Apriori 算法python实现
1. Apriori算法简介
Apriori算法是挖掘布尔关联规则频繁项集的算法。Apriori算法利用频繁项集性质的先验知识,通过逐层搜索的迭代方法,即将K-项集用于探察(k+1)项集,来穷尽数据集中的所有频繁项集。先找到频繁项集1-项集集合L1, 然后用L1找到频繁2-项集集合L2,接着用L2找L3,知道找不到频繁K-项集,找到每个Lk需要一次数据库扫描。注意:频繁项集的所有非空子集也必须是频繁的。Apriori性质通过减少搜索空间,来提高频繁项集逐层产生的效率。Apriori算法由连接和剪枝两个步骤组成。
2. Apriori算法步骤
根据一个实例来解释:下图是一个交易单,I1至I5可看作5种商品。下面通过频繁项集合来找出关联规则。
假设我们的最小支持度阈值为2,即支持度计数小于2的都要删除。
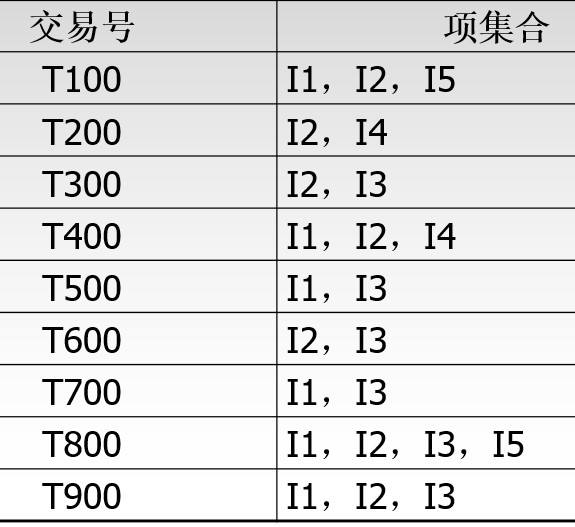
上表第一行(第一项交易)表示:I1和I2和I5一起被购买。
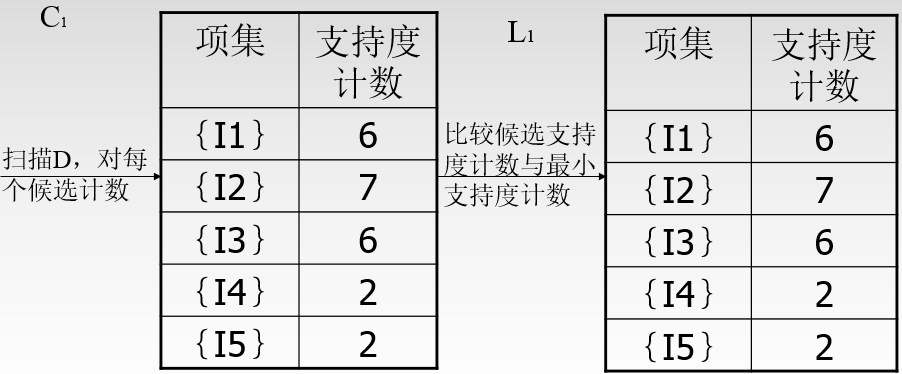
C1至L1的过程: 只需查看支持度是否高于阈值,然后取舍。上图C1中所有阈值都大于2,故L1中都保留。
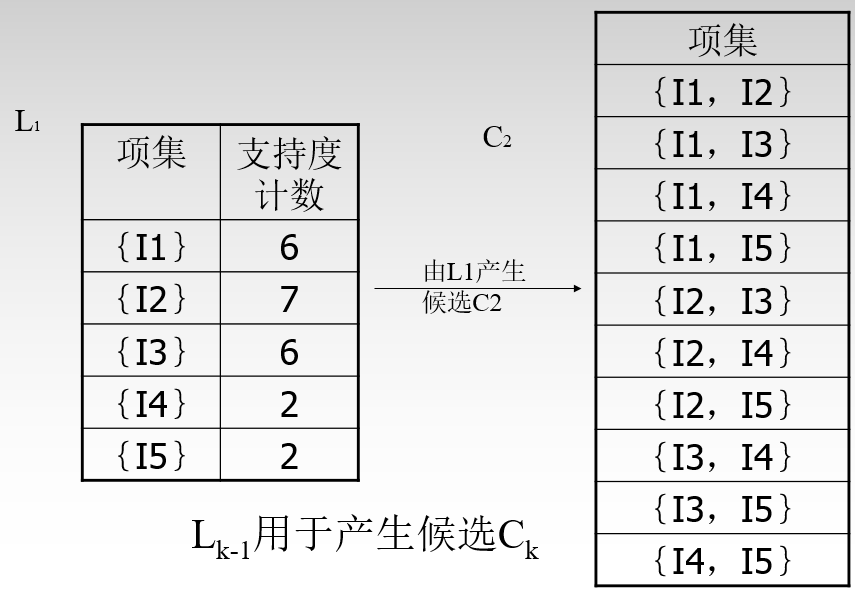
L1至C2的过程分三步:
- 遍历产生L1中所有可能性组合,即(I1,I2)...(I4,I5 )
- 对便利产生的每个组合进行拆分,以保证频繁项集的所有非空子集也必须是频繁的。即对于(I1,I2)来说进行拆分为I1,I2.由于I1和I2在L1中都为频繁项,所以这一组合保留。
- 对于剩下的C2根据原数据集中进行支持度计数
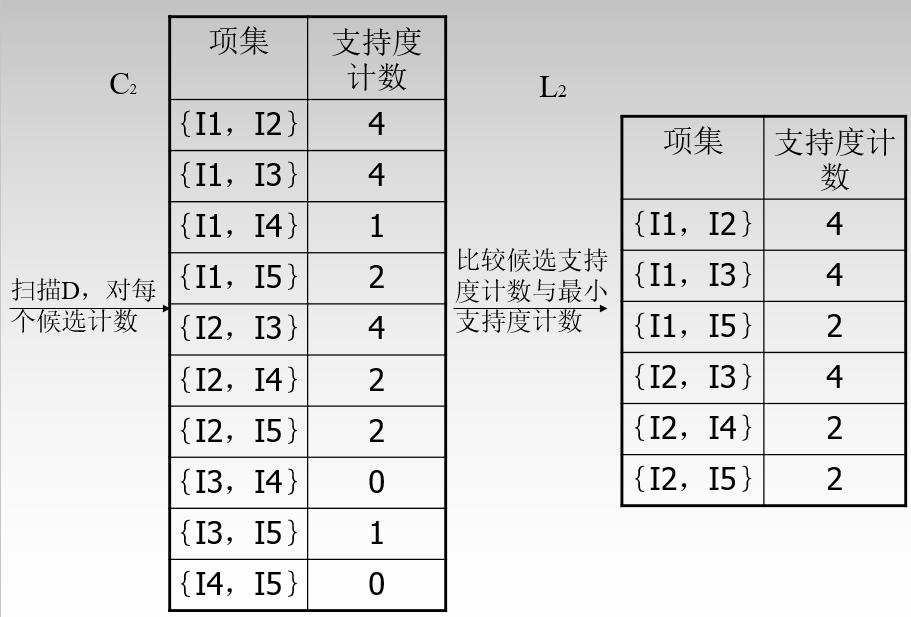
C2至L2的过程: 只需查看支持度是否高于阈值,然后取舍。
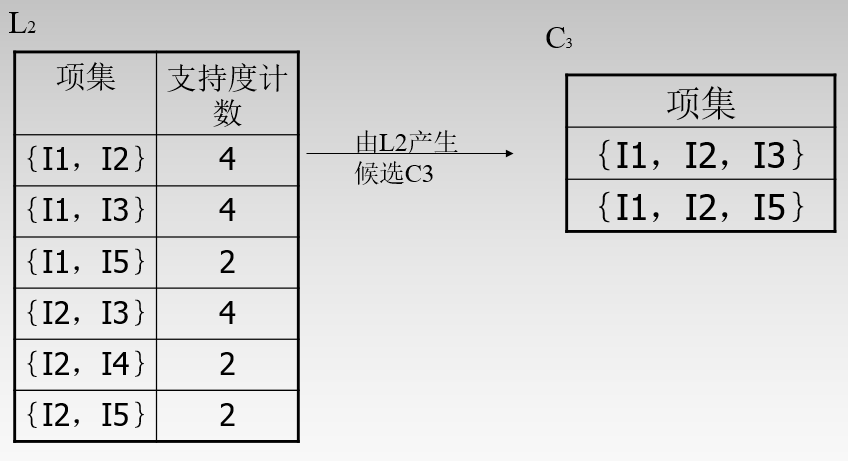
L2至C3的过程:
还是上面的步骤。首先生成(1,2,3)、(1,2,4)、(1,2,5)....为什么最后只剩(1,2,3)和(1,2,5)呢?因为剪枝过程:(1,2,4)拆分为(1,2)和(1,4)和(2,4).然而(1,4)在L2中不存在,即非频繁项。所有剪枝删除。然后对C3中剩下的组合进行计数。发现(1,2,3)和(1,2,5)的支持度2。迭代结束。
