Tesseract 3.02中文字库训练
Tesseract 3.02中文字库训练
下载chi_sim.traindata字库
下载tesseract-ocr-setup-3.02.02.exe
下载jTessBoxEditor用于修改box文件
0.准备
为了方便 tif文面命名格式[lang].[fontname].exp[num].tif
lang是语言 fontname是字体
比如我们要训练自定义字库 mjorcen字体名normal
那么我们把tif文件重命名 mjorcen.normal.exp0.jpg
图片 :
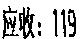
下面开始训练字库:
1、生成 .box文件
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l chi_sim batch.nochop makebox
把图片文件和box文件放在同一目录,
2、用jTessBoxEditor.jar打开tif文件,然后根据实际情况修改box文件

3、 生成 .tr文件
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 nobatch box.train
4、成一个unicharset文件
unicharset_extractor mjorcen.normal.exp0.box
5、新建一个font_properties文件
里面内容写入 normal 0 0 0 0 0 表示默认普通字体
6、运行命令
shapeclustering -F font_properties -U unicharset mjorcen.normal.exp0.tr mftraining -F font_properties -U unicharset -O unicharset mjorcen.normal.exp0.tr cntraining mjorcen.normal.exp0.tr
结果如下:
E:\data\Users\Administrator\Desktop\ocrBuider3>shapeclustering -F font_propertie
s -U unicharset mjorcen.normal.exp0.tr
Reading mjorcen.normal.exp0.tr ...
Building master shape table
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 0.365385
Master shape_table:Number of shapes = max unichars = number with multiple un
ichars = E:\data\Users\Administrator\Desktop\ocrBuider3>mftraining -F font_properties -U
unicharset -O unicharset mjorcen.normal.exp0.tr
Read shape table shapetable of shapes
Reading mjorcen.normal.exp0.tr ...
Done! E:\data\Users\Administrator\Desktop\ocrBuider3>cntraining mjorcen.normal.exp0.tr Reading mjorcen.normal.exp0.tr ...
Clustering ... Writing normproto ...
7、把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件前面都加上normal.
8、执行combine_tessdata normal.
9、把 normal.traineddata 复制到Tesseract-OCR 安装目录下的tessdata文件夹中
10、测试
tesseract mjorcen.normal.exp0.jpg mjorcen.normal.exp0 -l normal
debug:
E:\data\Users\Administrator\Desktop\ocrBuider3>tesseract mjorcen.normal.exp0.jpg
mjorcen.normal.exp0 -l chi_sim batch.nochop makebox
Too many unichars in ambiguity on line
Too many unichars in ambiguity on line
Too many unichars in ambiguity on line
Tesseract Open Source OCR Engine v3. with Leptonica E:\data\Users\Administrator\Desktop\ocrBuider3>tesseract mjorcen.normal.exp0.jp
g mjorcen.normal.exp0 nobatch box.train
Tesseract Open Source OCR Engine v3. with Leptonica
APPLY_BOXES:
Boxes read from boxfile:
Found good blobs.
TRAINING ... Font name = normal
Generated training data for words E:\data\Users\Administrator\Desktop\ocrBuider3>unicharset_extractor mjorcen.norm
al.exp0.box
Extracting unicharset from mjorcen.normal.exp0.box
Wrote unicharset file ./unicharset. E:\data\Users\Administrator\Desktop\ocrBuider3>shapeclustering -F font_propertie
s -U unicharset mjorcen.normal.exp0.tr
Reading mjorcen.normal.exp0.tr ...
Building master shape table
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 0.365385
Master shape_table:Number of shapes = max unichars = number with multiple un
ichars = E:\data\Users\Administrator\Desktop\ocrBuider3>mftraining -F font_properties -U
unicharset -O unicharset mjorcen.normal.exp0.tr
Read shape table shapetable of shapes
Reading mjorcen.normal.exp0.tr ...
Done! E:\data\Users\Administrator\Desktop\ocrBuider3>cntraining mjorcen.normal.exp0.tr Reading mjorcen.normal.exp0.tr ...
