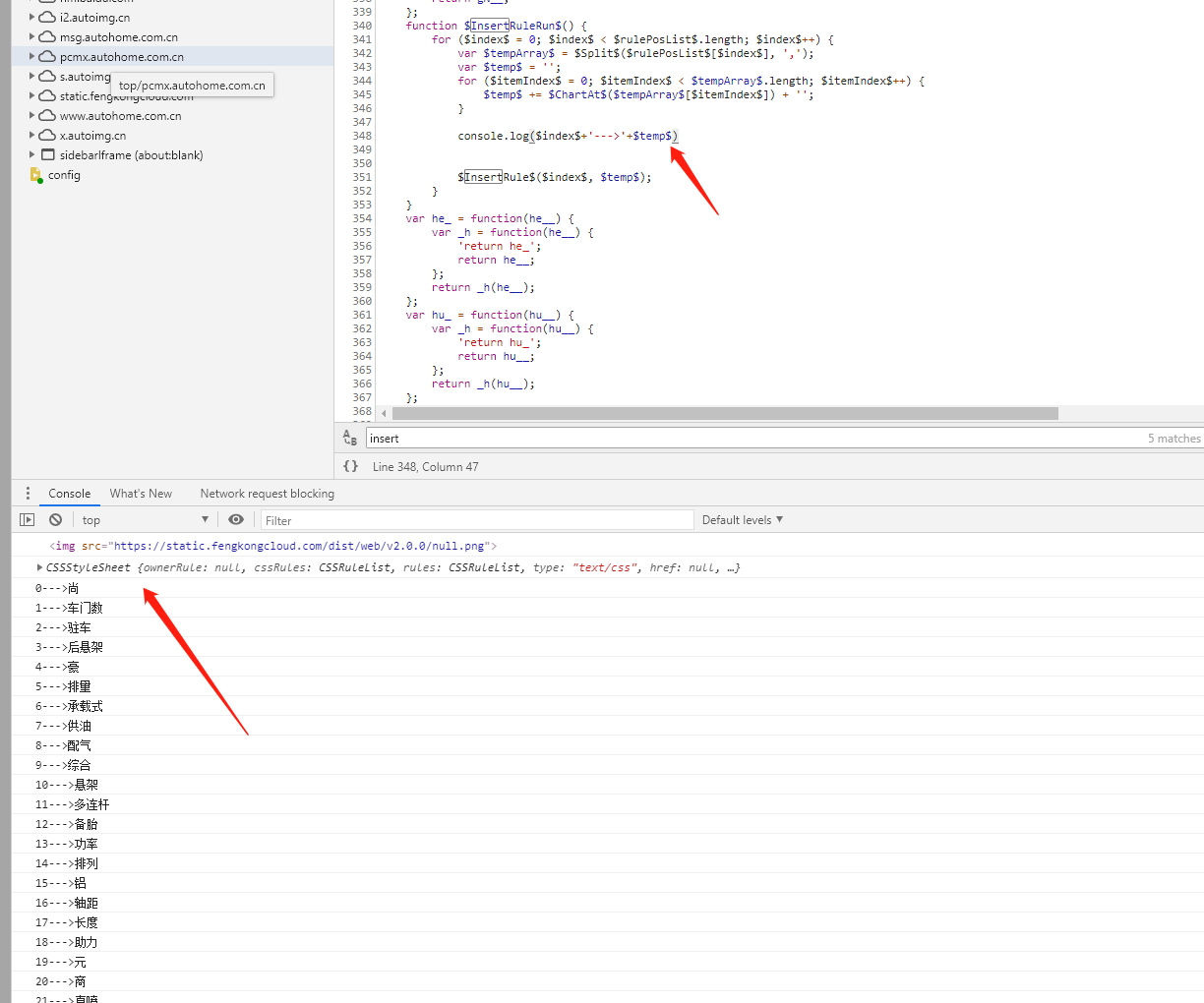
知道了数据与规则,剩下的交给PYTHON。
def repliceStr(browser,textJs,Js):
_config_pos=textJs.find("return '.")
JsSplit=textJs[_config_pos:_config_pos+70]
ClassHead=re.search("[A-Za-z]{2}_[A-Za-z]{2}",JsSplit,re.S).group(0)
ClassFoot=re.search("_[A-Za-z]+';",JsSplit,re.S).group(0)[:-2]
pos=textJs.find("$InsertRule$($index$, $temp$);")
top=textJs[0:pos]
bottom=textJs[pos:]
JsBack = browser.execute_script('''
var suc={};
'''+top+' suc[$index$]=$temp$; '+bottom+'''
return suc
''')
for cj in range(0,len(JsBack)):
cjclass=ClassHead+str(cj)+ClassFoot
Js=re.sub("<span class='"+cjclass+"'></span>",JsBack[str(cj)], Js)
return Js
#获取详情页的数据
def getDetail(base_url):
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get(base_url)
#在这里进行文件替换,反爬页面
#keyLink = re.search("var keyLink = (.*?)}];", browser.page_source, re.S)
config = re.search("var config = (.*?)};", browser.page_source, re.S)
option = re.search("var option = (.*?)};", browser.page_source, re.S)
option=option.group(0)[13:-1]
config=config.group(0)[13:-1]
script = re.findall("<script>(.*?)</script>", browser.page_source,re.S)
for i in range(0,len(script)):
if re.search("_config",script[i],re.S) :
config=repliceStr(browser,script[i],config)
if re.search("_option",script[i],re.S) :
option=repliceStr(browser,script[i],option)
option=demjson.decode(option);
config=demjson.decode(config);
carr={}
for item in config['result']['paramtypeitems'] :
bigTitle=item['name']
carr[bigTitle]={}
index=0
for ni in item['paramitems']:
cate =ni['name']
value=ni['valueitems'][0]['value']
carr[bigTitle][index]=[cate,value]
index=index+1
for item in option['result']['configtypeitems'] :
bigTitle=item['name']
carr[bigTitle]={}
index=0
for ni in item['configitems']:
cate =ni['name']
value=ni['valueitems'][0]['value']
carr[bigTitle][index]=[cate,value]
index=index+1
time.sleep(10)
return carr
刚接触PYTHON,还在学习中,找不到更好的解法。
python 爬虫 汽车之家车辆参数反爬的更多相关文章
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- Python爬虫入门教程 64-100 反爬教科书级别的网站-汽车之家,字体反爬之二
说说这个网站 汽车之家,反爬神一般的存在,字体反爬的鼻祖网站,这个网站的开发团队,一定擅长前端吧,2019年4月19日开始写这篇博客,不保证这个代码可以存活到月底,希望后来爬虫coder,继续和汽车之 ...