所以算法过程就是 Ck - Lk - Ck+1 的过程:
3.Apriori算法实现
# -*- coding: utf-8 -*-
"""
Created on Sat Dec 9 15:33:45 2017 @author: LPS
""" import numpy as np
from itertools import combinations # 迭代工具 data = [[1,2,5], [2,4], [2,3], [1,2,4], [1,3], [2,3], [1,3], [1,2,3,5], [1,2,3]]
minsp = 2 d = []
for i in range(len(data)):
d.extend(data[i])
new_d = list(set(d)) def satisfy(s, s_new, k): # 更新确实存在的L e =[]
ss_new =[]
for i in range(len(s_new)):
for j in combinations(s_new[i], k): # 迭代产生所有元素可能性组合
e.append(list(j))
if ([l for l in e if l not in s]) ==[] :
ss_new.append(s_new[i])
e = [] return ss_new # 筛选满足条件的结果 def count(s_new): # 返回narray格式的C
num = 0
C = np.copy(s_new)
C = np.column_stack((C, np.zeros(C.shape[0]))) for i in range(len(s_new)):
for j in range(len(data)):
if ([l for l in s_new[i] if l not in data[j]]) ==[] :
num = num+1
C[i,-1] = num
num = 0 return C def limit(L): # 删掉不满足阈值的C
row = []
for i in range(L.shape[0]):
if L[i,-1] < minsp :
row.append(i)
