(C)高级排序法
1.快速排序法
//方法1 从大到小
#include <iostream.h>
void run(int* pData,int left,int right)
{
int i,j;
int middle,iTemp;
i = left;
j = right;
middle = pData[(left+right)/]; //求中间值
do{
while((pData[i]<middle) && (i<right))//从左扫描大于中值的数
i++;
while((pData[j]>middle) && (j>left))//从右扫描大于中值的数
j--;
if(i<=j)//找到了一对值
{
//交换
iTemp = pData[i];
pData[i] = pData[j];
pData[j] = iTemp;
i++;
j--;
}
}while(i<=j);//如果两边扫描的下标交错,就停止(完成一次) //当左边部分有值(left<j),递归左半边
if(left<j)
run(pData,left,j);
//当右边部分有值(right>i),递归右半边
if(right>i)
run(pData,i,right);
} void QuickSort(int* pData,int Count)
{
run(pData,,Count-);
} void main()
{
int data[] = {,,,,,,};
QuickSort(data,);
for (int i=;i<;i++)
cout<<data[i]<<" ";
cout<<"\n";
}
快速排序 方法1
//方法2 从大到小
//参照《数据结构》(C语言版)
//调用:quicksort-->qsort-->partitions
int partitions(int a[],int low,int high){
int pivotkey=a[low]; //*从数组的最左边开始作中间值
//a[0]=a[low];
while(low<high){
while(low<high && a[high]>=pivotkey) --high;
a[low]=a[high];
while(low<high && a[low]<=pivotkey) ++low;
a[high]=a[low];
}
//a[low]=a[0];
a[low]=pivotkey;
return low;
}
void qsort(int a[],int low,int high){
int pivottag;
if(low<high){
//递归调用
pivottag=partitions(a,low,high);
qsort(a,low,pivottag-);
qsort(a,pivottag+,high);
}
}
void quicksort(int a[],int n){
qsort(a,,n);
}
//简单示例
#include <stdio.h>
//#include <math.h>
#include "myfunc.h" //存放于个人函数库中
int main(void){
int i,a[]={,,,,,,,,,,};
for(i=;i<;printf("%3d",a[i]),++i);
printf("\n");
quicksort(a,);
for(i=;i<;printf("%3d",a[i]),++i);
printf("\n");
}
快速排序 方法2
正如其名快速排序,其效率也是比较高的,时间复杂度为O(nlogn)。其算法思想是每次确定一个基准值的位置,也就是函数int Partition(int a[],int p,int r)的作用。然后通过递归不断地确定基准值两边的子数组的基准值的位置,直到数组变得有序。
2.希尔排序法
void ShellSort(int *array,int length)
{
int d = length/; //设置希尔排序的增量
/* 求“增量”的公式 h(n+1)=3*h(n)+1,(h>N/9停止)这个公式可能选择增量不是最合适,但是却适用一般“增量”的设定 */
int i ;
int j;
int temp;
while(d>=)
{
for(i=d;i<length;i++) // 小序列里的直接插入排序
{
temp=array[i];
j=i-d;
while(j>= && array[j]>temp)
{
array[j+d]=array[j];
j=j-d;
}
array[j+d] = temp;
}
//Display(array,10);
d= d/; //缩小增量
}
}
希尔排序
首先需要一个递减的步长。工作原理是首先对相隔d个元素的所有内容排序,然后再使用同样的方法对相隔d/2个的元素排序,以此类推。
先取一个小于n的整数d1作为第一个增量,把文件的全部记录分成d1个组。所有距离为d1的倍数的记录放在同一个组中。先在各组内进行直接插入排序;然后,取第二个增量d2<d1重复上述的分组和排序,直至所取的增量dt=1(dt<dt-l<…<d2<d1),即所有记录放在同一组中进行直接插入排序为止。
3.双向冒泡法
#include <iostream.h>
void Bubble2Sort(int* pData,int Count)