Clustering ... Writing normproto ... E:\data\Users\Administrator\Desktop\ocrBuider3>combine_tessdata normal.
Combining tessdata files
TessdataManager combined tesseract data files.
Offset for type is -
Offset for type is
Offset for type is -
Offset for type is
Offset for type is
Offset for type is
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is
Offset for type is -
Offset for type is -
Offset for type is - E:\data\Users\Administrator\Desktop\ocrBuider3>tesseract mjorcen.normal.exp0.jpg
mjorcen.normal.exp0 -l normal
Tesseract Open Source OCR Engine v3. with Leptonica E:\data\Users\Administrator\Desktop\ocrBuider3>tesseract mjorcen.normal.exp0.jpg
mjorcen.normal.exp1 -l chi_sim
Too many unichars in ambiguity on line
Too many unichars in ambiguity on line
Too many unichars in ambiguity on line
Tesseract Open Source OCR Engine v3. with Leptonica
normal 结果
应收:
普通的中文结果:
应收= II苜
脚本(需要java环境):
目录结果如下:

脚本如下:
window
@echo off set "src=%1%"
set "font_name=%2%"
set "desc=%3%" if not defined src set /p src=" please pass your filename : " if not defined font_name set /p font_name=" please pass your font_name : " rem 判断参数的合法性 if not defined src echo IllegalArgumentException arg1 must not be null & pause>nul & exit if not defined font_name echo IllegalArgumentException arg2 must not be null & pause>nul & exit if not defined desc set "desc=%src:~0,-4%" echo desc %desc% rem 如果目录下没有font_properties 文件创建 font_properties ,并写入文件
if exist font_properties (
echo font_properties exist
) else (
ECHO %font_name% >"font_properties"
) rem 删除原有文件
if exist %font_name%.unicharset ECHO DEL %font_name%.unicharset & DEL /Q names %font_name%.unicharset
if exist %font_name%.inttemp ECHO DEL %font_name%.inttemp & DEL /Q names %font_name%.inttemp
if exist %font_name%.pffmtable ECHO DEL %font_name%.pffmtable & DEL /Q names %font_name%.pffmtable
if exist %font_name%.shapetable ECHO DEL %font_name%.shapetable & DEL /Q names %font_name%.shapetable
if exist %font_name%.normproto ECHO DEL %font_name%.normproto & DEL /Q names %font_name%.normproto
if exist %font_name%.font_properties ECHO DEL %font_name%.font_properties & DEL /Q names %font_name%.font_properties rem makebox tesseract %src% %desc% -l chi_sim batch.nochop makebox java -Xms128m -Xmx512m -jar jTessBoxEditor/jTessBoxEditor.jar ECHO Please change your results , and press any key to continue pause>nul tesseract %src% %desc% nobatch box.train unicharset_extractor %desc%.box shapeclustering -F font_properties -U unicharset %desc%.tr mftraining -F font_properties -U unicharset -O unicharset %desc%.tr cntraining %desc%.tr rem 配置新文件
if exist unicharset ECHO rename unicharset %font_name%.unicharset & rename unicharset %font_name%.unicharset
if exist inttemp ECHO rename inttemp %font_name%.inttemp & rename inttemp %font_name%.inttemp
if exist pffmtable ECHO rename pffmtable %font_name%.pffmtable & rename pffmtable %font_name%.pffmtable
if exist shapetable ECHO rename shapetable %font_name%.shapetable & rename shapetable %font_name%.shapetable
if exist normproto ECHO rename normproto %font_name%.normproto & rename normproto %font_name%.normproto combine_tessdata %font_name%. if exist font_properties ECHO rename font_properties %font_name%.font_properties & rename font_properties %font_name%.font_properties ECHO press any key to continue
pause>nul
调用:
注意: 参数1: 文件全名 , 参数2 字体名, 参数3 :输出文件名, 不填默认为文件名
E:\data\Users\Administrator\Desktop\ocrBuider3>run.bat mjorcen.normal.exp0.jpg normal
实例:
E:\data\Users\Administrator\Desktop\ocrBuider3>run.bat mjorcen.normal.exp0.jpg n
ormal
desc mjorcen.normal.exp0
font_properties exist
Too many unichars in ambiguity on line
Too many unichars in ambiguity on line
Too many unichars in ambiguity on line
Tesseract Open Source OCR Engine v3. with Leptonica
Please change your results , and press any key to continue
Tesseract Open Source OCR Engine v3. with Leptonica
APPLY_BOXES:
Boxes read from boxfile:
Found good blobs.