L = np.delete(L, row, 0) return L def generate(L, k): # 实现由L至C的转换
s = []
for i in range(L.shape[0]):
s.append(list(L[i,:-1]))
s_new = []
# L = L.delete(L, -1, 1)
# l = L.shape[1]
for i in range(L.shape[0]-1):
for j in range(i+1, L.shape[0]):
if (L[j,-2]>L[i,-2]):
t = list(np.copy(s[i]))
t.append(L[j,-2])
s_new.append(t) # s_new为列表 s_new = satisfy(s, s_new, k) C = count(s_new) return C # 初始的C与L
C = np.zeros([len(new_d), 2])
for i in range(len(new_d)):
C[i:] = np.array([new_d[i], d.count(new_d[i])]) L = np.copy(C)
L = limit(L) # 开始迭代
k = 1
while (np.max(L[:,-1]) > minsp):
C = generate(L, k) # 由L产生C
L = limit(C) # 由C产生L
k = k+1 # 对最终结果去重复 print((list(set([tuple(t) for t in L])))
# 结果为 [(1.0, 2.0, 3.0, 2.0), (1.0, 2.0, 5.0, 2.0)]
Apriori 算法python实现的更多相关文章
- 数据挖掘入门系列教程(五)之Apriori算法Python实现
数据挖掘入门系列教程(五)之Apriori算法Python实现 加载数据集 获得训练集 频繁项的生成 生成规则 获得support 获得confidence 获得Lift 进行验证 总结 参考 数据挖 ...
- Apriori算法Python实现
Apriori如果数据挖掘算法的头发模式挖掘鼻祖,从60年代开始流行,该算法非常简单朴素的思维.首先挖掘长度1频繁模式,然后k=2 这些频繁模式的长度合并k频繁模式.计算它们的频繁的数目,并确保其充分 ...
