1. 背景
“应用程序运行于Hadoop Yarn之上”的需求来源于微博运维数据平台中的调度系统,即调度系统中的任务需要运行于Hadoop Yarn之上。这里的应用程序可以简单理解为一个普通的进程(这里特指Java进程),调度系统中的任务执行实际也是一个进程的运行过程,这里我们不讨论为什么调度系统中的任务(进程)需要运行于Hadoop Yarn之上,仅仅讨论如何使得一个应用程序(进程)可以运行于Hadoop Yarn之上。
应用程序(进程)需要运行于Hadoop Yarn之上,有三种可选的实现方案:
(1)扩展实现Yarn Application的两个组件:Yarn Client、ApplicationMaster;
(2)重用已有的计算框架,如:MapReduce、Spark;
(3)借助于开源框架,如:Apache Twill;
我们的实现方案最终确定为重用已有的计算框架:MapReduce,主要是基于以下几个因素考虑的:
(1)Yarn Application的Yarn Client、ApplicationMaster的扩展实现过程异常复杂,需要对Hadoop Yarn有非常深入的了解,对于我们的目标而言这种方式过于“大材小用”,毕竟我们只是希望一个普通的Java进程可以运行于Hadoop Yarn之上即可;
(2)Apache Twill及类似的开源框架旨在简化Yarn Application(Yarn Client、ApplicationMaster)的实现过程,但目前均处于孵化器状态,不建议实际环境中使用;
(3)已有的计算框架中,MapReduce、Spark使用都比较广泛,而Spark使用Scala开发,不太适用于团队目前的工程背影及与现有系统整合,因此选取了使用Java开发的MapReduce;
实现方案确定之后,我们的目标不再是“应用程序如何运行于Hadoop Yarn之上”,变为“一个普通的Java进程如何运行于Hadoop Yarn之上”,而MapReduce仅仅包含两种类型的任务:Map Tasks、Reduce Tasks,进一步思考之后,我们得到最终目标:“一个普通的Java进程如何以一个MapReduce MapTask的形式运行于Hadoop Yarn之上”。
为什么是MapTask,而不是ReduceTask?
每一个MapTask、ReduceTask都是一个Java进程,宏观上看,ReduceTask需要运行于MapTask之后,即ReduceTask的运行必须依赖于所有的MapTask结束之后才可以运行。
如果是“一个普通的Java进程以一个MapReduce ReduceTask的形式运行于Hadoop Yarn之上”,则Hadoop Yarn之上至少需要两个进程:一个MapTask进程和一个ReduceTask进程,这与一个普通的Java进程的初衷是不符的,相当于之前只需要一个进程就可以完成的任务,现在至少需要两个进程。
