muduo源码分析之Buffer
这一次我们来分析下muduo中Buffer的作用,我们知道,当我们客户端向服务器发送数据时候,服务器就会读取我们发送的数据,然后进行一系列处理,然后再发送到其他地方,在这里我们想象一下最简单的EchoServer服务器,客户端建立一个连接,以后服务器和客户端之间的通信都是通过这个connfd发送和接受数据,于是每一个connfd都应该有一个自己buffer,当我们发送数据太快,服务器发送的太慢,则服务器会将待发送的数据这个buffer中,所以这就是这个类的作用。我们先看下buffer的结构是什么:

我们这里主要针对connfd这个对应的channel进行分析,首先上图是buffer的初始状态,前面8个字节中表示该buffer的大小,初始大小为1024。当客户端发送数据给服务器,同时若服务器接受缓慢,则会向buffer中开始写数据,则writerIndex_会向右移动,假如此时移动到如下形式:
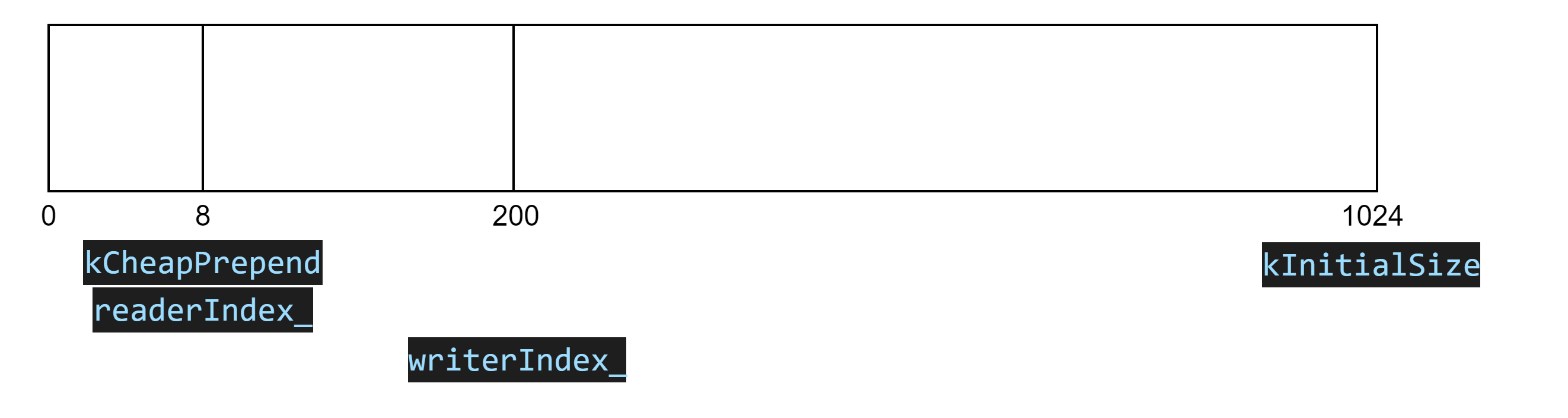
则此时缓冲区可以读的数据为writerIndex_ - readerIndex_,可以写的数据为buffer_.size() - writerIndex_。这时候当服务器有多余资源进行读操作,就可以去缓冲区读数据了,假如这时候的状态为如下:
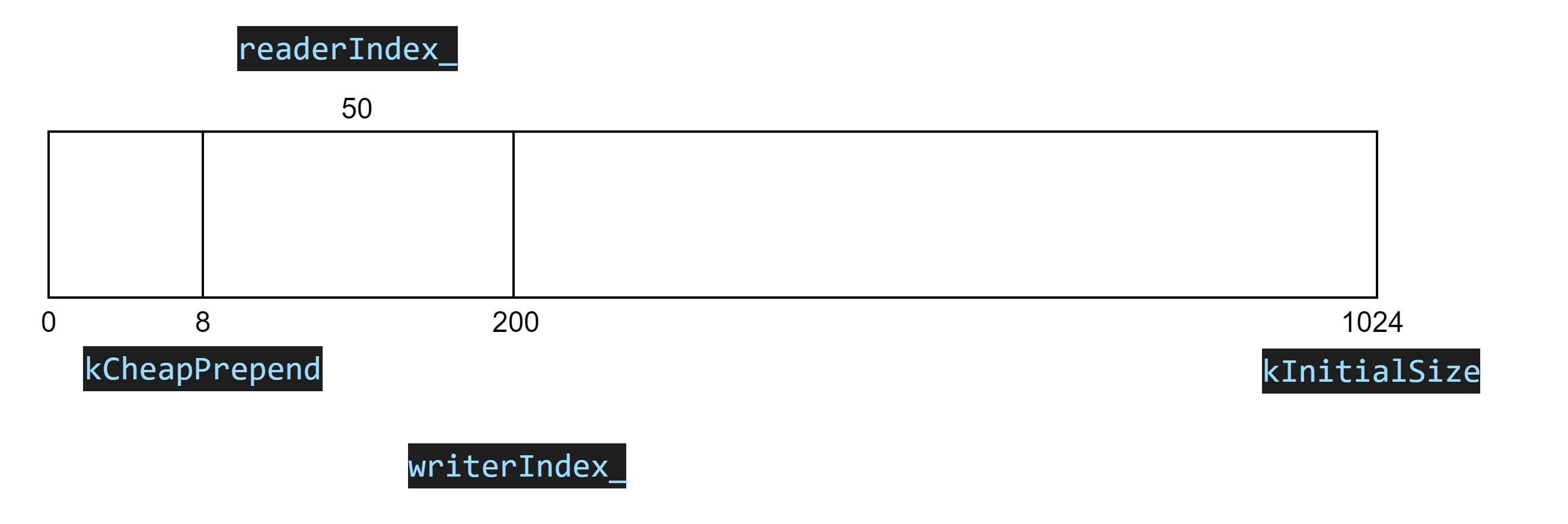
这就是常见的几个状态,下面我们去看几个重点的函数:
// 把onMessage函数上报的buffer内容转为string
std::string retrieveAllAsString()
{
return retrieveAsString(readableBytes()); // 应用可读取数据的长度
}
// 可读的数据 就是存放的是即发送的数据
size_t readableBytes() const
{
return writerIndex_ - readerIndex_;
}
std::string retrieveAsString(size_t len)
{
// 从可读数据开始位置,长度为len的char构造为一个string
std::string result(peek(), len);
retrieve(len); // 上面一句把缓冲区中可读的数据,已经读取出来,这里肯定要对缓冲区进行复位操作
return result;
}
// 将缓冲区len的长度进行复位
void retrieve(size_t len)
{
// 表示还没有读完数据
if (len < readableBytes())
{
readerIndex_ += len; // 应用只读取了刻度缓冲区数据的一部分,就是len,还剩下readerIndex_ += len -> writerIndex_
}
else // len == readableBytes()
{
retrieveAll();
}
}
以上是基本的操作,下面的2个函数很重要,一个是向connfd写数据,一个是读数据,对于一个TcpConnection而言,当有数据来的时候,回去调用handleRead回调函数。我们知道muduo设置的每次读取的大小为65536字节,当缓冲区可写的数据大小大于65536,就会直接将读到的数据写入到缓冲区中,但当缓冲区的可写数据大小小于65536的时候,就会将剩余数据先写到一个额外的空间
ssize_t Buffer::readFd(int fd, int* saveErrno)
{
char extrabuf[65536] = {0}; // 栈上的内存空间 64K
struct iovec vec[2];
// 这是buffer可写的数据
const size_t writable = writableBytes();
vec[0].iov_base = begin() + writerIndex_;
