SSD训练网络参数计算
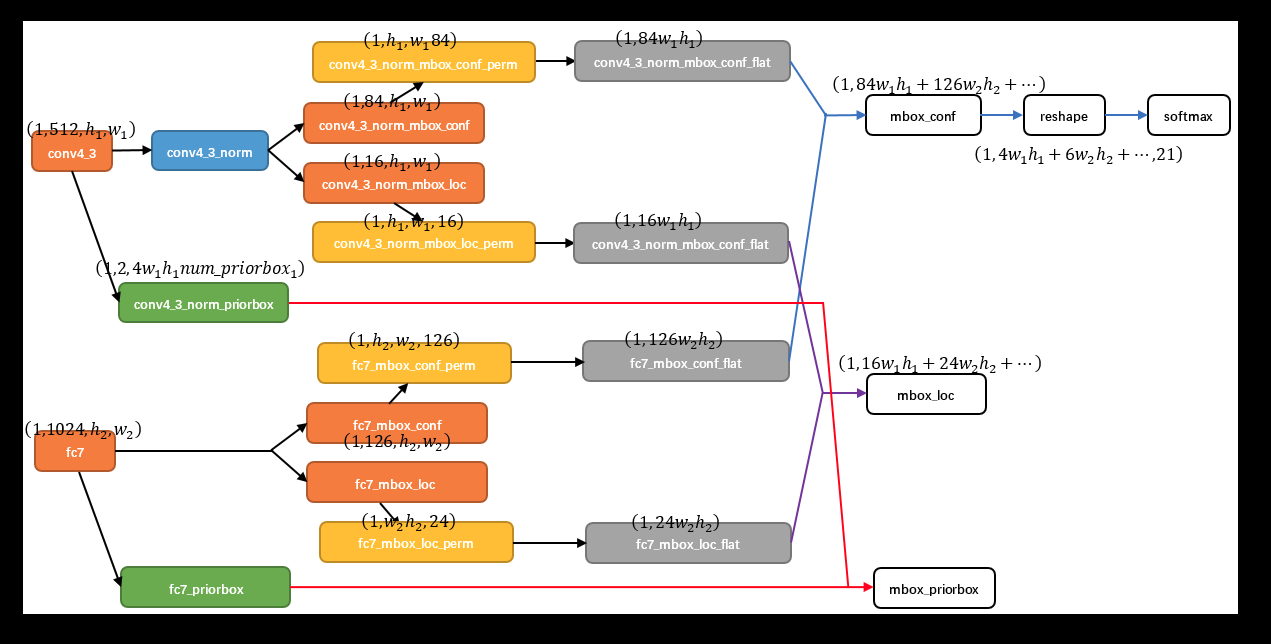
一个预测层的网络结构如下所示:
可以看到,是由三个分支组成的,分别是"PriorBox"层,以及conf、loc的预测层,其中,conf与loc的预测层的参数是由PriorBox的参数计算得到的,具体计算公式如下:
min_size与max_size分别对应一个尺度的预测框(有几个就对应几个预测框),in_size只管自己的预测,而max_size是与aspect_ratio联系在一起的;
filp参数是对应aspect_ratio的预测框*2,以几个max_size,再乘以几;最终得到结果为A
conf、loc的参数是在A的基础上再乘以类别数(加背景),以及4
如下,是需要预测两类的其中一个尺度的网络参数;
如上算出的是,每个格子需要预测的conf以及loc的个数;
每个预测层有H*W个格子,因此,总共预测的loc以及conf的个数是需要乘以H*W的;
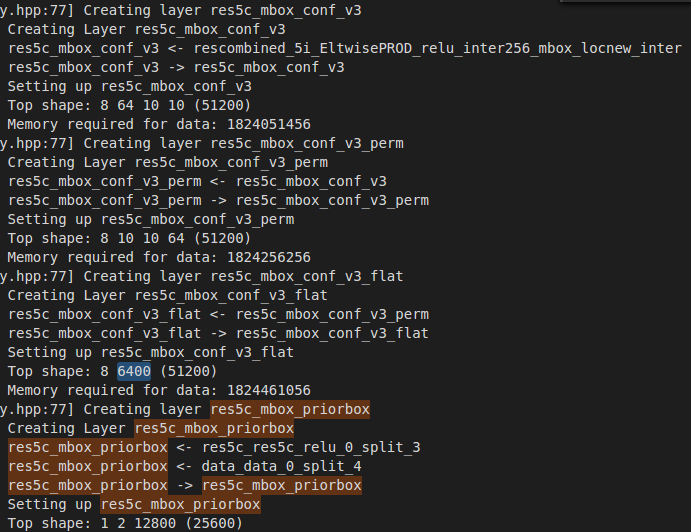
如下是某一个层的例子(转自:http://www.360doc.com/content/17/1013/16/42392246_694639090.shtml)

注意最后这里的num_priorbox的值与前面的并不一样,这里是每个预测层所有的输出框的个数:

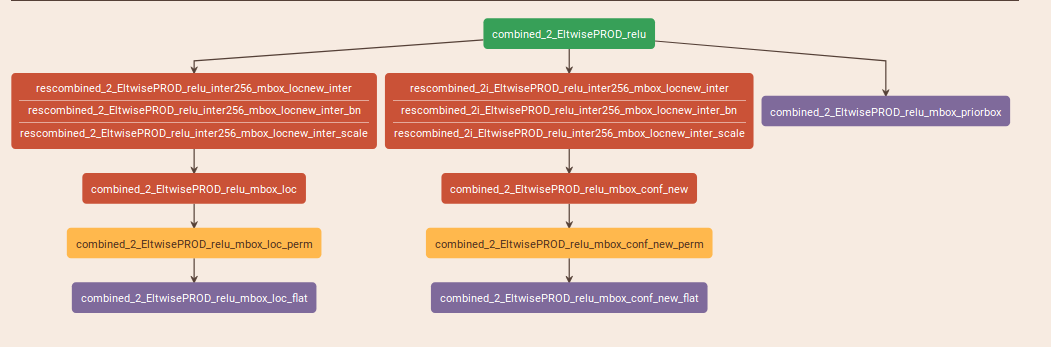
layer {
name: "combined_2_EltwisePROD_relu"
type: "ReLU"
bottom: "combined_2_EltwisePROD"
top: "combined_2_EltwisePROD_relu"
}
###########################################
###################################################################
layer {
name: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
type: "Convolution"
bottom: "combined_2_EltwisePROD_relu"
top: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
stride:
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter_bn"
type: "BatchNorm"
bottom: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
batch_norm_param {
moving_average_fraction: 0.999
eps: 0.001
}
}
layer {
name: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter_scale"
type: "Scale"
bottom: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
type: "Convolution"
bottom: "combined_2_EltwisePROD_relu"
top: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
convolution_param {
num_output:
bias_term: false
pad:
kernel_size:
stride:
weight_filler {
type: "gaussian"
std: 0.01
}
}
}
layer {
name: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter_bn"
type: "BatchNorm"
bottom: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
batch_norm_param {
moving_average_fraction: 0.999
eps: 0.001
}
}
layer {
name: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter_scale"
type: "Scale"
bottom: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
scale_param {
filler {
type: "constant"
value: 1.0
}
bias_term: true
bias_filler {