{
int iTemp;
int left = ;
int right =Count -;
int t;
do
{
//正向的部分
for(int i=right;i>=left;i--)
{
if(pData[i]<pData[i-])
{
iTemp = pData[i];
pData[i] = pData[i-];
pData[i-] = iTemp;
t = i;
}
}
left = t+; //反向的部分
for(i=left;i<right+;i++)
{
if(pData[i]<pData[i-])
{
iTemp = pData[i];
pData[i] = pData[i-];
pData[i-] = iTemp;
t = i;
}
}
right = t-;
}while(left<=right);
} void main()
{
int data[] = {,,,,,,};
Bubble2Sort(data,);
for (int i=;i<;i++)
cout<<data[i]<<" ";
cout<<"\n";
}
双向冒泡
以整数升序排序为例来简单说明一下双向冒泡排序的过程:首先从前往后把最大数移到最后,然后反过来从后往前把最小的一个数移动到数组最前面,这一过程就是第一轮,然后重复这一过程,最终就会把整个数组从小到大排列好。双向冒泡排序要稍微优于传统的冒泡排序,因为双向排序时数组的两头都排序好了,我们只需要处理数组的中间部分即可,而单向即传统的冒泡排序只有尾部的元素是排好序的,这时每轮处理都需要从头一直处理到已经排好序元素的前面一个元素。虽然它在效率上有了点改进,但它也不能大幅度提高其排序的效率,这是由冒泡排序的基本过程所决定了的。

4.堆排序法
//堆排序
////////////////////////////////////////////////////////////////////////////
int Parent(int i)
{
return i/;
}
int Left(int i)
{
return *i;
}
int Right(int i)
{
return *i+;
} //把以第i个节点给子树的根的子树调整为堆
void MaxHeap(int *a,int i,int length)
{
int L=Left(i);
int R=Right(i);
int temp;
int largest; //记录子树最大值的下表,值可能为根节点下标、左子树下表、右子树下标
if (L<=length&&a[L-]>a[i-]) //length是递归返回的条件
{
largest=L;
}
else largest=i;
if (R<=length&&a[R-]>a[largest-]) //length是递归返回的条件
largest=R;
if (largest!=i)
{
temp=a[i-];
a[i-]=a[largest-];
a[largest-]=temp;
MaxHeap(a,largest,length);
}
} void BuildMaxHeap(int *a,int length)
{ for (int i=length/;i>=;i--)
MaxHeap(a,i,length);
} void HeapSort(int *a,int length)
{
BuildMaxHeap(a,length);
for (int i=length;i>;i--)
{
int temp;
temp=a[i-];
a[i-]=a[];
a[]=temp;
length-=;
MaxHeap(a,,length);
}
}
堆排序
其实堆排序是简单选择排序的一种进化,它最主要是减少比较的次数。什么是堆?若将序列对应看成一个完全二叉树,完全二叉树中所有非终端节点的值均不大于(或者不小于)其左右孩子节点的值,可以称作为堆。由堆的性质可以知道堆顶是一个最大关键字(或者最小关键字)。在输出堆顶后,使剩下的元素又建成一个堆,然后在输出对顶。如此反复执行,便能得到一个有序序列,这个过程成便是堆排序。堆排序主要分为两个步骤:(1)从无序序列建堆。(2)输出对顶元素,在调成一个新堆。
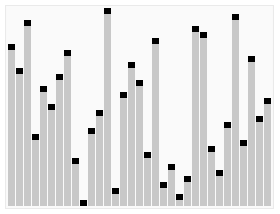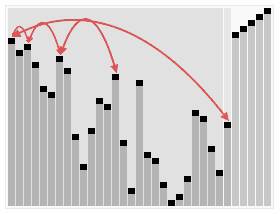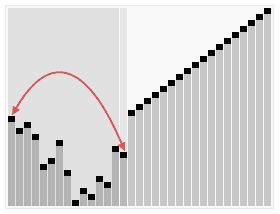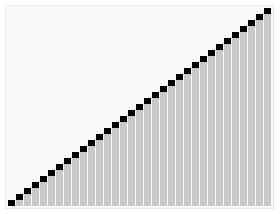
5.归并排序法
//归并排序
void MergeSort(int b[],int d[],int min,int max)
{
//用与存放中间分区域得到的序列
int c[];
void Merge(int c[],int d[],int min,int mid,int max);
if(min==max)d[min]=b[min];
else
{
//平分成两个区域
int mid=(min+max)/;
//将这个区域进行归并排序
MergeSort(b,c,min,mid);
//将这个区域进行归并排序
MergeSort(b,c,mid+,max);
//两个区域归并