vec[0].iov_len = writable;
vec[1].iov_base = extrabuf;
vec[1].iov_len = sizeof extrabuf;
const int iovcnt = (writable < sizeof extrabuf) ? 2 : 1;
// 去百度下readv
const ssize_t n = ::readv(fd, vec, iovcnt);
if (n < 0)
{
*saveErrno = errno;
}
else if (n <= writable) // Buffer的可写缓冲区已经够存储读出来的数据了
{
writerIndex_ += n;
}
// extrabuf 也写了数据
else
{
writerIndex_ = buffer_.size();
append(extrabuf, n - writable); // writerIndex_开始写 n - writable大小的数据
}
return n;
}
这里巧妙的使用了一个readv函数,可以通过按照大小自动写到不同的地方。其中当extrabuf也写了数据,就会调用append函数。
// 要写len长度的数据
void ensureWriteableBytes(size_t len)
{
if (writableBytes() < len)
{
makeSpace(len); // 扩容函数
}
}
// 向缓冲区添加数据
void append(const char *data, size_t len)
{
ensureWriteableBytes(len);
std::copy(data, data+len, beginWrite());
writerIndex_ += len;
}
注意到有一个makeSpace函数,其中有一个注意点,比如当如下这种状态的时候:
此时readerIndex_前面有一部分其实已经被读完了,是空的数据,所以makeSpace函数考虑了这一点,采用内存重组的方式,将readerIndex_向前移动到kCheapPrepend处,然后就可以让空余的内存挨在一起
void makeSpace(size_t len)
{
if (writableBytes() + prependableBytes() < len + kCheapPrepend)
{
buffer_.resize(writerIndex_ + len);
}
else
{
size_t readalbe = readableBytes();
std::copy(begin() + readerIndex_,
begin() + writerIndex_,
begin() + kCheapPrepend);
readerIndex_ = kCheapPrepend;
writerIndex_ = readerIndex_ + readalbe;
}
}
当向connfd发送数据的时候就比较简单了,直接将可读的数据发送给出去就行
// 通过fd发送数据
ssize_t Buffer::writeFd(int fd, int* saveErrno)
{
ssize_t n = ::write(fd, peek(), readableBytes());
if (n < 0)
{
*saveErrno = errno;
}
return n;
}
自己的网址:www.shicoder.top
欢迎加群聊天 452380935
本文由博客一文多发平台 OpenWrite 发布!
muduo源码分析之Buffer的更多相关文章
- muduo源码分析之回调模块
这次我们主要来说说muduo库中大量使用的回调机制.muduo主要使用的是利用Callback的方式来实现回调,首先我们在自己的EchoServer构造函数中有这样几行代码 EchoServer(Ev ...
