关于hive on spark会话的共享状态
spark sql中有一个类:
org.apache.spark.sql.internal.SharedState
它是用来做:
1、元数据地址管理(warehousePath)
2、查询结果缓存管理(cacheManager)
3、程序中的执行状态和metrics的监控(statusStore)
4、默认元数据库的目录管理(externalCatalog)
5、全局视图管理(主要是防止元数据库中存在重复)(globalTempViewManager)
1:首先介绍元数据地址管理(warehousePath)
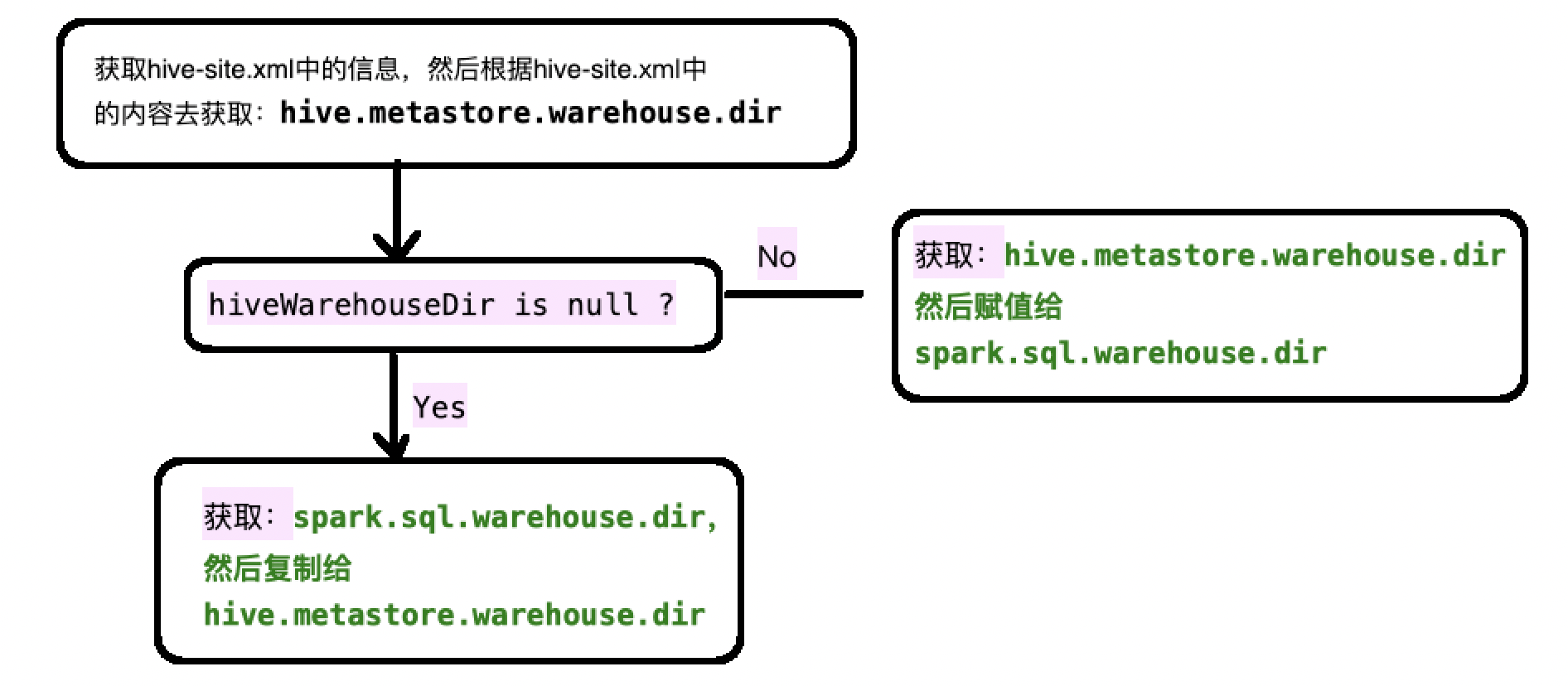
这块儿主要是获取spark sql元数据库的路径地址,那么一般情况,我们都是默认把hive默认作为spark sql的元数据库,因为
它首先去加载hive的配置文件"hive-site.xml" , 然后根据hive-site.xml中获取的信息来获取到hive元数据库的路径:
hive.metastore.warehouse.dir
那么有时候,我们不使用hive作为spark sql的元数据库,那么这个时候我们加载的hive元数据路径应该是null
val hiveWarehouseDir = sparkContext.hadoopConfiguration.get("hive.metastore.warehouse.dir")
如果hiveWarehouseDir是null,那么就去加载spark sql的自带的元数据管理地址(spark.sql.warehouse.dir),然后把这个地址的值赋予给hive.metastore.warehouse.dir
因此大概流程就是获取hiveWarehouseDir:
具体代码:
val warehousePath: String = {
val configFile = Utils.getContextOrSparkClassLoader.getResource("hive-site.xml")
if (configFile != null) {
logInfo(s"loading hive config file: $configFile")
sparkContext.hadoopConfiguration.addResource(configFile)
}
// hive.metastore.warehouse.dir only stay in hadoopConf
sparkContext.conf.remove("hive.metastore.warehouse.dir")
// Set the Hive metastore warehouse path to the one we use
val hiveWarehouseDir = sparkContext.hadoopConfiguration.get("hive.metastore.warehouse.dir")
if (hiveWarehouseDir != null && !sparkContext.conf.contains(WAREHOUSE_PATH.key)) {
// If hive.metastore.warehouse.dir is set and spark.sql.warehouse.dir is not set,