Merge(c,d,min,mid,max);
}
} //将有序序列d[min-mid]与d[mid+1-max]归并成有序序列c[min-max]
void Merge(int c[],int d[],int min,int mid,int max)
{
int i,j,k;
for(i=j=min,k=mid+;j<=mid&&k<=max;i++)
{
if(c[j]>c[k])
{
d[i]=c[k];
k++;
}
else
{
d[i]=c[j];
j++;
}
}
if(j<=mid)
{
for(;j<=mid;j++,i++)
{
d[i]=c[j];
}
}
if(k<=max)
{
for(;k<=max;k++,i++)
{
d[i]=c[k];
}
}
}
归并排序
假设初始序列含有n个记录,则可看成n个有序的子序列,每个子序列长度为1,然后两两归并,得到[n/2]个长度为2或者为1(这里长度为1可能这里序列长度是奇数,那么最后一个序列就落单了,所以长度为1);在两两归并,如此重复,直至得到一个长度为n的有序序列为止。

6.基数排序法
//基数排序
/////////////////////////////////////////////////
int GetMaxTimes(int *a,int n)
{
int max=a[];
int count=;
for (int i=;i<n;i++)
{
if(a[i]>max)
max=a[i];
}
while(max)
{
max=max/;
count++;
}
return count;
} void InitialArray(int *a,int n)
{
for (int i=;i<n;i++)
a[i]=;
} // void InitialArray1(int a[][],int m,int n)
// {
// for (int i=0;i<m;i++)
// for (int j=0;j<n;j++)
// a[i][j]=0;
// } void RadixSort(int *a,int n)
{
int buckets[][]={};
int times=GetMaxTimes(a,n);
int index,temp;
int record[]={};
for (int i=;i<times;i++)
{
int count=;
temp=pow(,i);//index=(a[j]/temp)%10;用来从低位到高位分离
for (int j=;j<n;j++)
{
index=(a[j]/temp)%;
buckets[index][record[index]++]=a[j];
}
//把桶中的数据按顺序还原到原数组中
for(int k=;k<;k++)
for (int m=;m<;m++)
{
if(buckets[k][m]==)break;
else
{
a[count++]=buckets[k][m];
//cout<<buckets[k][m]<<" ";
}
}
//重新初始化桶,不然前后两次排序之间会有影响
//buckets[10][10000]={0};
//record[10]={0};
//InitialArray1(buckets,10,10000);
for (k=;k<;k++)
for (int m=;m<;m++)
{
if(buckets[k][m]==)break;
else buckets[k][m]=;
}
InitialArray(record,);
}
}
基数排序
最后一种是比较特别的基数排序(属于分配式排序,前几种属于比较性排序)又称“桶子法”,基本思想是通过键值的部分信息分配到某些桶中,藉此达到排序的作用,基数排序属于稳定的排序,其时间复杂度为O(nlog(r)m),r为所采取的的基数,m为堆的个数,在某些情况下基数排序法的效率比其他比较性排序效率要高。

推荐文章:
http://www.cnblogs.com/maxiaofang/p/3381692.html
http://zh.wikipedia.org/wiki/%E6%8E%92%E5%BA%8F%E7%AE%97%E6%B3%95
(C)高级排序法的更多相关文章
- javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法)
javascript数据结构与算法--高级排序算法(快速排序法,希尔排序法) 一.快速排序算法 /* * 这个函数首先检查数组的长度是否为0.如果是,那么这个数组就不需要任何排序,函数直接返回. * ...
- 【高级排序算法】1、归并排序法 - Merge Sort
归并排序法 - Merge Sort 文章目录 归并排序法 - Merge Sort nlogn 比 n^2 快多少? 归并排序设计思想 时间.空间复杂度 归并排序图解 归并排序描述 归并排序小结 参 ...
- JAVA基础学习之命令行方式、配置环境变量、进制的基本转换、排序法、JAVA文档生成等(1)
1.命令行方式 dos命令行,常见的命令: dir:列出当前目录下的文件以及文件夹 md:创建目录 rd:删除目录 cd:进入指定目录 cd..:退回到上一级目录 cd/:退回到根目录 del:删除文 ...