- muduo源码分析之TcpServer模块
这次我们开始muduo源代码的实际编写,首先我们知道muduo是LT模式,Reactor模式,下图为Reactor模式的流程图[来源1] 然后我们来看下muduo的整体架构[来源1] 首先muduo有 ...
- muduo源码分析之muduo简单运用
今天不先实现muduo项目,我们先来看下muduo库的基本使用,只有了解了如何用,才能在写代码的时候知道自己写的找个函数是干嘛的,实际上是怎么使用的这个函数.首先说简单点,就是定义一个Server,设 ...
- muduo源码分析:组成结构
muduo整体由许多类组成: 这些类之间有一些依赖关系,如下:
- Envoy 源码分析--buffer
目录 Envoy 源码分析--buffer BufferFragment RawSlice Slice OwnedSlice SliceDeque UnownedSlice OwnedImpl Wat ...
- Netty源码分析第7章(编码器和写数据)---->第3节: 写buffer队列
Netty源码分析七章: 编码器和写数据 第三节: 写buffer队列 之前的小节我们介绍过, writeAndFlush方法其实最终会调用write和flush方法 write方法最终会传递到hea ...
- Netty源码分析第7章(编码器和写数据)---->第4节: 刷新buffer队列
Netty源码分析第七章: 编码器和写数据 第四节: 刷新buffer队列 上一小节学习了writeAndFlush的write方法, 这一小节我们剖析flush方法 通过前面的学习我们知道, flu ...
- netty(六) buffer 源码分析
问题 : netty的 ByteBuff 和传统的ByteBuff的区别是什么? HeapByteBuf 和 DirectByteBuf 的区别 ? HeapByteBuf : 使用堆内存,缺点 ,s ...
- Buffer的创建及使用源码分析——ByteBuffer为例
目录 Buffer概述 Buffer的创建 Buffer的使用 总结 参考资料 Buffer概述 注:全文以ByteBuffer类为例说明 在Java中提供了7种类型的Buffer,每一种类型的Buf ...
随机推荐
- 学习Redis(二)
1.Redis应用场景 1.缓存(键过期时间) 1) 缓存session会话 2) 缓存用户信息,找不到再去mysql查,查到然后回写到redis 3) 商城优惠卷过期时间 2.排行榜(列表& ...
- DateFormat类,利用SimpleDateFormat解决系统时间初始(格式化/解析)问题
目标: java.text.DateFormat 是日期/时间格式化子类的抽象类,我们通过这个类可以帮我们完成日期和文本之间的转换,也就是可以在Date对象与String对象之间进行来回转换. 格式化 ...
- 关于CPU、指令集、架构、芯片的一些科普
作者:王强链接:https://zhuanlan.zhihu.com/p/19893066来源:知乎 随着智能设备的广泛普及,这几年媒体上越来越多的出现关于"架构""AR ...
- vue和react给我的感受
以下纯属个人使用两个框架的感想和体会: 不知道你们是否有这种感觉~ 我vue和react都用过一段时间,但是vue给我感觉就是经常会忘记语法,需要对照文档才知道怎么写( 难不成是我没喝六个核桃的原因吗 ...
- css让文字显示特定行数,多余的显示省略号
/*css*/ .p{ width: 200px; word-break: break-all; text-overflow: ellipsis; display: -webkit-box; /** ...
- 网络编程学习——Linux epoll多路复用模型
前言 后端开发的应该都知道Nginx服务器,Nginx是一个高性能的 HTTP 和反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器.后端部署中一般使用的就是Nginx反向代理技术. ...
- Kubernetes探针原理详解
前言: 分布式系统和微服务体系结构的挑战之一是自动检测不正常的应用程序,并将请求(request)重新路由到其他可用系统,恢复损坏的组件.健康检查是应对该挑战的一种可靠方法.使用 Kubernetes ...
- ADO访问Excel
需要安装驱动:Microsoft Access Database Engine,可搜索下载,有64位和32位之分. 随便新建一个后缀名为udl的文件,双击打开.注意,现如今一般都是64位系统,双击打开 ...
- pytest进阶使用【fixture(一)fixture与setup/teardown区别】
fixture翻译为装置. 我觉得名字是很贴合功能的,可以自由给函数装置上自己想要的功能. 当在说pytest比unitest灵活时,fixture肯定是其中的一个理由. 测试数据的准备和执行以后的数 ...
- Java学习day7
Java继承不同与c++,格式为: public class 子类名 extends 父类名{ 语句体; } 继承提高了代码的复用性与维护性 在子类方法中访问一个变量时,首先在子类局部范围查找,其次到 ...