【MapReduce】一、MapReduce简介与实例
(一)MapReduce介绍
1、MapReduce简介
MapReduce是Hadoop生态系统的一个重要组成部分,与分布式文件系统HDFS、分布式数据库HBase一起合称为传统Hadoop的三驾马车,一起构成了一个面向海量数据的分布式系统的基础架构。
MapReduce是一个用于大规模数据(大于1TB)处理的分布式计算模型、编程模型,它最初是由Google设计并实现的,在Google提出时,给它的定义是:Map/Reduce是一个编程模型(programming model),是一个用于处理和生成大规模数据集(processing and generating large data sets)的相关的实现。
MapReduce的主要思想“Map(映射)”和“Reduce(规约)”都来自于函数式编程语言。MapReduce极大地方便了编程人员在不会分布式并行编程的情况下,将自己的程序运行在分布式系统之上。用户只需要定义一个map函数来处理一个key/value对以生成一批中间的key/value对,再定义一个reduce函数将所有这些中间的有着相同key的values合并起来。很多现实世界中的任务都可用这个模型来表达,具有较强的实用价值。
具体来看,MapReuce应当是包含了以下三层含义:
(1)MapReduce是一个基于集群的高性能并行计算平台。通过MapReduce可以将市场上普通的商用服务器构成一个包含数十、数百甚至数千个节点的分布和并行计算集群。
(2)MapReduce是一个并行计算与运行软件框架。它提供了一个庞大但设计精良的并行计算软件框架,能自动完成计算任务的并行化处理,自动划分计算数据和计算任务,在集群节点上自动分配和执行任务以及收集计算结果,将数据分布存储、数据通信、容错处理等并行计算涉及到的很多系统底层的复杂细节交由系统负责处理,大大减少了软件开发人员的负担。
(3)MapReduce是一个并行程序设计模型与方法。它借助于函数式程序设计语言Lisp的设计思想,提供了一种简便的并行程序设计方法,用Map和Reduce两个函数编程实现基本的并行计算任务,提供了抽象的操作和并行编程接口,以简单方便地完成大规模数据的编程和计算处理。
MapReduce的数据处理模型非常简单:map函数和reduce函数的输入和输出都遵循<key,value>键值对的格式,简单的用符号表示就是:
Map:(K1,V1)——> list(K2,V2)
Reduce:(K2,list< V2>)——> list<K3,V3>
Map-Reduce框架的运作完全基于<key,value>对,即数据的输入是一批<key,value>对,生成的结果也是一批<key,value>对,只是有时候它们的类型不一样而已。Key和value的类由于需要支持被序列化(serialize)操作,所以它们必须要实现Writable接口,而且key的类还必须实现WritableComparable接口,使得可以让框架对数据集的执行排序操作,后面我们通过具体的实例来展示它的用法。
2、MapReduce版本演化
MapReduce是Hadoop生态系统的一员,是一个完全开源的分布式计算系统。MapReduce从第一次提出到今天,并不是一成不变的,虽然其主流思想和计算模型没有大的改变,但是整个系统也是在不断的完善和演变的。
首先经典版本的MapReduce框架,也就是第一版成熟的商用框架,属于Hadoop的V1.0版本,这个版本的主要特点是简单易用,其思路也比较清晰,各个Client提交Job给一个统一的Job Tracker,然后Job Tracker将Job拆分成N个Task,然后进行分发到各个节点(Node)进行并行协同运行,然后再将各自的运行结果反馈至Job Tracker,进而输出结果。
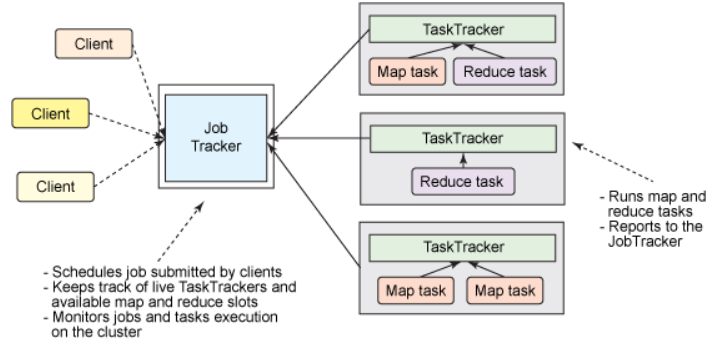
虽然实现简单,但是这个1.0版本存在着其固有的局限性,其中最主要的一点就是:单点故障问题。所有的Job的完成都得益于JobTracker的调度和分配,一旦此节点宕机就意味着整个平台的瘫痪,当然,在实际中大部分通过一个备用机来解决。但是,在一个以分布式运算为特性的框架中,将这种核心的计算集中与一台机器不是一个最优的方案。其次,这个设计扩展性不强,容易造成资源的浪费。
