希尔排序——C语言
希尔排序
希尔排序是插入排序的一种,又称“缩小增量排序”,希尔排序是直接插入排序算法的一种更高效的改进版本,关于插入排序可以看下这篇随笔:插入排序——C语言


(图片来源:https://www.cnblogs.com/fivestudy/p/10212306.html)
1、希尔排序的基本思想:
设待排序元素序列有n个元素,首先取一个整数increment(小于n)作为间隔将全部元素分为n/increment个子序列,所有距离为increment的元素放在同一个子序列中,在每一个子序列中分别实行直接插入排序,然后缩小间隔increment,重复上述子序列划分和排序工作,直到最后取increment=1,将所有元素放在同一个子序列中排序为止,该方法实质上是一种分组插入方法
{1,2,4,8,...}这种序列并不是很好的增量序列,使用这个增量序列的时间复杂度(最坏情形)是O(n^2)
Hibbard提出了另一个增量序列{1,3,7,...,2^k-1},这种序列的时间复杂度(最坏情形)为O(n^1.5)
Sedgewick提出了几种增量序列,其最坏情形运行时间为O(n^1.3),其中最好的一个序列是{1,5,19,41,109,...}
3、代码实现
/* 希尔排序*/
int num[] = {, , , , };
int cur;
int i, j;
int length = sizeof(num)/sizeof(num[]);
int incre; incre = length / ; while (incre >= )
{
for (i = incre; i < length; i++)
{
cur = num[i]; //待排序元素
for (j = i - incre; j >= && num[j] > cur; j = j - incre)
{
num[j + incre] = num[j]; //元素向后移动
}
num[j + incre] = cur; //插入待排序元素
}
incre = incre / ; //增量减半
}
while里面的代码其实和插入排序的代码没多大区别,就是在两个for循环外面套了一个while再修改了一下内部的for循环,可以对照看一下下面列出来的插入排序的for循环
for (i = ; i < length; i++)
{
cur = num[i]; //待排序元素
for (j = i - ; j >= && num[j] > cur; j--)
{
num[j + ] = num[j];
}
num[j + ] = cur;
}
4、排序过程(以5,7,8,3,1,2,4,6为例)


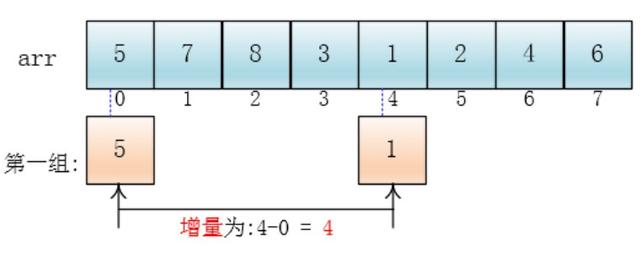
每个分组进行插入排序后,各个分组就变成了有序的了(整体不一定有序)

