sklearn--模型的评价
sklearn.metrics
1.MSE(均方误差)和RMSE(均方根误差),以及score()
lr.score(test_x,test_y)#越接近1越好,负的很差
from sklearn.metrics import mean_squared_error
mean_squared_error(test_y,lr.predict(test_x))#mse
np.sqrt(mean_squared_error(test_y,lr.predict(test_x)))
from sklearn.metrics import accuracy_score
print(accuracy_score(predict_results, target_test))
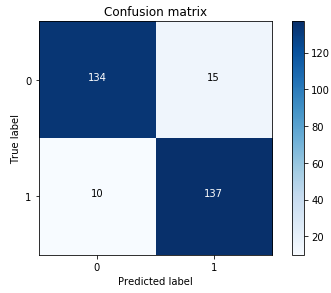
2.混淆矩阵
混淆矩阵的每一列代表了预测类别 ,每一列的总数表示预测为该类别的数据的数目;每一行代表了数据的真实归属类别,每一行的数据总数表示该类别的数据实例的数目。每一列中的数值表示真实数据被预测为该类的数目:如下图,第一行第一列中的43表示有43个实际归属第一类的实例被预测为第一类,同理,第二行第一列的2表示有2个实际归属为第二类的实例被错误预测为第一类。
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
import seaborn as sns
sns.heatmap(cnf_matrix,cmap="Blues",annot=True,fmt='d',square=True)
plt.ylabel('True Label')
plt.xlabel('pre Label')
plt.title('Confusion matrix')
学习曲线
通过观察训练集和测试集的得分来看两个曲线的靠近程度,如果是两个曲线的方差太大,测试集差训练集好,则说明是过拟合,如果两个曲线方差不太大,两个的训练的效果都不好,这就说明是欠拟合
from sklearn.model_selection import learning_curve #绘制学习曲线,以确定模型的状况
def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None,
train_sizes=np.linspace(.1, 1.0, 5)):
"""
画出data在某模型上的learning curve.
参数解释
----------
estimator : 你用的分类器。
title : 表格的标题。
X : 输入的feature,numpy类型
y : 输入的target vector
ylim : tuple格式的(ymin, ymax), 设定图像中纵坐标的最低点和最高点
cv : 做cross-validation的时候,数据分成的份数,其中一份作为cv集,其余n-1份作为training(默认为3份)
"""
plt.figure()
train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=5, n_jobs=1, train_sizes=train_sizes,scoring='neg_mean_squared_error')
train_scores=np.sqrt(-train_scores)
test_scores=np.sqrt(-test_scores)
train_scores_mean = np.mean(train_scores, axis=1)
train_scores_std = np.std(train_scores, axis=1)
test_scores_mean = np.mean(test_scores, axis=1)
test_scores_std = np.std(test_scores, axis=1)
plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r")
plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g")
plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Training score")
plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="Cross-validation score")
plt.xlabel("Training examples")
plt.ylabel("Score")
plt.legend(loc="best")
plt.grid("on")
if ylim:
plt.ylim(ylim)
plt.title(title)
plt.show() #少样本的情况情况下绘出学习曲线

sklearn--模型的评价的更多相关文章
- sklearn 模型选择和评估
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- sklearn模型保存与加载
sklearn模型保存与加载 sklearn模型的保存和加载API 线性回归的模型保存加载案例 保存模型 sklearn模型的保存和加载API from sklearn.externals impor ...
- python sklearn模型的保存
使用python的机器学习包sklearn的时候,如果训练集是固定的,我们往往想要将一次训练的模型结果保存起来,以便下一次使用,这样能够避免每次运行时都要重新训练模型时的麻烦. 在python里面,有 ...
- sklearn模型的属性与功能-【老鱼学sklearn】
本节主要讲述模型中的各种属性及其含义. 例如上个博文中,我们有用线性回归模型来拟合房价. # 创建线性回归模型 model = LinearRegression() # 训练模型 model.fit( ...