type: "constant"
value: 0.0
}
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_loc"
type: "Convolution"
bottom: "rescombined_2_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "combined_2_EltwisePROD_relu_mbox_loc"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
engine: CAFFE
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value:
}
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_loc_perm"
type: "Permute"
bottom: "combined_2_EltwisePROD_relu_mbox_loc"
top: "combined_2_EltwisePROD_relu_mbox_loc_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_loc_flat"
type: "Flatten"
bottom: "combined_2_EltwisePROD_relu_mbox_loc_perm"
top: "combined_2_EltwisePROD_relu_mbox_loc_flat"
flatten_param {
axis:
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_conf_new"
type: "Convolution"
bottom: "rescombined_2i_EltwisePROD_relu_inter256_mbox_locnew_inter"
top: "combined_2_EltwisePROD_relu_mbox_conf_new"
param {
lr_mult:
decay_mult:
}
param {
lr_mult:
decay_mult:
}
convolution_param {
engine: CAFFE
num_output:
pad:
kernel_size:
stride:
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value:
}
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_conf_new_perm"
type: "Permute"
bottom: "combined_2_EltwisePROD_relu_mbox_conf_new"
top: "combined_2_EltwisePROD_relu_mbox_conf_new_perm"
permute_param {
order:
order:
order:
order:
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_conf_new_flat"
type: "Flatten"
bottom: "combined_2_EltwisePROD_relu_mbox_conf_new_perm"
top: "combined_2_EltwisePROD_relu_mbox_conf_new_flat"
flatten_param {
axis:
}
}
layer {
name: "combined_2_EltwisePROD_relu_mbox_priorbox"
type: "PriorBox"
bottom: "combined_2_EltwisePROD_relu"
bottom: "data"
top: "combined_2_EltwisePROD_relu_mbox_priorbox"
prior_box_param {
min_size: 12.0
min_size: 6.0
max_size: 30.0
max_size: 20.0
aspect_ratio:
aspect_ratio: 2.5
aspect_ratio:
flip: true
clip: false
variance: 0.1
variance: 0.1
variance: 0.2
variance: 0.2
step:
offset: 0.5
}
}
SSD训练网络参数计算的更多相关文章
- LeNet-5网络结构及训练参数计算
经典神经网络诞生记: 1.LeNet,1998年 2.AlexNet,2012年 3.ZF-net,2013年 4.GoogleNet,2014年 5.VGG,2014年 6.ResNet,201 ...