MapReduce是可以不需要ReduceTask的,这可以通过设置Hadoop MapReduce属性“mapreduce.job.reduces”的值为0来实现。
2. 实现
2.1 YarnApplication
一个普通的Java进程现在相当于一个MapReduce MapTask进程,这个“普通的Java进程”的计算逻辑实际可以是多种多样的,这就要求我们需要把MapReduce MapTask进程看作是一个“容器”,运行于其中的应用可以有各种各样的计算逻辑,只有这样MapReduce MapTask的进程才可以等价于一个普通的Java进程,虽然它包含很多额外的执行过程(与应用计算逻辑无关的)。
根据以往的经验,“容器”中的应用通常需要实现特定的接口(Interface或Abstract class),为此我们特意设计了一个抽象类:YarnApplication,用于表示“容器”中的应用。
属性
context:MapReduce MapTask Context(org.apache.hadoop.mapreduce.Mapper.Context<LongWritable, Text, LongWritable, Text>),即:MapReduce Mapper环境上下文,主要用于获取Hadoop MapReduce配置属性值;
方法
setContext:设置MapReduce Mapper Context(环境上下文);
execute:应用的计算逻辑以方法的形式封装至方法execute,该方法可以接受任意个字符串形式的参数;
简而言之,一个普通的Java进程如果想运行于Yarn之上,现在仅仅需要实现自己特有的SpecificApplication,SpecificApplication需要继承自YarnApplication,并重写其中的execute方法,用于表示应用的计算逻辑,然后由“容器”(MapReduce MapTask)负责完成应用的执行过程,即:SpecificApplication execute的方法调用。
2.2 AppMapper
AppMapper是MapReduce Mapper的一个具体实现,它的功能就是2.1中提及的“容器”,用于完成多种多样的YarnApplication的执行过程。
属性
appClass:既然“容器”可以支持多种多样的YarnApplication的执行,那么某一个具体的“容器实例”(即:AppMapper Task)启动时,需要知道具体执行哪一个YarnApplication实例;appClass用于保存YarnApplication实例的完全限定类名,它的具体值可以在Hadoop MapRedcue启动时通过参数“app.class”进行指定;