因此,为了减轻单个JobTracker的职责,mapreduce的2.0版本开始引入了YARN作为集群的资源管理器,JobTracker的职责分为两大部分:集群资源管理和任务协调,YARN作为资源管理器,专注于负责整个平台的资源管理,而任务的调度和协调交给下属的任务节点来完成。其主要的运行机制后面具体解析。
目前为止,Hadoop已经发展到了3.0版本,3.0和2.0版本在编程模型和运行机制上没有太大的变化,仍然使用YARN作为其资源管理器,但是在稳定性、存储开销和兼容性等方面有所优化。
(二)MapReduce实例(WordCount)
下面通过实例来对MapReduce的过程进行说明。
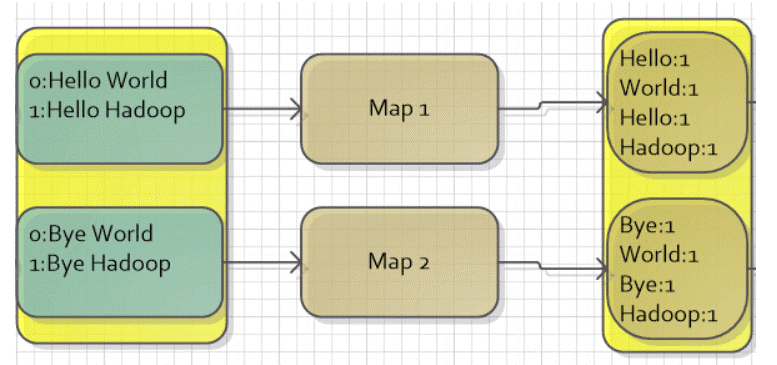
WordCount是Hadoop自带的一个例子,目标是统计文本文件中单词的个数。假设有如下的两个文本文件来运行WorkCount程序:
第一个文件内容:Hello World Bye World
第二个文件内容:Hello Hadoop GoodBye Hadoop
(1)Map数据的输入
MapReduce针对文本文件缺省使用LineRecordReader类来实现读取,一行一个key/value对,key取偏移量,value为行内容。因此,对于给出的文件,假设每个文件正好是一个分片,那么会有两个Map任务,MapReduce会将其映射为如下所示的键值对作为Map过程的输入。
| Map任务 | key | value |
|---|---|---|
| map1 | 0(偏移量) | Hello World Bye World |
| map2 | 0(偏移量) | Hello Hadoop GoodBye Hadoop |
(2)Map的输出
用户通过定义map函数对输入的键值对进行处理,目标是统计每个单词的个数,这相当于一个数据预处理的过程,经过处理后,会输出一系列的键值对,键是每个单词,而值是个数(也就是1)。
| Map任务 | key | value |
|---|---|---|
| map1 | Hello | 1 |
| map1 | World | 1 |
| map1 | Bye | 1 |
| map1 | World | 1 |
| map2 | Hello | 1 |
| map2 | Hadoop | 1 |
| map2 | GoodBye | 1 |
| map2 | Hadoop | 1 |
这里需要注意,MapReduce还有一个可以在此时用的功能是Combiner,它可以将相同key的值合并起来,它也用Reducer的实现。但是,有些情况,Combiner并不适用,只有中间结果合并之后不会影响最终结果的才可以使用Combiner,如这里计算单词次数,这就可以使用Comniner,使用后,map1任务中的World会合并为1个,个数成为2,同样map2任务的Hadoop也合并为1个,个数成为2。
(3)Reduce的输入
Map或者Combiner的输出(如果有的话)会经历一个shuffle的过程,这个过程将key相同的数据进行合并,并按照字符顺序进行排序。
如这里Combiner输出进行shuffle之后会得到:
| Key | Value |
|---|---|
| Bye | [1] |
| GoodBye | [1] |
| Hadoop | [2] |
| Hello | [1,1] |
| World | [2] |
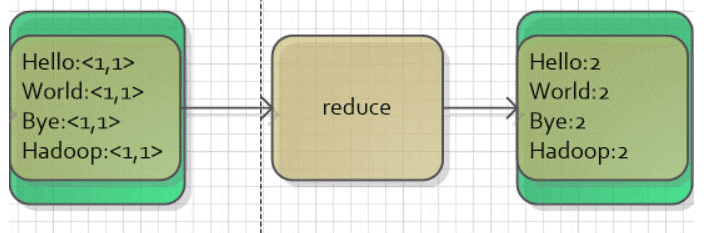
(4)Reduce的输出
最后,Reducer实现将相同key的值合并起来,得到最后的结果。
| Key | Value |
|---|---|
| Bye | 1 |
| GoodBye | 1 |
| Hadoop | 2 |
| Hello | 2 |
| World | 2 |
如图所示:
如下图:
这就是一个MapReduce应用的实例,其编程实现也非常简单,用户只需要定义map函数和reduce函数,然后写一个驱动程序来运行作业即可。
public static class Map extends Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); //输出的key的类型,可以理解为String
