爬虫系列之BeautifulSoup
BeautifulSoup是处理爬虫的一个强大工具,在HTML页面中,是由各种标签构成的,BeautifulSoup的功能就是从标签下手的,它是解析、遍历、维护“标签树”的功能库。
BeautifulSoup的基本元素如下:

1. 基本格式如下:
from bs4 import BeautifulSoup
import requests url = "http://python123.io/ws/demo.html" r = requests.get(url)
demo = r.text
soup = BeautifulSoup(demo, "html.parser") #将爬到的内容进行解析,demo就是内容,"html.parser"是解析器,按照html格式来进行解析
print(soup.prettify()) #输出解析得到的内容
解析效果如下:

2. 具体使用方法如下:
>>> from bs4 import BeautifulSoup
>>> import requests
>>> url = "http://python123.io/ws/demo.html"
>>> r = requests.get(url)
>>> demo = r.text
>>> soup = BeautifulSoup(demo, "html.parser")
>>> soup.title #显示标题
<title>This is a python demo page</title>
>>> soup.a #显示a标签内容
<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a>
>>> soup.a.name #显示a标签名字
'a'
>>> soup.a.parent.name #显示a标签父标签名字
'p'
>>> soup.a.parent.parent.name #显示a标签父标签的父标签名字
'body'
>>> soup.a.attrs #获得a标签的属性
{'href': 'http://www.icourse163.org/course/BIT-268001', 'class': ['py1'], 'id': 'link1'}
>>> soup.a.attrs["class"] #因为是字典,所以这里用字典形式可以获得各个属性的值
['py1']
>>> type(soup.a.attrs)
<class 'dict'> #字典类型
>>> soup.a.string #获得a标签中的字符内容
'Basic Python'
>>> soup #soup内容如下
<html><head><title>This is a python demo page</title></head>
<body>
<p class="title"><b>The demo python introduces several python courses.</b></p>
<p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses: <a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>
</body></html>
>>>
3. 标签树的下行遍历
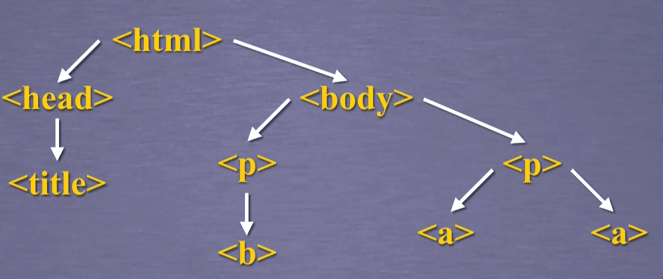

>>> soup.head #获取soup的head
<head><title>This is a python demo page</title></head>
>>> soup.head.contents #获取head的儿子结点
[<title>This is a python demo page</title>]
>>> soup.body.contents #获取body的儿子结点
['\n', <p class="title"><b>The demo python introduces several python courses.</b></p>, '\n', <p class="course">Python is a wonderful general-purpose programming language. You can learn Python from novice to professional by tracking the following courses:<a class="py1" href="http://www.icourse163.org/course/BIT-268001" id="link1">Basic Python</a> and <a class="py2" href="http://www.icourse163.org/course/BIT-1001870001" id="link2">Advanced Python</a>.</p>, '\n']
>>>
>>> len(soup.body.contents) #获取儿子结点的个数
5
>>>
4. 标签树的上行遍历