args:用于表示YarnApplication execute方法执行时需要传递的参数,它的具体值可以在Hadoop MapReduce启动时通过参数“app.args”进行指定;
方法
setup:AppMapper实例的初始化过程中获取appClass与args的具体值;
map:AppMapper实例的具体执行过程,负责完成YarnApplication execute的调用过程;
具体的执行过程分为三步:
(1)通过反射加载具体的YarnApplication实现类,并创建相应的实例app;
(2)实例app设置相应的Mapper环境上下文context;
(3)实例app执行execute方法;
cleanup:暂时没有使用;
这里有一点需要额外注意:AppMapper map没有处理任何的数据输入输出。
2.3 AppInputFormat
AppMapper仅仅需要一个Map Task,因此InputSplit的数目为1;AppMapper map仅仅执行一次,意味着InputSplit的记录数目为1;这样的需求如果使用TextInputFormat,则要求我们必须在HDFS上存储一个文本文件,这个文本文件仅仅包含有一行文本,对于我们的场景而言,太过烦琐,因此我们设计实现了专用的InputFormat:AppInputFormat。
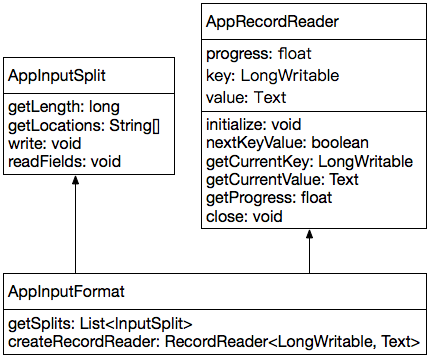
InputFormat需要有两个核心组件组成:InputSplit和RecordReader,AppInputFormat也不例外,如下:
如上所述,AppMapper map没有处理任何的数据输入,因此,AppInputFormat需要的InputSplit可以是“虚拟”的,InputSplit中的记录也可以是“虚拟”的。
2.3.1 AppInputSplit
AppInputSplit就是一个“虚拟”的InputSplit,它没有引用或关联任何实际的数据。
方法
getLength:AppInputSplit是“虚拟”的,没有引用或关联任何实际的数据,因此数据长度为0;
getLocations:AppInputSplit是“虚拟”的,没有引用或关联任何实际的数据,不需要考虑数据本地性的问题,因此仅返回一个“localhost”即可;
write、readFields:AppInputSplit不包括任何实例属性,因为序列化方法(write)和反序列化方法(readFields)为空即可;
2.3.2 AppRecordReader
虽然AppInputSplit是“虚拟”的,但它依然需要一个对应的RecordReader,且这个RecordReader需要能够从AppInputSplit中“读取”到一条记录,否则AppMapper map方法无法得到执行。