- Apriori算法--Python实现
# -*- coding: utf-8 -*- """ Created on Mon Nov 05 22:50:13 2018 @author: ZhuChaochao ...
- Apriori算法的原理与python 实现。
前言:这是一个老故事, 但每次看总是能从中想到点什么.在一家超市里,有一个有趣的现象:尿布和啤酒赫然摆在一起出售.但是这个奇怪的举措却使尿布和啤酒的销量双双增加了.这不是一个笑话,而是发生在美国沃尔玛 ...
- Apriori算法介绍(Python实现)
导读: 随着大数据概念的火热,啤酒与尿布的故事广为人知.我们如何发现买啤酒的人往往也会买尿布这一规律?数据挖掘中的用于挖掘频繁项集和关联规则的Apriori算法可以告诉我们.本文首先对Apriori算 ...
- Apriori算法思想和其python实现
第十一章 使用Apriori算法进行关联分析 一.导语 "啤酒和尿布"问题属于经典的关联分析.在零售业,医药业等我们经常需要是要关联分析.我们之所以要使用关联分析,其目的是为了从大 ...
- Python两步实现关联规则Apriori算法,参考机器学习实战,包括频繁项集的构建以及关联规则的挖掘
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- 【机器学习】Apriori算法——原理及代码实现(Python版)
Apriopri算法 Apriori算法在数据挖掘中应用较为广泛,常用来挖掘属性与结果之间的相关程度.对于这种寻找数据内部关联关系的做法,我们称之为:关联分析或者关联规则学习.而Apriori算法就是 ...
- Apriori算法在购物篮分析中的运用
购物篮分析是一个很经典的数据挖掘案例,运用到了Apriori算法.下面从网上下载的一超市某月份的数据库,利用Apriori算法进行管理分析.例子使用Python+MongoDB 处理过程1 数据建模( ...
随机推荐
- 在 Linux 上安装配置 BitTorrent Sync [转]
背景介绍:目前我们线上的前端服务器数量比较多,超过200多台,每次发布新应用的时候,都是将软件包放在一台专门的Push服务器上,再由所有的前端服务器通过rsync自动同步.但随着前端服务器的数量越来越 ...
- CF 681
我太水了...... 这是一场奇差无比的CF. A,看题意有困难,实际上还是很水的. B,枚举 1234567 和 123456 的个数,时间复杂度1e6以下 C,业界毒瘤模拟题.最TM坑的是还要输出 ...
- 【UVA10140】Prime Distance
题目大意:求出一个给定区间 [l, r] 内相邻素数之间的最大距离和最小距离. 题解:由于 l, r 的范围太大,没法直接用筛法得出区间的素数.考虑筛出区间的素数等价于筛掉区间内的所有和数, 根据算术 ...
- isinstance和issubclass,__getattribute__,__getitem__,__setitem__,delitem__,__str__(三十五)
isinstance(obj,cls)检查是否obj是否是类 cls 的对象 issubclass(sub, super)检查sub类是否是 super 类的派生类 class Foo: def __ ...
- MyEclipse添加模板注释
只有两个步骤: 1.设置模板 Windows—Preference—Java—Code Style—Code Templates 图中, Configure generated code and co ...
- Linux下JDK+Eclipse安装
Ubuntu版本14.04 JDK8_144 eclipse最新下载 注:原本安装JDK7配置好环境后报错,原来是最新eclipse的一个功能只有JDK8支持,若想使用JDK7需要注释某条代码 JDK ...
- 5个强大的Java分布式缓存框架
在开发中大型Java软件项目时,很多Java架构师都会遇到数据库读写瓶颈,如果你在系统架构时并没有将缓存策略考虑进去,或者并没有选择更优的缓存策略,那么到时候重构起来将会是一个噩梦.本文主要是分享了5 ...
- selenium_采集药品数据
Python爬虫视频教程零基础小白到scrapy爬虫高手-轻松入门 https://item.taobao.com/item.htm?spm=a1z38n.10677092.0.0.482434a6E ...
- python---生成验证码图片
工具插件verifycode.py中,记得使用时需要在路由根目录中引入文字资源文件 # coding:utf8 # __author: Administrator # date: // # /usr/ ...
- JavaScript Array() 对象:push() 和 join() 方法
<script> var fruits = ["Banana", "Orange", "Apple", "Mango& ...