5. 标签树的平行遍历

平行遍历发生在同一个父节点下的各节点间。
6. find_all()方法

soup内容如下:
1、查找soup中所有的a标签:
 、
、
2、同时查找soup中所有的a标签和b标签

3、recursive参数对子孙全部检索

4、正则表示式查找 b 开头的标签

4、用name和attrs两个参数查找含有指定字符串的标签

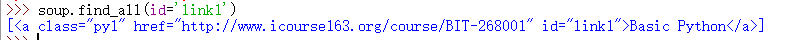
5、string参数检索指定字符串

爬虫系列之BeautifulSoup的更多相关文章
- python3爬虫系列19之反爬随机 User-Agent 和 ip代理池的使用
站长资讯平台:python3爬虫系列19之随机User-Agent 和ip代理池的使用我们前面几篇讲了爬虫增速多进程,进程池的用法之类的,爬虫速度加快呢,也会带来一些坏事. 1. 前言比如随着我们爬虫 ...
- Python爬虫系列(七):提高解析效率
如果仅仅因为想要查找文档中的<a>标签而将整片文档进行解析,实在是浪费内存和时间.最快的方法是从一开始就把<a>标签以外的东西都忽略掉. SoupStrainer 类可以定义文 ...
- 爬虫系列:连接网站与解析 HTML
这篇文章是爬虫系列第三期,讲解使用 Python 连接到网站,并使用 BeautifulSoup 解析 HTML 页面. 在 Python 中我们使用 requests 库来访问目标网站,使用 Bea ...
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
- java爬虫系列第一讲-爬虫入门
1. 概述 java爬虫系列包含哪些内容? java爬虫框架webmgic入门 使用webmgic爬取 http://ady01.com 中的电影资源(动作电影列表页.电影下载地址等信息) 使用web ...
- java爬虫系列目录
1. java爬虫系列第一讲-爬虫入门(爬取动作片列表) 2. java爬虫系列第二讲-爬取最新动作电影<海王>迅雷下载地址 3. java爬虫系列第三讲-获取页面中绝对路径的各种方法 4 ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- Python3爬虫系列:理论+实验+爬取妹子图实战
Github: https://github.com/wangy8961/python3-concurrency-pics-02 ,欢迎star 爬虫系列: (1) 理论 Python3爬虫系列01 ...
- 爬虫系列4:Requests+Xpath 爬取动态数据
爬虫系列4:Requests+Xpath 爬取动态数据 [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]:参 ...
随机推荐
- 20165305 Linux安装及学习
一.虚拟机的安装 在根据老师所给的<基于VirtualBox虚拟机安装Ubuntu图文教程>的时候,我发现虚拟化处于被禁用状态,于是我在网上查找了一下解决办法,在我将bios中虚拟化设置为 ...
- linux常用命令:cd 命令
Linux cd 命令可以说是Linux中最基本的命令语句,其他的命令语句要进行操作,都是建立在使用 cd 命令上的.所以,学习Linux 常用命令,首先就要学好 cd 命令的使用方法技巧. 1. 命 ...
- Vector集合——单列集合的“祖宗”类
是实现可增长的对象数组:所以底层也是数组: 与collection集合不同的是,vector是同步的,意味着是单线程的,意味着效率低,速度慢, 所以在jdk1.2版本之后被ArrayList集合所取代 ...
- js如何获取服务器端时间?
用js做时间校正,获取本机时间,是存在bug的. 使用js也可获取到服务器时间,原理是使用 ajax请求,返回的头部信息就含有服务器端的时间信息,获取到就可以了.以下: 1.依赖jQuery 代码: ...
- 记账本微信小程序开发二
新建一个微信小程序项目 熟悉软件各种操作.
- Django框架----模板语法
Django模板系统 官方文档 一.什么是模板? 只要是在html里面有模板语法就不是html文件了,这样的文件就叫做模板. 二.模板语法分类 只需要记两种特殊符号: {{ }}和 {% %} 变量 ...
- MySQL5.7 的新特点
1.安全性 MySQL 5.7 的目标是成为发布以来最安全的 MySQL 服务器,其在 SSL/TLS 和全面安全开发方面有一些重要的改变. mysql.user表结构升级 MySQL5.7用户表my ...
- An Example of How Oracle Works
Oracle是怎么工作的,摘自Oracle 9i的官方文档 The following example describes the most basic level of operations tha ...
- SQL介绍
SQL,即structured query language,结构化查询语言,是一种对关系型数据库中的数据进行管理和操作的语言方法,SQL包括6个部分 DQL:数据查询语言,最常用的为select,其 ...
- P2387 [NOI2014]魔法森林(LCT)
P2387 [NOI2014]魔法森林 LCT边权维护经典题 咋维护呢?边化为点,边权变点权. 本题中我们把边对关键字A进行排序,动态维护关键字B的最小生成树 加边后出现环咋办? splay维护最大边 ...