属性
progress:表示AppInputSplit的处理进度,因为AppInputSplit仅仅包含一条“虚拟”记录,因此progress只有两个值:0.0和1.0,初始值为0.0;
key:表示AppInputSplit中的那条“虚拟”记录的KEY;
value:表示AppInputSplit中的那条“虚拟”记录的VALUE;
方法
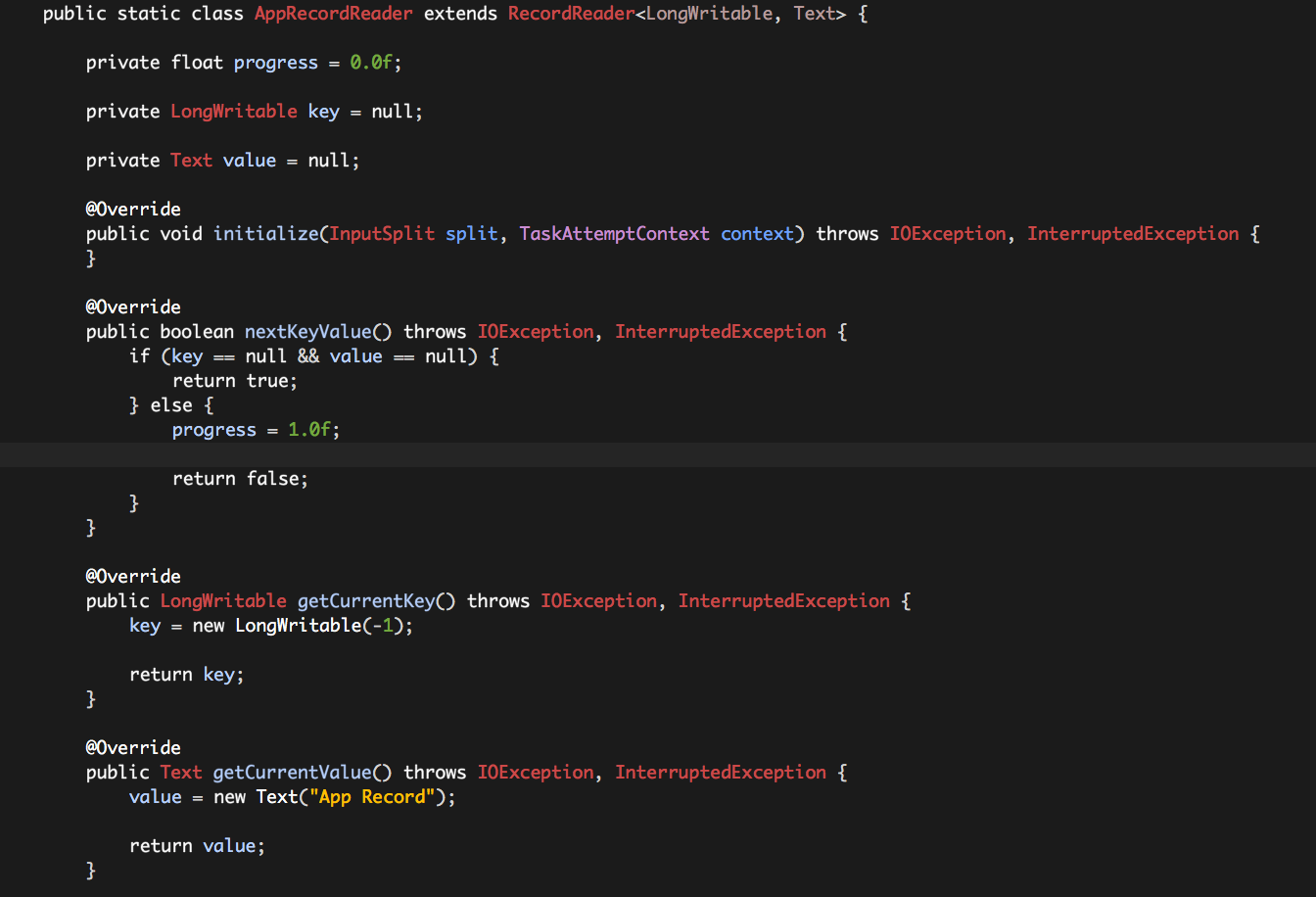
initialize:初始化AppRecordReader实例,为空即可;
nextKeyValue:用于表示AppInputSplit中是否仍有记录可以读取,如果实例变量key和value均为null,表示有一条记录可以读取;否则表示读取完成,progress置为1.0;
getCurrentKey:如果nextKeyValue()方法返回值为true,表示有一条记录可以读取,getCurrentKey()返回这条记录的KEY,因为只有一条记录,我们这里将KEY设置为-1,并保存至实例变量key;
getCurrentValue:如果nextKeyValue()方法返回值为false,表示有一条记录可以读取,getCurrentValue()返回这条记录的VALUE,因为只有一条记录,我们这里将VALUE设置为“APP Record”,并保存至实例变量value;
getProgress:直接返回实例变量progress的值即可;
close:没有使用,为空即可;
这里有一点需要注意,AppRecordReader中并没有使用到AppInputSplit,这是因为AppInputSplit及其中的记录都可以理解为是“虚拟”的,AppRecordReader只需要能够“读取”到一条记录即可,至于这条记录是不是实际包含在AppInputSplit中是无关紧要的。
2.3.3 AppInputFormat
方法
getSplits:AppMapper仅仅需要一个MapTask,因此只需要以数组的形式返回一个AppInputSplit实例即可;
createRecordReader:返回一个AppRecordReader实例即可;
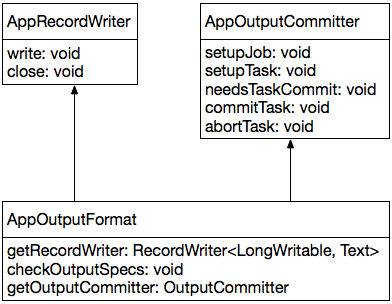
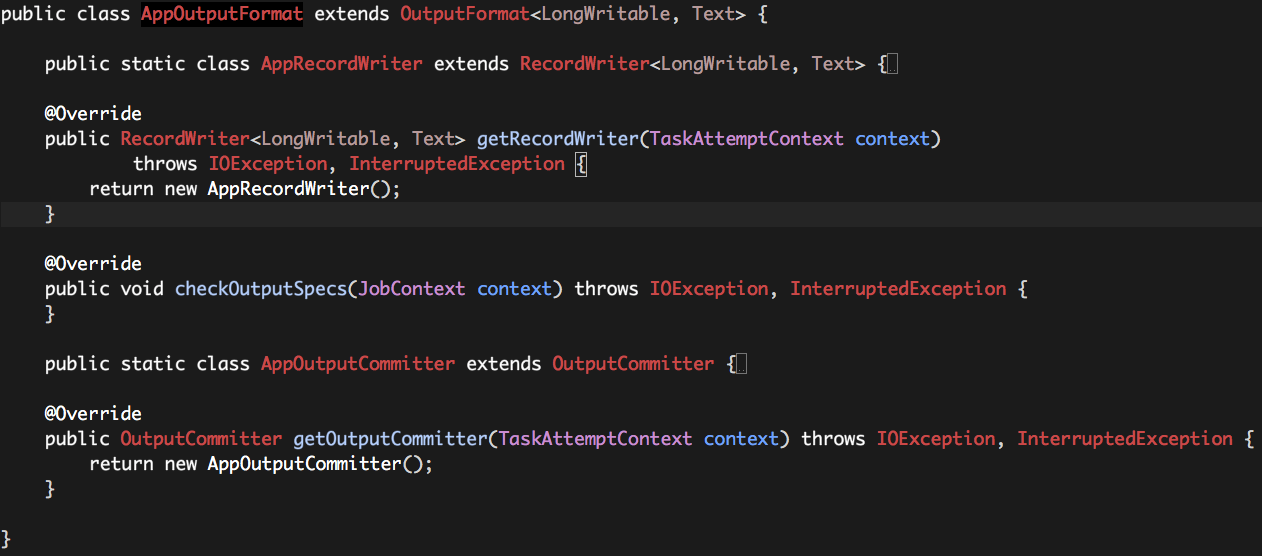
2.4 AppOutputFormat
整个Hadoop MapReduce的运行过程中仅仅只有一个AppMapper Task,而这个唯一的AppMapper Task没有任何输出,因此我们需要一个“空”的OutputFormat:AppOutputFormat。