// we will respect the value of hive.metastore.warehouse.dir.
sparkContext.conf.set(WAREHOUSE_PATH.key, hiveWarehouseDir)
logInfo(s"${WAREHOUSE_PATH.key} is not set, but hive.metastore.warehouse.dir " +
s"is set. Setting ${WAREHOUSE_PATH.key} to the value of " +
s"hive.metastore.warehouse.dir ('$hiveWarehouseDir').")
hiveWarehouseDir
} else {
// If spark.sql.warehouse.dir is set, we will override hive.metastore.warehouse.dir using
// the value of spark.sql.warehouse.dir.
// When neither spark.sql.warehouse.dir nor hive.metastore.warehouse.dir is set,
// we will set hive.metastore.warehouse.dir to the default value of spark.sql.warehouse.dir.
val sparkWarehouseDir = sparkContext.conf.get(WAREHOUSE_PATH)
logInfo(s"Setting hive.metastore.warehouse.dir ('$hiveWarehouseDir') to the value of " +
s"${WAREHOUSE_PATH.key} ('$sparkWarehouseDir').")
sparkContext.hadoopConfiguration.set("hive.metastore.warehouse.dir", sparkWarehouseDir)
sparkWarehouseDir
}
}
logInfo(s"Warehouse path is '$warehousePath'.")
warehousePath
2:CacheManager
将查询结果缓存起来 ; 这样的好处就是,如果后面还需要本次查询出来的内容,就不需要在查询一遍数据源了(这块儿有时间单独写篇文章记录)
具体代码:
/**
* Class for caching query results reused in future executions.
*/
val cacheManager: CacheManager = new CacheManager
cacheManager
3:statusStore
代码:
/**
* A status store to query SQL status/metrics of this Spark application, based on SQL-specific
* [[org.apache.spark.scheduler.SparkListenerEvent]]s.