public void map(LongWritable key, Text value, Context context) {
String line = value.toString(); //每行句子
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one); //输出
}
}
}
public static class Reduce extends Reducer<Text, IntWritable, Text, IntWritable> {
//在这里,reduce步的输入相当于<单词,valuelist>,如<Hello,<1,1>>
public void reduce(Text key, Iterable<IntWritable> values,Context context) {
int sum = 0;
for (IntWritable val : values)
sum += val.get();
context.write(key, new IntWritable(sum));
}
}
以上就是map函数和reduce函数的实现,逻辑都很简单,最后我们只需要写一个主函数,设置一个Job作业,进行相对设置,就可以运行,比如如下的Job作业设置了处理该作业的类、作业名字、输入输出数据的路径、map和reduce对应的类、输出结果类型,最后调用执行命令进行执行即可。
Job job = new Job(); // 创建一个作业对象
job.setJarByClass(WordCount.class); // 设置运行/处理该作业的类
job.setJobName("WordCount");
FileInputFormat.addInputPath(job, new Path(args[0])); //设置这个作业输入数据的路径
FileOutputFormat.setOutputPath(job, new Path(args[1])); //设置这个作业输出结果的路径
job.setMapperClass(Map.class); //设置实现了Map步的类
job.setReducerClass(Reduce.class); //设置实现了Reduce步的类
job.setOutputKeyClass(Text.class); //设置输出结果key的类型
job.setOutputValueClass(IntWritable.class); //设置输出结果value的类型
System.exit(job.waitForCompletion(true) ? 0 : 1); //执行作业
【MapReduce】一、MapReduce简介与实例的更多相关文章
- MapReduce工作机制——Word Count实例(一)
MapReduce工作机制--Word Count实例(一) MapReduce的思想是分布式计算,也就是分而治之,并行计算提高速度. 编程思想 首先,要将数据抽象为键值对的形式,map函数输入键值对 ...
- MapReduce本地运行模式wordcount实例(附:MapReduce原理简析)
1. 环境配置 a) 配置系统环境变量HADOOP_HOME b) 把hadoop.dll文件放到c:/windows/System32目录下 c) ...
- mapreduce (五) MapReduce实现倒排索引 修改版 combiner是把同一个机器上的多个map的结果先聚合一次
(总感觉上一篇的实现有问题)http://www.cnblogs.com/i80386/p/3444726.html combiner是把同一个机器上的多个map的结果先聚合一次现重新实现一个: 思路 ...
- mapreduce (二) MapReduce实现倒排索引(一) combiner是把同一个机器上的多个map的结果先聚合一次
1 思路:0.txt MapReduce is simple1.txt MapReduce is powerfull is simple2.txt Hello MapReduce bye MapRed ...
