12月15日内容总结——ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作
一、ORM执行SQL语句
django中的ORM提供的操作功能有限,在模型提供的查询API不能满足实际工作需要时,可以在ORM中直接执行原生sql语句。
Django 提供两种方法使用原生SQL进行查询:
一种是使用raw()方法,进行原生SQL查询并返回模型实例;
另一种是完全避开模型层,直接执行自定义的SQL语句。
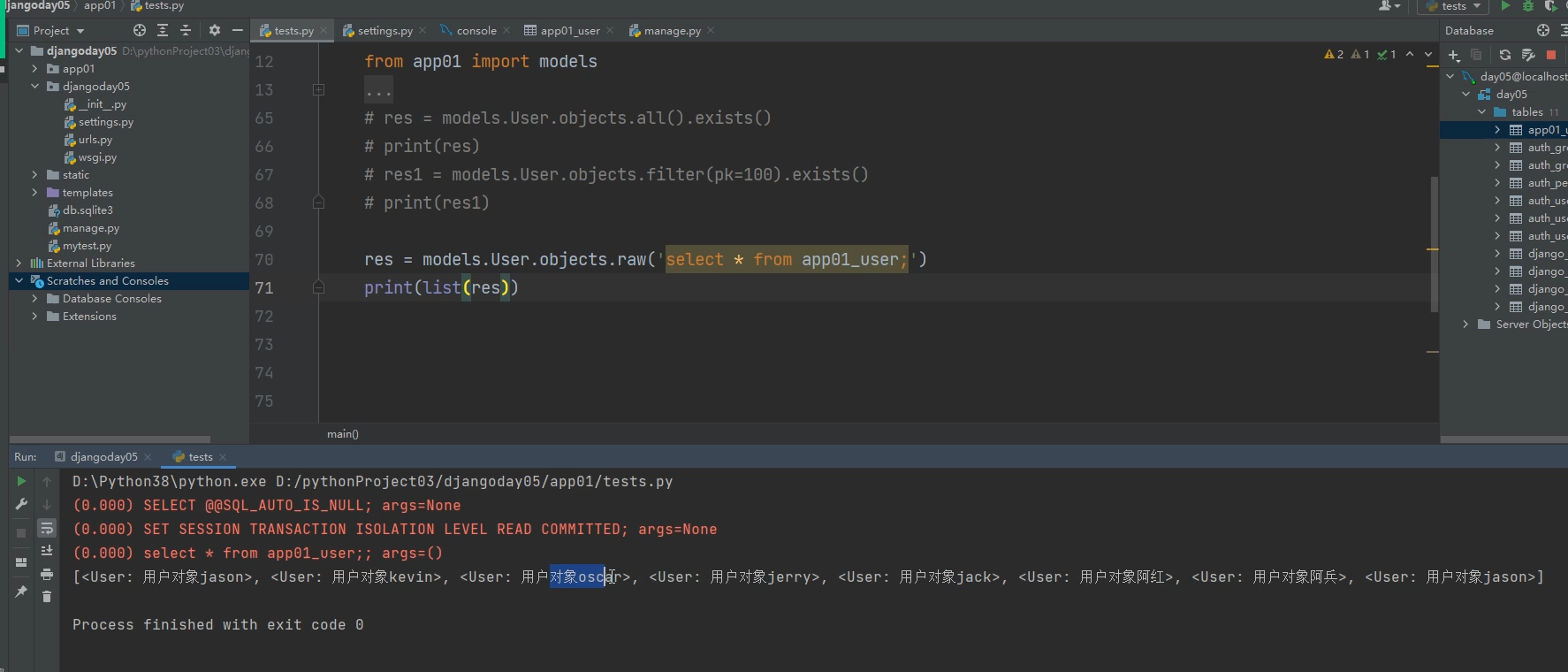
方式1:
models.User.objects.raw('select * from app01_user;')
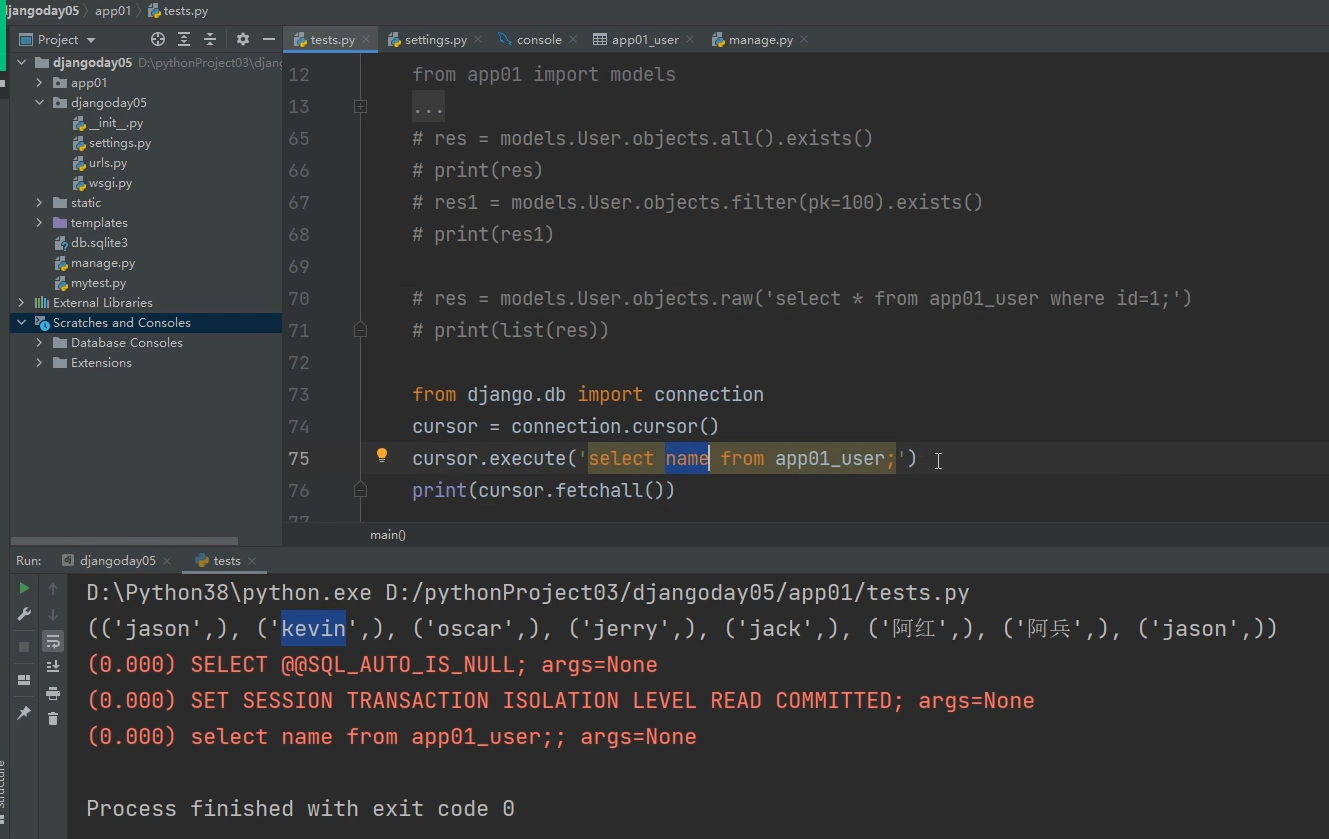
方式2:
from django.db import connection
cursor = connection.cursor()
cursor.execute('select name from app01_user;')
print(cursor.fetchall())
二、神奇的双下划线查询
我们在使用ORM操作对数据进行操作的时候,结果通常都是queryset对象,只要结果还是queryset对象就可以无限制的点queryset对象能使用的各种方法。例:
queryset.filter().values().filter().values_list().filter()...
我们在使用ORM操作数据库的时候,会发现一些符号、一些查找条件并不能跟sql语句中一样直接用,比如大于号小于号等符号,如果我们想要在ORM中使用这些条件,需要使用双下滑线查询方法。
常见的双下划线查询方法
| 方法 | 描述 |
|---|---|
| __gt | 大于 |
| __lt | 小于 |
| __gte | 大于等于 |
| __lte | 小于等于 |
| __in | 或 |
| __range | 取指定范围内对应数据,并且首尾都要 |
| __contains | 模糊查询,查询出指定字符数据,区分大小写 |
| __icontains | 忽略大小写 |
| __startswith | 查询以指定字符开头数据 |
| __endswith | 查询以指定字符结尾数据 |
代码实操:
# 查询年龄大于18的用户数据
# res = models.User.objects.filter(age__gt=18)
# print(res)
# 查询年龄小于38的用户数据
# res = models.User.objects.filter(age__lt=38)
# print(res)
# 大于等于 小于等于
# res = models.User.objects.filter(age__gte=18)
# res = models.User.objects.filter(age__lte=38)
# 查询年龄是18或者28或者38的数据
# res = models.User.objects.filter(age__in=(18, 28, 38))
# print(res)