- 『计算机视觉』Mask-RCNN_训练网络其二:train网络结构&损失函数
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- CNN网络参数
卷积神经网络 LeNet-5各层参数详解 LeNet论文阅读:LeNet结构以及参数个数计算 LeNet-5共有7层,不包含输入,每层都包含可训练参数:每个层有多个Feature Map,每个 ...
- pytorch和tensorflow的爱恨情仇之定义可训练的参数
pytorch和tensorflow的爱恨情仇之基本数据类型 pytorch和tensorflow的爱恨情仇之张量 pytorch版本:1.6.0 tensorflow版本:1.15.0 之前我们就已 ...
- 『计算机视觉』Mask-RCNN_训练网络其三:训练Model
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 『计算机视觉』Mask-RCNN_训练网络其一:数据集与Dataset类
Github地址:Mask_RCNN 『计算机视觉』Mask-RCNN_论文学习 『计算机视觉』Mask-RCNN_项目文档翻译 『计算机视觉』Mask-RCNN_推断网络其一:总览 『计算机视觉』M ...
- 卷积神经网络(CNN)张量(图像)的尺寸和参数计算(深度学习)
分享一些公式计算张量(图像)的尺寸,以及卷积神经网络(CNN)中层参数的计算. 以AlexNet网络为例,以下是该网络的参数结构图. AlexNet网络的层结构如下: 1.Input: 图 ...
- 关于LeNet-5卷积神经网络 S2层与C3层连接的参数计算的思考???
https://blog.csdn.net/saw009/article/details/80590245 关于LeNet-5卷积神经网络 S2层与C3层连接的参数计算的思考??? 首先图1是LeNe ...
- caffe 网络参数设置
weight_decay防止过拟合的参数,使用方式: 样本越多,该值越小 模型参数越多,该值越大 一般建议值: weight_decay: 0.0005 lr_mult, decay_mult 关于偏 ...
随机推荐
- 3.AOP中的IntroductionAdvisor
上篇中的自定义Advisor是实现的AbstractPointcutAdvisor,Advisor其实还有一个接口级别的IntroductionAdvisor ...
- UmUtils得到友盟的渠道号
import android.content.Context; import android.content.pm.ApplicationInfo; import android.content.pm ...
- php如何开启gd2扩展
extension=php_gd2.dll 找到php的配置文件php.ini,搜索extension=php_gd2.dll,去掉前面的分号即可:如果没有直接添加这种情况适合于windows系统和编 ...
- 004-tomcat优化-Catalina中JVM优化、Connector优化、NIO化
一.服务端web层 涉及内容Nginx.Varnish.JVM.Web服务器[Tomcat.Web应用开发(Filter.spring mvc.css.js.jsp)] 1.1.基本优化思路 1.尽量 ...
- [mybatis]传值和返回结果
一.传值:parameterType的形式:可以传递一个类,也可以是一个map <update id="updateCategory" parameterType=" ...
- 如何在 CentOS 里下载 RPM 包及其所有依赖包
方法一.利用 Downloadonly 插件下载 RPM 软件包及其所有依赖包 默认情况下,这个命令将会下载并把软件包保存到 /var/cache/yum/ 的 rhel-{arch}-channel ...
- 一次神奇的JVM调优
老张接个新项目,项目可是不小,好多模块.使用Intellij import new project, 结果卡在writing class中,而且mac的风扇一直转,像是要变成直升机起飞. 等啊等,in ...
- phpfpm开启pm.status_path配置,查看fpm状态参数
php-fpm配置 pm.status_path = /phpfpm_status nginx配置 server { root /data/www; listen 80; serve ...
- 测试ssh转发
端口转发提供: 1.加密 SSH Client 端至 SSH Server 端之间的通讯数据. 2.突破防火墙的限制完成一些之前无法建立的 TCP 连接. 但是只能转发tcp连接,想要转发UDP,需要 ...
- Y2K Accounting Bug POJ2586
Description Accounting for Computer Machinists (ACM) has sufferred from the Y2K bug and lost some vi ...