- 【Python】 sort、sorted高级排序技巧
文章转载自:脚本之家 这篇文章主要介绍了python sort.sorted高级排序技巧,本文讲解了基础排序.升序和降序.排序的稳定性和复杂排序.cmp函数排序法等内容,需要的朋友可以参考下 Pyth ...
- C++常用排序法、随机数
C++常用排序法研究 2008-12-25 14:38 首先介绍一个计算时间差的函数,它在<time.h>头文件中定义,于是我们只需这样定义2个变量,再相减就可以计算时间差了. 函数开头加 ...
- python requests高级耍法
昨天,我们更多的讨论了request的基础API,让我们对它有了基础的认知.学会上一课程,我们已经能写点基本的爬虫了.但是还不够,因为,很多站点是需要登录的,在站点的各个请求之间,是需要保持回话状态的 ...
- 【转载】 python sort、sorted高级排序技巧
这篇文章主要介绍了python sort.sorted高级排序技巧,本文讲解了基础排序.升序和降序.排序的稳定性和复杂排序.cmp函数排序法等内容,需要的朋友可以参考下 Python list内置so ...
- Word 查找替换高级玩法系列之 -- 把论文中的缩写词快速变成目录下边的注释表
1. 前言 问题:Word写论文如何把文中的缩写快速转换成注释表? 原来样子: 想要的样子: 2. 步骤 使用查找替换高级用法,替换缩写顺序 选中所有文字 打开查找替换对话框,输入以下表达式: 替换后 ...
- Python爬虫系列(三):requests高级耍法
昨天,我们更多的讨论了request的基础API,让我们对它有了基础的认知.学会上一课程,我们已经能写点基本的爬虫了.但是还不够,因为,很多站点是需要登录的,在站点的各个请求之间,是需要保持回话状态的 ...
随机推荐
- g711u与g729比較编码格式
•711a-编解码格式为G.711 alaw •g711u-编解码格式为G.711 ulaw (the default) •g729-编解码格式为G.729 •g729a-编解码格式为G.729a 上 ...
- svn+ssh
According to official document, svn+ssh is supposed to be somehow faster than apache+dav_svn, howeve ...
- HDU1250:Hat's Fibonacci
Problem Description A Fibonacci sequence is calculated by adding the previous two members the sequen ...
- MVC Razor中 如何截断字符串
有时候显示的内容过长,使用MVC编程时,如何截断显示的内容呢.我知道你肯定有很多办法这样做的,但是在学习MVC时,还是使用一些新的办法做吧> Razor 标记语法编程. @helper Trun ...
- 【转】CoreData以及MagicalRecord (二)
3. 运行时类与对象 NSManagedObject Managed Object 表示数据文件中的一条记录,每一个Managed Object在内存中对应的实体(Entity)的一个数据表示.Man ...
- iOS 中多线程的简单使用
iOS中常用的多线程操作有( NSThread, NSOperation GCD ) 为了能更直观的展现多线程操作在SB中做如下的界面布局: 当点击下载的时候从网络上下载图片: - (void)loa ...
- [C#绘图]在半透明矩形上绘制字符串
首先要绘制一个半透明的矩形,用到的方法当然是FillRectangle().这个函数在调用的时候除了要指明要绘制的矩形外,还要指明填充矩形的背景色.具体的方法就是在绘制矩形的时候传给它一个画刷Brus ...
- 两种写法实现Session Scope的Spring Bean
xml based: <bean id="localRepository" class="com.demo.bean.LocalRepository" s ...
- Dokcer 组成原理简介
首先来张图了解Docker的组成 重要 Docker在启动容器的时候,需要创建文件系统,为rootfs提供挂载点.最初Docker仅能在支持Aufs文件系统的Linux发行版上运行,但是由于Aufs未 ...
- (C#)Windows Shell 外壳编程系列7 - ContextMenu 注册文件右键菜单
原文 (C#)Windows Shell 外壳编程系列7 - ContextMenu 注册文件右键菜单 (本系列文章由柠檬的(lc_mtt)原创,转载请注明出处,谢谢-) 接上一节:(C#)Windo ...