# 查询年龄在18到38范围之内的数据
# res = models.User.objects.filter(age__range=(18, 38))
# print(res)
# 查询名字中含有字母j的数据
# res = models.User.objects.filter(name__contains='j') # 区分大小写
# print(res)
# res = models.User.objects.filter(name__icontains='j') # 不区分大小写
# print(res)
# 查询注册年份是2022的数据
# res = models.User.objects.filter(register_time__year=2022)
# print(res)
'''针对django框架的时区问题 是需要配置文件中修改的 后续bbs讲解'''
三、ORM外键字段的创建
复习MySQL外键关系
一对多
外键字段建在多的一方
多对多
外键字段统一建在第三张关系表
一对一
建在任何一方都可以 但是建议建在查询频率较高的表中
ps:关系的判断可以采用换位思考原则 熟练的之后可以瞬间判断
外键字段的创建
1.创建基础表(书籍表、出版社表、作者表、作者详情)
代码在下方
2.确定外键关系
一对多 ORM与MySQL一致 外键字段建在多的一方
多对多 ORM比MySQL有更多变化
1.外键字段可以直接建在某张表中(查询频率较高的)
内部会自动帮你创建第三张关系表
2.自己创建第三张关系表并创建外键字段
详情后续讲解
一对一 ORM与MySQL一致 外键字段建在查询较高的一方
3.ORM创建
针对一对多和一对一的外键字段,同步到表中之后会自动加_id的后缀。
即ForeignKey 和 OneToOneField,会自动给字段加_id后缀
publish = models.ForeignKey(to='Publish',on_delete=models.CASCADE)
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
针对多对多 不会在表中有展示 而是创建第三张表
authors = models.ManyToManyField(to='Author')
4.完整的创建代码
from django.db import models
# Create your models here.
class Book(models.Model):
"""图书表"""
title = models.CharField(max_length=32, verbose_name='书名')
price = models.DecimalField(max_digits=8, decimal_places=2, verbose_name='价格')
# 八位整数,两位小数
publish_time = models.DateField(auto_now_add=True, verbose_name='出版日期')
# 这里要区别auto_now和auto_now_add的区别,auto_now在创建时会将创建时间当成数据记录,在修改的时候会用修改时间进行数据记录
#而auto_now_add只会记录创建的时间信息,修改的时候不会进行记录