- sklearn模型保存
使用sklearn训练完模型之后,只有将模型持久化到硬盘上,才能方便下次直接使用. 第一种方式:使用pickle >>> from sklearn import svm >&g ...
- sklearn 模型评估
原文链接 http://d0evi1.com/sklearn/model_evaluation/ 预测值:pred 真实值:y_test #### 直接用平均值 ``` mean(pred == y_ ...
- Sklearn,TensorFlow,keras模型保存与读取
一.sklearn模型保存与读取 1.保存 from sklearn.externals import joblib from sklearn import svm X = [[0, 0], [1, ...
- sklearn中模型评估和预测
一.模型验证方法如下: 通过交叉验证得分:model_sleection.cross_val_score(estimator,X) 对每个输入数据点产生交叉验证估计:model_selection.c ...
- Sklearn数据集与机器学习
sklearn数据集与机器学习组成 机器学习组成:模型.策略.优化 <统计机器学习>中指出:机器学习=模型+策略+算法.其实机器学习可以表示为:Learning= Representati ...
- python进行机器学习(四)之模型验证与参数选择
一.模型验证 进行模型验证的一个重要目的是要选出一个最合适的模型,对于监督学习而言,我们希望模型对于未知数据的泛化能力强,所以就需要模型验证这一过程来体现不同的模型对于未知数据的表现效果. 这里我们将 ...
随机推荐
- .Netcore 2.0 Ocelot Api网关教程(9)- QoS
本文介绍Ocelot中的QoS(Quality of Service),其使用了Polly对超时等请求下游失败等情况进行熔断. 1.添加Nuget包 添加 Ocelot.Provider.Polly ...
- html5 商品分类页面效果zepto
点击左边容器条目,右边列表对应的内容置顶显示,滑动右边的列表,左边容器的对应的标题高亮显示. 效果图如下: 代码: <!doctype html> <html> <hea ...
- MySQL中的日期和时间:使用和说明,以及常用函数
1.首先需要注意: 1.1 MySQL中把日期和时间是分开的. 以字符串2007-12-31 00:59:59为例: 日期部分:2007-12-31.这部分也可以叫做一个日期表达式. 时间部分:00: ...
- JavaScript 检测值
了解常见的真值和假值,可以增强判断能力.在使用if判断时,提升编码速度. 了解常见的检测和存在,一样可以增强判断能力,而且是必须掌握的. 数组和对象被视为真值 1 2 3 4 5 6 7 8 9 10 ...
- Vufuria入门 1 图片识别和选择
Vufutia中的图片识别功能,底层主要是识别特征点来实现的.特征点,即那些棱角分明的点.尖锐的而不是圆滑的.对比度大的而不是小的. *** 步骤: 进入vofuria官网,登录,点击develop. ...
- Python基础『一』
内置数据类型 数据名称 例子 数字: Bool,Complex,Float,Integer True/False; z=a+bj; 1.23; 123 字符串: String '123456' 元组: ...
- python-----模块【第一部分】-----
一.hashlib(md5) import hashlib obj = hashlib.md5('dsfd'.encode('utf-8')) obj.update('123'.encode('utf ...
- python学习-8 用户有三次机会登陆
用户登陆(三次机会) count = 0 while count < 3: user = input('请输入账号:') pwd = input('请输入密码:') ': print(" ...
- Python爬虫详解
Python爬虫详解 Python 之 Urllib库的基本使用 Python中requests库使用方法详解 Beautifulsoup模块基础用法详解 selenium模块基础用法详解 re(正则 ...
- VS2017生成一个简单的DLL文件 和 LIB文件——C语言
下面我们将用两种不同的姿势来用VS2017生成dll文件(动态库文件)和lib文件(静态库文件),这里以C语言为例,用最简单的例子,来让读者了解如何生成dll文件(动态库文件) 生成动态库文件 姿势一 ...