此时,整个数组变的部分有序了(有序程度可能不是很高)
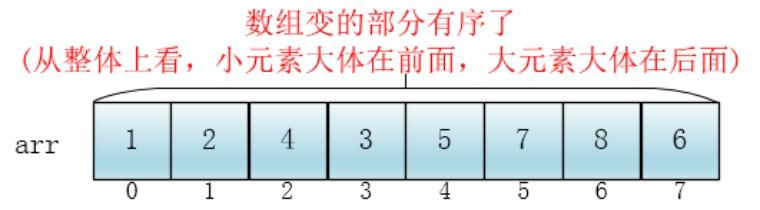
然后缩小增量为上个增量的一半:2,继续划分分组,此时,每个分组元素个数多了,但是,数组变的部分有序了,插入排序效率同样比高
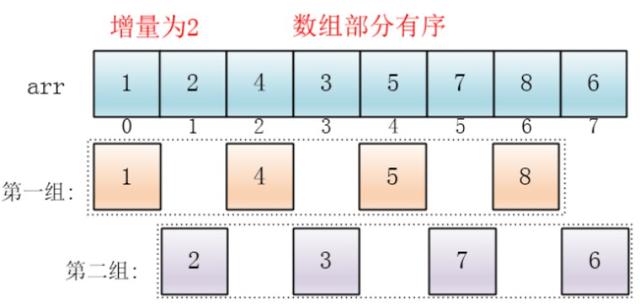
同理对每个分组进行排序(插入排序),使其每个分组各自有序
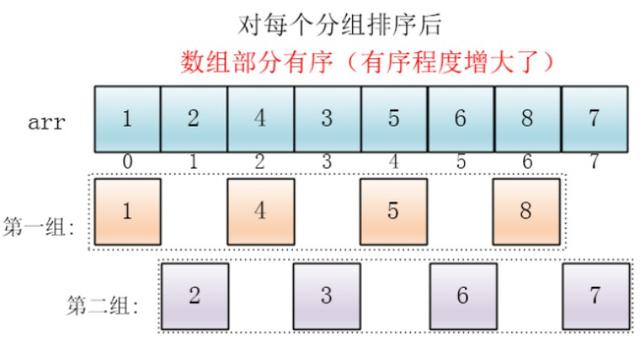
最后设置增量为上一个增量的一半:1,则整个数组被分为一组,此时,整个数组已经接近有序了,插入排序效率高
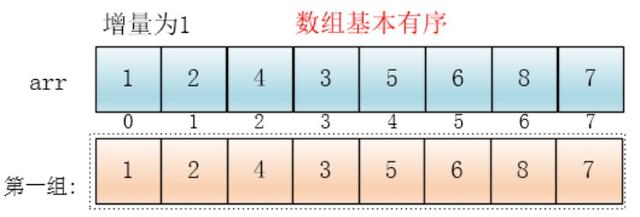
同理,对这仅有的一组数据进行排序,排序完成
(图片来源:https://blog.csdn.net/qq_39207948/article/details/80006224)
参考链接:
希尔排序——C语言的更多相关文章
- [数据结构] 希尔排序 C语言程序
//由小到大 //希尔排序 void shellSort( long int array[], int length) { int i; int j; int k; int gap; //gap是分组 ...
- 希尔排序(Shell's Sort)的C语言实现
原创文章,转载请注明来自钢铁侠Mac博客http://www.cnblogs.com/gangtiexia 希尔排序(Shell's Sort)又称“缩小增量排序”(Diminishing Incre ...
- 排序(4)---------希尔(shell)排序(C语言实现)
由于考试耽搁了几天,不好意思~~~ 前面的介绍的三种排序算法,都属于简单排序,大家能够看下详细算法,时间复杂度基本都在0(n^2),这样呢,非常多计算机界.数学界的牛人就非常不爽了,他们在家里想啊想, ...
- 深入浅出数据结构C语言版(17)——希尔排序
在上一篇博文中我们提到:要令排序算法的时间复杂度低于O(n2),必须令算法执行"远距离的元素交换",使得平均每次交换减少不止1逆序数. 而希尔排序就是"简单地" ...
- c语言希尔排序,并输出结果(不含插入排序)
#include<stdio.h> void shellsort(int* data,int len) { int d=len; int i; ) { d=(d+)/; //增量序列表达方 ...
- 算法分析中最常用的几种排序算法(插入排序、希尔排序、冒泡排序、选择排序、快速排序,归并排序)C 语言版
每次开始动手写算法,都是先把插入排序,冒泡排序写一遍,十次有九次是重复的,所以这次下定决心,将所有常规的排序算法写了一遍,以便日后熟悉. 以下代码总用一个main函数和一个自定义的CommonFunc ...
- C语言实例解析精粹学习笔记——43(希尔排序)
实例说明: 用希尔排序方法对数组进行排序.由于书中更关注的实例,对于原理来说有一定的解释,但是对于第一次接触的人来说可能略微有些简略.自己在草稿纸上画了好久,后来发现网上有好多很漂亮的原理图. 下面将 ...
- C语言中的排序算法--冒泡排序,选择排序,希尔排序
冒泡排序(Bubble Sort,台湾译为:泡沫排序或气泡排序)是一种简单的排序算法.它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没 ...
- C语言实现 冒泡排序 选择排序 希尔排序
// 冒泡排序 // 选择排序 // 希尔排序 // 快速排序 // 递归排序 // 堆排序 #define _CRT_SECURE_NO_WARNINGS #include <stdio.h& ...
随机推荐
- Tkinter 之Menu菜单标签
一.参数说明 语法 作用 MenuBar = tk.Menu(window) 创建一个菜单栏 fileBar = tk.Menu(MenuBar, tearoff=0) 创建一个菜单项,不分窗. Me ...
- 按比例吃CPU
前几天测试软件在多核上的性能,需要按照比例吃各个CPU,查了查资料,撸了下面一小段代码: #include <unistd.h> #include <stdlib.h> #in ...
- Go --- 七牛云 上传文件 & Token demo
package main import ( "bytes" "crypto/hmac" "crypto/sha1" "encodi ...
- Java网络编程之Netty
一.Netty概述 Netty 是由JBOSS 提供的一个java 开源框架.Netty 提供异步的.事件驱动的网络应用程序框架和工具,用以快速开发高性能.高可靠性的网络服务器和客户端程序. 也就是说 ...
- vue设置公共常量
Global.vue <template> </template> <script type="text/javascript"> const ...
- Java并发包线程池之ThreadPoolExecutor
参数详解 ExecutorService的最通用的线程池实现,ThreadPoolExecutor是一个支持通过配置一些参数达到满足不同使用场景的线程池实现,通常通过Executors的工厂方法进行配 ...
- 在 kubernetes 集群中部署一套 web 网站(网页内容不限)
环境准备 一台部署节点,一台master节点,还有两台节点node1,node2 完好的k8s集群环境 思路一: 在node1和node2节点上通过宿主机与容器之间目录映射和端口映射上线静态网站(或动 ...
- 教你如何在linux上装逼,shell中颜色的设置
linux启动后环境变量加载的顺序为:etc/profile → /etc/profile.d/*.sh → ~/.bash_profile → ~/.bashrc → [/etc/bashrc] 想 ...
- Laravel 项目开发环境配置
1.首先安装Laravel 依赖管理包工具 Composer (前提是本地装好了PHP php -v) php -r "copy('https://install.phpcomposer. ...
- 跟我学Shiro目录贴
转发地址:https://www.iteye.com/blog/jinnianshilongnian-2018398 扫一扫,关注我的公众号 购买地址 历经三个月左右时间,<跟我学Shiro&g ...