TRAINING ... Font name = normal
Generated training data for words
Extracting unicharset from mjorcen.normal.exp0.box
Wrote unicharset file ./unicharset.
Reading mjorcen.normal.exp0.tr ...
Building master shape table
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 999.000000
Computing shape distances...
Stopped with merged, min dist 0.365385
Master shape_table:Number of shapes = max unichars = number with multiple un
ichars =
Read shape table shapetable of shapes
Reading mjorcen.normal.exp0.tr ...
Done!
Reading mjorcen.normal.exp0.tr ...
Clustering ... Writing normproto ...
rename unicharset normal.unicharset
rename inttemp normal.inttemp
rename pffmtable normal.pffmtable
rename shapetable normal.shapetable
rename normproto normal.normproto
Combining tessdata files
TessdataManager combined tesseract data files.
Offset for type is -
Offset for type is
Offset for type is -
Offset for type is
Offset for type is
Offset for type is
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is -
Offset for type is
Offset for type is -
Offset for type is -
Offset for type is -
rename font_properties normal.font_properties
E:\data\Users\Administrator\Desktop\ocrBuider3>
linux (出自文档:http://tesseract-ocr.googlecode.com/svn/trunk/doc/combine_tessdata.1.asc) :
#!/bin/bash
tesseract zzz.ocra.exp0.tif zzz.ocra.exp0 nobatch box.train
unicharset_extractor zzz.ocra.exp0.box
echo "ocra 0 0 1 0 0" >font_properties
shapeclustering -F font_properties -U unicharset zzz.ocra.exp0.tr
mftraining -F font_properties -U unicharset -O zzz.unicharset zzz.ocra.exp0.tr
cntraining zzz.ocra.exp0.tr
cp normproto zzz.normproto
cp inttemp zzz.inttemp
cp pffmtable zzz.pffmtable
cp shapetable zzz.shapetable
combine_tessdata zzz.
cp zzz.traineddata /home/youruserid/tessdata/.
sudo cp zzz.traineddata /usr/share/tesseract-ocr/tessdata/.
tesseract zzz.ocra.exp0.tif output -l zzz
Tesseract 3.02中文字库训练的更多相关文章
- [转]Tesseract 3.02中文字库训练
下载chi_sim.traindata字库下载tesseract-ocr-setup-3.02.02.exe 下载地址:http://code.google.com/p/tesseract-ocr/d ...
- jTessBoxEditor工具进行Tesseract3.02.02样本训练
1.背景 前文已经简要介绍tesseract ocr引擎的安装及基本使用,其中提到使用-l eng参数来限定语言库,可以提高识别准确率及识别效率. 本文将针对某个网站的验证码进行样本训练,形成自己的语 ...
- 利用jTessBoxEditor工具进行Tesseract3.02.02样本训练,提高验证码识别率
1.背景 前文已经简要介绍tesseract ocr引擎的安装及基本使用,其中提到使用-l eng参数来限定语言库,可以提高识别准确率及识别效率. 本文将针对某个网站的验证码进行样本训练,形成自己的语 ...
- tesseract 中文二次训练
tesseract4.0以上版本可参考 https://github.com/tesseract-ocr/tesseract/wiki/TrainingTesseract-4.00#tutorial- ...