*/
val statusStore: SQLAppStatusStore = {
val kvStore = sparkContext.statusStore.store.asInstanceOf[ElementTrackingStore]
val listener = new SQLAppStatusListener(sparkContext.conf, kvStore, live = true)
sparkContext.listenerBus.addToStatusQueue(listener)
val statusStore = new SQLAppStatusStore(kvStore, Some(listener))
sparkContext.ui.foreach(new SQLTab(statusStore, _))
statusStore
}
statusStore
这段代码其实说白了就是将sql的状态和一些metrics指标写入到监听器中。
那么问题来了,监听器一定是实时的去监听的(读取的),然后spark sql还要不断的往监听器中写入,那么按照传统的list,map这种结构,在读取数据的时候还要在修改结构,会出现错误的;
因此spark sql采用了写时复制容器:
private[this] val listenersPlusTimers = new CopyOnWriteArrayList[(L, Option[Timer])]
将信息不断的写入同时,还不影响读取;
4、externalCatalog
获取spark 会话的内部目录(就是hiveWarehouseDir),如果不存在的话,就按照hiveWarehouseDir创建一个 , 当然,spark会通过回调函数的方式去监控当前目录中的事件:
externalCatalog.addListener(new ExternalCatalogEventListener {
override def onEvent(event: ExternalCatalogEvent): Unit = {
sparkContext.listenerBus.post(event)
}
})
此处代码:
/**
* A catalog that interacts with external systems.
*/
lazy val externalCatalog: ExternalCatalog = {
val externalCatalog = SharedState.reflect[ExternalCatalog, SparkConf, Configuration](
SharedState.externalCatalogClassName(sparkContext.conf),
sparkContext.conf,
sparkContext.hadoopConfiguration) val defaultDbDefinition = CatalogDatabase(
SessionCatalog.DEFAULT_DATABASE,
"default database",
CatalogUtils.stringToURI(warehousePath),
Map())
// Create default database if it doesn't exist
if (!externalCatalog.databaseExists(SessionCatalog.DEFAULT_DATABASE)) {
// There may be another Spark application creating default database at the same time, here we
// set `ignoreIfExists = true` to avoid `DatabaseAlreadyExists` exception.
externalCatalog.createDatabase(defaultDbDefinition, ignoreIfExists = true)
} // Make sure we propagate external catalog events to the spark listener bus
externalCatalog.addListener(new ExternalCatalogEventListener {
override def onEvent(event: ExternalCatalogEvent): Unit = {
sparkContext.listenerBus.post(event)
}
}) externalCatalog
}
externalCatalog
5、
此处就是防止spark执行过程中的临时数据库出现在externalCatalog中,因为如果spark的GLOBAL_TEMP_DATABASE出现在externalCatalog中的话。那么随着程序的执行,下一个线程想要获取元数据库地址的时候,就没法在里面创建hiveWarehouseDir。因此,如果在externalCatalog中存在GLOBAL_TEMP_DATABASE,那么就抛异常
/**
* A manager for global temporary views.
*/
lazy val globalTempViewManager: GlobalTempViewManager = {
// System preserved database should not exists in metastore. However it's hard to guarantee it
// for every session, because case-sensitivity differs. Here we always lowercase it to make our
// life easier.
val globalTempDB = sparkContext.conf.get(GLOBAL_TEMP_DATABASE).toLowerCase(Locale.ROOT)
if (externalCatalog.databaseExists(globalTempDB)) {
throw new SparkException(
s"$globalTempDB is a system preserved database, please rename your existing database " +
"to resolve the name conflict, or set a different value for " +
s"${GLOBAL_TEMP_DATABASE.key}, and launch your Spark application again.")
}
new GlobalTempViewManager(globalTempDB)
}
globalTempViewManager
关于hive on spark会话的共享状态的更多相关文章
- 基于CDH 5.9.1 搭建 Hive on Spark 及相关配置和调优
Hive默认使用的计算框架是MapReduce,在我们使用Hive的时候通过写SQL语句,Hive会自动将SQL语句转化成MapReduce作业去执行,但是MapReduce的执行速度远差与Spark ...
- Hive、Spark SQL、Impala比较
Hive.Spark SQL.Impala比较 Hive.Spark SQL和Impala三种分布式SQL查询引擎都是SQL-on-Hadoop解决方案,但又各有特点.前面已经讨论了Hi ...
- Spark记录-源码编译spark2.2.0(结合Hive on Spark/Hive on MR2/Spark on Yarn)
#spark2.2.0源码编译 #组件:mvn-3.3.9 jdk-1.8 #wget http://mirror.bit.edu.cn/apache/spark/spark-2.2.0/spark- ...