OutputFormat需要有两个核心组件组成:RecordWriter和OutputCommitter,AppOutputFormat也不例外,如下:
2.4.1 AppRecordWriter
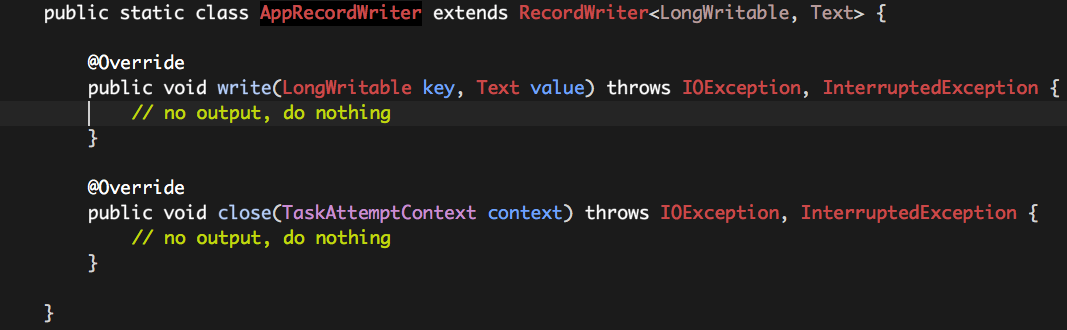
如上所述,因为没有任何数据输出,所以AppRecordWriter中的所有方法为空即可。
2.4.2 AppOutputCommitter
OutputFormat使用OutputCommitter用于“提交”Task的输出,因为没有任何数据输出,所以AppOutputCommitter中的所有方法为空即可。
2.4.3 AppOutputFormat
方法
getRecordWriter:返回一个AppRecordWriter实例即可;
checkOutputSpecs:没有任何数据输出,为空即可;
getOutputCommitter:返回一个AppOutputCommitter实例即可;
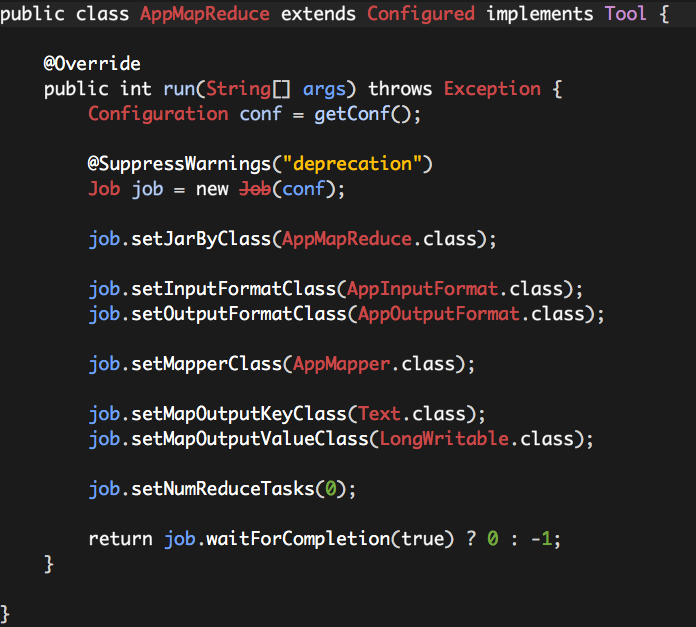
2.5 AppMapReduce
AppMapReduce继承类Configured,并实现接口Tool,相当于MapReduce的一个驱动,可以使用以下的方式来运行:
注:ToolRunner、Configured、Tool是Hadoop MapReduce提供的工具类,方便我们运行Hadoop MapReduce。
综上所述,YarnApplication、AppMapper、AppInputFormat(AppInputSplit、AppRecordReader)、AppOutputFormat(AppRecordWriter、AppOutputCommitter)、AppMapReduce之间的类关系如下图:
3. 示例
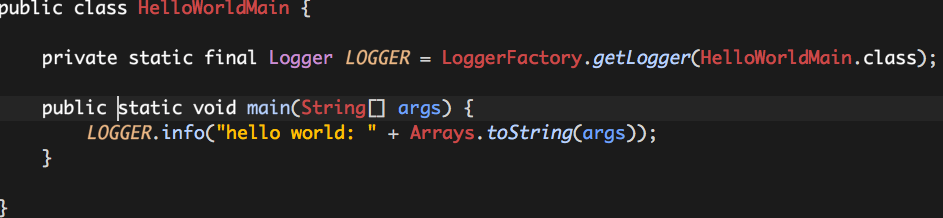
假设我们一个“HelloWorld”的应用,以一个普通的Java进程的实现方式如下:
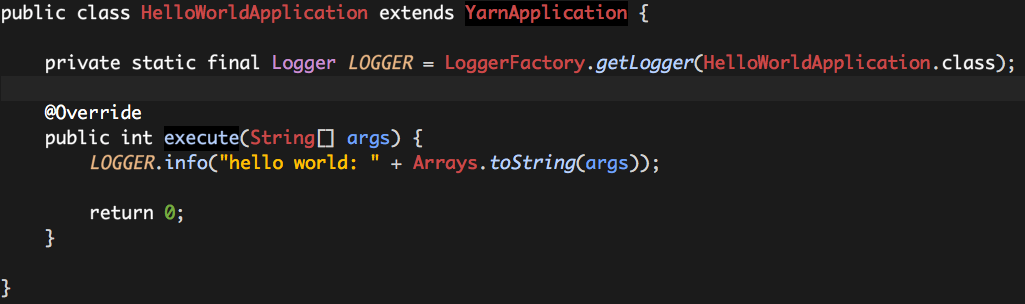
如果想让这个“HelloWorld”的应用运行于Hadoop Yarn之上,我们需要实现一个HelloWorldApplication,它继承自YarnApplication,并重写其中的execute方法:
HelloWorldApplication的运行需要一个“驱动程序”:
这个“驱动程序”的运行方式如下:
java -cp conf/:target/scheduler-on-yarn-0.0.1-SNAPSHOT.jar:target/scheduler-on-yarn-0.0.1-SNAPSHOT-lib/* com.weibo.dip.yarnscheduler.example.HelloWorldApplicationExecutor -conf /etc/hadoop-offline/conf/core-site.xml -conf /etc/hadoop-offline/conf/hdfs-site.xml -conf /etc/hadoop-offline/conf/mapred-site.xml -conf /etc/hadoop-offline/conf/yarn-site.xml -D mapreduce.job.queuename=hive -D app.class=com.weibo.dip.yarnscheduler.app.HelloWorldApplication -D app.args=abc,def,ghi
参数说明:
-conf /etc/hadoop-offline/conf/core-site.xml
-conf /etc/hadoop-offline/conf/hdfs-site.xml
-conf /etc/hadoop-offline/conf/mapred-site.xml
-conf /etc/hadoop-offline/conf/yarn-site.xml
这几个参数用于指定Hadoop集群的配置文件;
-D mapreduce.job.queuename=hive
用于指定Hadoop MapReduce运行于Hadoop Yarn中的哪个队列;
-D app.class=com.weibo.dip.yarnscheduler.app.HelloWorldApplication
用于指定YarnApplication的具体实现类,此处为HelloWorldApplication;
-D app.args=abc,def,ghi
用于指定HelloWorldApplication运行时所需要的参数,多个参数以“,”进行分隔。
代码参考:
- Hadoop YARN架构设计要点
YARN是开源项目Hadoop的一个资源管理系统,最初设计是为了解决Hadoop中MapReduce计算框架中的资源管理问题,但是现在它已经是一个更加通用的资源管理系统,可以把MapReduce计算框 ...
- Hadoop YARN上运行MapReduce程序
(1)配置集群 (a)配置hadoop-2.7.2/etc/hadoop/yarn-env.sh 配置一下JAVA_HOME export JAVA_HOME=/home/hadoop/bigdata ...
- Windows平台开发Mapreduce程序远程调用运行在Hadoop集群—Yarn调度引擎异常
共享原因:虽然用一篇博文写问题感觉有点奢侈,但是搜索百度,相关文章太少了,苦苦探寻日志才找到解决方案. 遇到问题:在windows平台上开发的mapreduce程序,运行迟迟没有结果. Mapredu ...