- 2019.01.02 NOIP训练 三七二十一(生成函数)
传送门 生成函数基础题. 题意简述:求由1,3,5,7,9这5个数字组成的n位数个数,要求其中3和7出现的次数都要是偶数. 考虑对于每个数字构造生成函数. 对于1,5,9:∑nxnn!=ex\sum_ ...
- 2018.11.02 NOIP训练 停车场(线段树)
传送门 这是一道困饶了我一年的题. 其实就是去年去NOIP提高组试水的时候考的模拟题 但当时我水平不够,跟ykykyk一起杠了一个下午都没调出来. 今天终于AAA了. 其实就是一个维护最长连续0101 ...
- Tesseract识别图片提取文字&字库训练
文中测试了3.0和4.0两个版本.发现3.0识别效率不准确,需要训练词库.4.0识别效率就比较高了,而且支持结果生成pdf.txt等格式.所以推荐使用4.0版本. 这个工具可以用在爬虫的时候获取验证码 ...
- 深入学习Tesseract-ocr识别中文并训练字库的方法
上篇文章简单的学习了tesseract-ocr识别图片中的英文(链接地址如下:https://www.cnblogs.com/wj-1314/p/9428909.html),看起来效果还不错,所以这篇 ...
- C#识别验证码技术-Tesseract
相信大家在开发一些程序会有识别图片上文字(即所谓的OCR)的需求,比如识别车牌.识别图片格式的商品价格.识别图片格式的邮箱地址等等,当然需求最多的还是识别验证码.如果要完成这些OCR的工作,需要你掌握 ...
随机推荐
- java中volatile关键字的含义 (转载)
在java线程并发处理中,有一个关键字volatile的使用目前存在很大的混淆,以为使用这个关键字,在进行多线程并发处理的时候就可以万事大吉. Java语言是支持多线程的,为了解决线程并发的问题,在语 ...
- 2013 ACM/ICPC 长沙现场赛 A题 - Alice's Print Service (ZOJ 3726)
Alice's Print Service Time Limit: 2 Seconds Memory Limit: 65536 KB Alice is providing print ser ...
- 在.bashrc中,使用python获取本机IP地址(现在只支持wlan)
其实最好的办法是写个单独的脚本去查找IP,但是如果实在不愿意单写一个脚本文件,也可以直接将代码嵌入.bashrc中 在~/.bashrc下加入下面这行代码即可使用python获取本机的wlan的IP地 ...
- SQL Server高级内容之表表达式和复习
1. 表表达式 (1) 将表作为一个源或将查询的一个结果集作为一个源,对源做处理,然后得到一个新的数据源,对其进行查询. (2)表表达式放在from子句中 (3)派生表,将表的查询得到的结果集作为一 ...
- 第一篇、Swift_Textkit的基本使用
简介: iOS7 的发布给开发者的案头带来了很多新工具.其中一个就是 TextKit(文本工具箱).TextKit 由许多新的 UIKit 类组成,顾名思义,这些类就是用来处理文本的. 1.NSTex ...
- Objective-C 【类对象及SEL存储方式】
------------------------------------------- 类的本质--类对象 一段代码: #import <Foundation/Foundation.h> ...
- hibernate的dao操作不能提交到数据库问题的解决
刚学的时候总是各种错误,解决方法也无厘头的很 将UserDAO里面的的save方法修改try { getSession().save(transientInstance); log.debug(&qu ...
- [翻译][MVC 5 + EF 6] 7:加载相关数据
原文:Reading Related Data with the Entity Framework in an ASP.NET MVC Application 1.延迟(Lazy)加载.预先(Eage ...
- centos 安装qrcode 二维码
先安装yum install mingw64-pkg-config.x86_64 yum install cairo-devel 然后报错,好像是gcc版本有点低,现在的版本是4.4.7 那么接下来 ...
- jQuery Mobile里xxx怎么用呀?(控件篇)
jQuery Mobile里都有什么控件? http://api.jquerymobile.com/category/widgets/ jQuery Mobile里slider控件的change事件怎 ...