- 使用mapreduce计算环比的实例
最近做了一个小的mapreduce程序,主要目的是计算环比值最高的前5名,本来打算使用spark计算,可是本人目前spark还只是简单看了下,因此就先改用mapreduce计算了,今天和大家分享下这个 ...
- Hadoop学习笔记: MapReduce Java编程简介
概述 本文主要基于Hadoop 1.0.0后推出的新Java API为例介绍MapReduce的Java编程模型.新旧API主要区别在于新API(org.apache.hadoop.mapreduce ...
- MapReduce编程模型简介和总结
MapReduce应用广泛的原因之一就是其易用性,提供了一个高度抽象化而变得非常简单的编程模型,它是在总结大量应用的共同特点的基础上抽象出来的分布式计算框架,在其编程模型中,任务可以被分解成相互独立的 ...
- MapReduce工作原理(简单实例)
Map-Reduce框架的运作完全基于<key,value>对,即数据的输入是一批<key,value>对,生成的结果也是一批<key,value>对,只是有时候它 ...
- MapReduce(一) mapreduce基础入门
一.mapreduce入门 1.什么是mapreduce 首先让我们来重温一下 hadoop 的四大组件:HDFS:分布式存储系统MapReduce:分布式计算系统YARN: hadoop 的资源调度 ...
随机推荐
- New!Devexpress WinForms各版本支持Visual Studo和SQL Server版本对应图
点击获取DevExpress v19.2.3最新完整版试用下载 本文主要为大家介绍DevExpress WinForms各大版本支持的VS版本和支持的.Net版本图,Devexpress WinFor ...
- tcpip入门的网络教程汇总
网络编程懒人入门(一):快速理解网络通信协议(上篇) http://www.52im.net/thread-1095-1-1.html TCP/IP详解学习笔记 https://www.cnblogs ...
- 题解 POJ1149 Pigs
先翻译一下吧(题面可以在原OJ上找) Mirko在一个由M个锁着的猪舍组成的养猪场工作,Mirko无法解锁任何猪舍,因为他没有钥匙.客户纷纷来到农场.他们每个人都有一些猪舍的钥匙,并想购买一定数量的猪 ...
- vue的简单使用
1.使用vue 下载vue.js: 下载地址:https://vuejs.org/js/vue.min.js:打开链接后是一大堆js代码:ctrl+s保存即可: 新建一个htm ...
- linux命令系列
Linux系统安装node linux安装rz sz命令:yum install lrzsz上传tar包:rz node-v10.15.0-linux-x64.tar.xz将tar包移到上一级目录下: ...
- BZOJ 2651 城市改建 树形DP+模拟?
题意 给一颗树,删除一条边再加一条边,使它仍为一颗树且任意两点间的距离的最大值最小. 题目数据范围描述有问题,n为1或重建不能使任意两点距离最大值变小,可以输出任意答案. 分析 删除一条边后会使它变成 ...
- Primes and Multiplication
C - Primes and Multiplication 思路:找到x的所有质数因子,用一个vector储存起来,然后对于每一个质因子来说,我们要找到它对最后的答案的贡献的大小,即要找到它在最后的乘 ...
- [CSP-S模拟测试]:凉宫春日的忧郁(乱搞)
题目传送门(内部题101) 输入格式 第一行输入一个整数$T$,表示数据组数. 接下来$T$行,每行两个数$X,Y$,表示$T$组数据. 输出格式 输出共有$T$行,对于每一组数据,如果$X^Y\le ...
- BZOJ1706奶牛接力跑
这个东西思路还是不错的. 解法就是把矩阵幂的加法改成取min,乘法改成加法就好,和floyed是一样的.这样的话,矩阵操作一次就相当于松弛了一次最短路. 建矩阵的过程也比较简单,可以离散化,当然下面有 ...
- BZOJ3331压力
码量略大. 题意就是求路径必经点. tarjan缩点,所有的非割点只有是起点终点时才必经,直接开个ans数组就OK了. 至于割点,因为缩完点之后的图是vDcc和割点共同组成的,而且题目说连通,那就是棵 ...