- 在Hadoop 2.3上运行C++程序各种疑难杂症(Hadoop Pipes选择、错误集锦、Hadoop2.3编译等)
首记 感觉Hadoop是一个坑,打着大数据最佳解决方案的旗帜到处坑害良民.记得以前看过一篇文章,说1TB以下的数据就不要用Hadoop了,体现不 出太大的优势,有时候反而会成为累赘.因此Hadoop的 ...
- 本地idea开发mapreduce程序提交到远程hadoop集群执行
https://www.codetd.com/article/664330 https://blog.csdn.net/dream_an/article/details/84342770 通过idea ...
- Hadoop分布环境搭建步骤,及自带MapReduce单词计数程序实现
Hadoop分布环境搭建步骤: 1.软硬件环境 CentOS 7.2 64 位 JDK- 1.8 Hadoo p- 2.7.4 2.安装SSH sudo yum install openssh-cli ...
- 【Cloud Computing】Hadoop环境安装、基本命令及MapReduce字数统计程序
[Cloud Computing]Hadoop环境安装.基本命令及MapReduce字数统计程序 1.虚拟机准备 1.1 模板机器配置 1.1.1 主机配置 IP地址:在学校校园网Wifi下连接下 V ...
- Hadoop MapReduce执行过程详解(带hadoop例子)
https://my.oschina.net/itblog/blog/275294 摘要: 本文通过一个例子,详细介绍Hadoop 的 MapReduce过程. 分析MapReduce执行过程 Map ...
- MapReduce的ReduceTask任务的运行源码级分析
MapReduce的MapTask任务的运行源码级分析 这篇文章好不容易恢复了...谢天谢地...这篇文章讲了MapTask的执行流程.咱们这一节讲解ReduceTask的执行流程.ReduceTas ...
随机推荐
- oracle如何获取上个月的月份
--转载 这个要用到add_months()函数 参数 负数 代表 往前 正数 代表 往后.select to_char(add_months(trunc(sysdate),-1),'yyyymm ...
- 高效删除 ListItem
The most efficient way to a lot of transaction in SharePoint is using of SPWeb.ProcessBatchData meth ...
- js判断手机端操作系统(Andorid/IOS)
非常实用的js判断手机端操作系统(Andorid/IOS),并自动跳转相应下载界面 androidURL = "http://xxx/xxx.apk"; var browser = ...
- 在自定义的web监听器中嵌入web中的定时事件
在 http://www.cnblogs.com/myadmin/p/4806265.html 中说明了自定义web监听器的一些东西. 本文中的web定时任务也基于上篇文章的自定义web监听器. 新建 ...
- Script: Who’s using a database link?(找出谁在使用dblink)
Every once in awhile it is useful to find out which sessions are using a database link in an Oracle ...
- js--Ajax的小知识(二):处理ajax的session过期的请求
问题的产生: 现如今Ajax在Web项目中应用广泛,几乎可以说无处不在. 有时会碰到这样个问题:当Ajax请求遇到Session超时,应该怎么办? 显而易见,传统的页面跳转在此已经不适用,因为Ajax ...
- 转:Android软件开发之PreferenceActivity中的组件
本文转于 “雨松MOMO的程序世界” 博客,请务必保留此出处http://xys289187120.blog.51cto.com/3361352/656784 1.PreferenceActivity ...
- Visual EmbedLinux Tools:让vs支持嵌入式Linux开发(转)
转自:http://blog.csdn.net/lights_joy/article/details/49499743 1 什么是Visual EmbedLinux Tools Visual Embe ...
- 我的接口框架---框架函数文件common.php
<?php defined('JDHU') OR die('no allow access'); /** * 加载配置文件 */ function &get_config($replac ...
- 2016022612 - redis事务命令集合
参考地址:http://www.yiibai.com/redis/redis_transactions.html Redis事务由指令 MULTI 启动,以EXEC结束. 1.multi 用途:事务开 ...