- python爬虫——汽车之家数据
相信很多买车的朋友,首先会在网上查资料,对比车型价格等,首选就是"汽车之家",于是,今天我就给大家扒一扒汽车之家的数据: 一.汽车价格: 首先获取的数据是各款汽车名称.价格范围以及 ...
- nodejs爬虫——汽车之家所有车型数据
应用介绍 项目Github地址:https://github.com/iNuanfeng/node-spider/ nodejs爬虫,爬取汽车之家(http://www.autohome.com.cn ...
- python爬虫---CrawlSpider实现的全站数据的爬取,分布式,增量式,所有的反爬机制
CrawlSpider实现的全站数据的爬取 新建一个工程 cd 工程 创建爬虫文件:scrapy genspider -t crawl spiderName www.xxx.com 连接提取器Link ...
- Scrapy框架爬虫初探——中关村在线手机参数数据爬取
关于Scrapy如何安装部署的文章已经相当多了,但是网上实战的例子还不是很多,近来正好在学习该爬虫框架,就简单写了个Spider Demo来实践.作为硬件数码控,我选择了经常光顾的中关村在线的手机页面 ...
- Python爬虫:用BeautifulSoup进行NBA数据爬取
爬虫主要就是要过滤掉网页中没用的信息.抓取网页中实用的信息 一般的爬虫架构为: 在python爬虫之前先要对网页的结构知识有一定的了解.如网页的标签,网页的语言等知识,推荐去W3School: W3s ...
- Python爬虫入门教程 2-100 妹子图网站爬取
妹子图网站爬取---前言 从今天开始就要撸起袖子,直接写Python爬虫了,学习语言最好的办法就是有目的的进行,所以,接下来我将用10+篇的博客,写爬图片这一件事情.希望可以做好. 为了写好爬虫,我们 ...
- python爬虫实战(六)--------新浪微博(爬取微博帐号所发内容,不爬取历史内容)
相关代码已经修改调试成功----2017-4-13 详情代码请移步我的github:https://github.com/pujinxiao/sina_spider 一.说明 1.目标网址:新浪微博 ...
随机推荐
- cenos7 u disk install
分类: 其他 2014-08-24 13:53 3406人阅读 评论(0) 收藏 举报 CentOS安装教程操作系统 ...
- Spark集群和任务执行
[前言:承接<Spark通识>篇] Spark集群组件 Spark是典型的Master/Slave架构,集群主要包括以下4个组件: Driver:Spark框架中的驱动器,运行用户编写Ap ...
- Cuda常用概念及注意点
线程的索引计算 只需要知并行线程的初始索引,以及如何确定递增的量值,我们希望每个并行线程从不同的索引开始,因此就需要对线程索引和线程块索引进行线性化,每个线程的其实索引按照以下公式来计算: int t ...
- from `float` to `np.floating` is deprecated
运行tensorflow测试程序时,出现:FutureWarning: Conversion of the second argument of issubdtype from `float` to ...
- 剑指Offer-Python(6-10)
6.旋转数组的最小数字 class Solution: def minNumberInRotateArray(self, rotateArray): l = len(rotateArray) if l ...
- 腾讯云对象存储COS新品发布——智能分层存储,自动优化您的存储成本
近日,腾讯云正式发布对象存储新品--智能分层存储,能够根据用户数据的访问模式,自动地转换数据的冷热层级,为用户提供与标准存储一致的低延迟和高吞吐的产品体验,同时具有更低的存储成本. 熟悉数据存储的用户 ...
- solr全文检索学习
序言: 前面我们说了全局检索Lucene,但是我们发现Lucene在使用上还是有些不方便的,例如想要看索引的内容时,就必须自己调api去查,再例如一些添加文档,需要写的代码还是比较多的 另外我们之前说 ...
- ubutun 服务器配置jupyter notebook
由于能力有限,学习机器学习时候发现,自己的电脑带不起来,所以想起了服务器,选择的是阿里的ubutun服务器,所以希望能够 使用jupyter notebook,看到网上一大片,配置和好久,才成功,在这 ...
- binary hacks读数笔记(装载)
1.地址空间 在linux系统中,每个进程拥有自己独立的虚拟地址空间,这个虚拟地址空间的大小是由计算机硬件决定的,具体地说,是由CPU的位数决定的.比如,32位硬件平台决定的虚拟地址空间大小:0--2 ...
- docker搭建渗透环境并进行渗透测试
目录 docker简介 docker的安装 docker.centos7.windows10(博主宿主机系统)之间相互通信 -docker容器中下载weblogic12c(可以略过不看) docker ...