- hive on spark VS SparkSQL VS hive on tez
http://blog.csdn.net/wtq1993/article/details/52435563 http://blog.csdn.net/yeruby/article/details/51 ...
- hive on spark 释放session资源
背景 启动hive时,可以看到2.0以后的版本,将要弃用mr引擎,官方建议使用spark,tez等引擎. spark同时支持批式流式处理,可以减少学习成本.所以选用了spark作为执行引擎. hive ...
- 教你成为全栈工程师(Full Stack Developer) 四十五-一文读懂hadoop、hbase、hive、spark分布式系统架构
转载自http://www.shareditor.com/blogshow?blogId=96 机器学习.数据挖掘等各种大数据处理都离不开各种开源分布式系统,hadoop用于分布式存储和map-red ...
- hive on spark:return code 30041 Failed to create Spark client for Spark session原因分析及解决方案探寻
最近在Hive中使用Spark引擎进行执行时(set hive.execution.engine=spark),经常遇到return code 30041的报错,为了深入探究其原因,阅读了官方issu ...
- Hive on Spark安装配置详解(都是坑啊)
个人主页:http://www.linbingdong.com 简书地址:http://www.jianshu.com/p/a7f75b868568 简介 本文主要记录如何安装配置Hive on Sp ...
- Hive On Spark概述
Hive现有支持的执行引擎有mr和tez,默认的执行引擎是mr,Hive On Spark的目的是添加一个spark的执行引擎,让hive能跑在spark之上: 在执行hive ql脚本之前指定执行引 ...
随机推荐
- RPC一般指远程过程调用协议
RPC一般指远程过程调用协议 RPC(Remote Procedure Call)—远程过程调用,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议.RPC协议假定某些传输协议 ...
- 面试常考的js题目(二)
1. 已知 fn 为一个预定义函数,实现函数 curryIt,调用之后满足如下条件: 返回一个函数 a,a 的 length 属性值为 1(即显式声明 a 接收一个参数) 调用 a 之后,返回一个函数 ...
- 进阶Java编程(5)基础类库
Java基础类库 1,StringBuffer类 String类是在所有项目开发之中一定会使用到的一个功能类,并且这个类拥有如下的特点: ①每一个字符串的常量都属于一个String类的匿名对象,并且不 ...
- C# 日期格式化以及日期常用方法
一.日期格式化 1.ToString() d 月中的某一天.一位数的日期没有前导零. dd 月中的某一天.一位数的日期有一个前导零. ddd 周中某天的缩写名称,在 AbbreviatedDayNam ...
- C3.js入门案例
C3.js是基于D3.js开发的JavaScript库,它可以让开发者构建出可复用的图表,并且还提供了一系列图表上的交互行为.通过C3,只需要往generate函数中传入数据对象就可以轻松的绘制出图表 ...
- extjs CheckboxGroup
// 复选框 var fxkGroup = new Ext.form.CheckboxGroup({ id : 'fxkGroup', xtype : 'checkboxgroup', name : ...
- Semaphore拿到执行权的线程之间是否互斥
java线程之间的控制,使用Semaphore 实现 互斥 下面我们通过Semaphore来实现一个比较好的互斥操作: package com.zhy.concurrency.semaphore; i ...
- nginx 配置反向代理和负载均衡
Nginx的配置文件: nginx安装目录/conf/nginx.conf 重新加载配置文件 ./nginx -s reload 配置虚拟主机 一个server就是一台虚拟主机 server { li ...
- vue移动端出现遮罩层时在遮罩层滑动时禁止遮罩层下方页面滑动
h5页面 点击出现弹框时 在遮罩层上面滑动时 下方的页面会出现滑动现象 解决方法 我知道的有以下两种 在遮罩层标签上添加@touchmove.prevent 把遮罩层显示时把下方的父盒子css设置为固 ...
- 保证在浏览器上word/图片/Excel的下载的表现形式一样
function downloadImage(src) { console.log(src); //src="http://192.168.12.50:8181/file/common/pn ...