# 创建书籍与出版社的一对多外键字段
publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE)
'''django1.x版本外键字段默认都是级联更新删除 django2.x及以上需要自己申明 on_delete=models.XXX '''
# 创建书籍与作者的多对多外键字段
authors = models.ManyToManyField(to='Author')
'''多对多字段为虚拟字段,用于告诉ORM自动创建第三张表,数据库迁移(也就是创建了对应的表)之后,并没有这个字段,但是会有一张新的表'''
# def __str__(self):
# return f'书籍对象:{self.title}'
class Publish(models.Model):
"""出版社表"""
name = models.CharField(max_length=32, verbose_name='名称')
address = models.CharField(max_length=64, verbose_name='地址')
# def __str__(self):
# return f'出版社对象:{self.name}'
class Author(models.Model):
"""作者表"""
name = models.CharField(max_length=32, verbose_name='姓名')
age = models.IntegerField(verbose_name='年龄')
# 创建作者与作者详情的一对一外键字段
author_detail = models.OneToOneField(to='AuthorDetail', on_delete=models.CASCADE)
# on_delete就是设置外键的级联更新,这里的to的值是创建外键连接的表的名称,如果不写称字符串就会出现查找顺序的问题
# def __str__(self):
# return f'作者对象:{self.name}'
class AuthorDetail(models.Model):
"""作者详情表"""
phone = models.BigIntegerField(verbose_name='手机号')
address = models.CharField(max_length=64, verbose_name='家庭住址')
# def __str__(self):
# return f'详情对象:{self.address}'
ps:模型层写好还要进行数据库迁移
四、外键字段相关操作
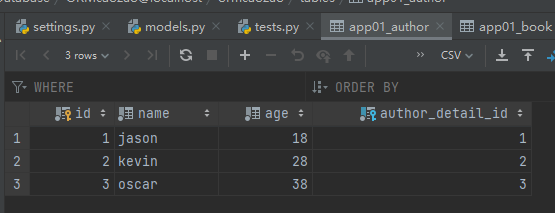
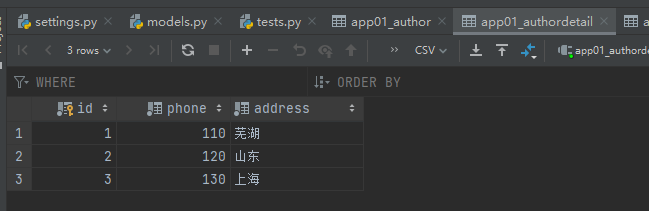
数据准备
book表中的数据是用下方的代码创建的,多对多外键创建的表不用手动创建数据,其他的数据需要我们手动创建。因为创建book中的数据的时候会用到别的表中的字段值。
# 针对一对多 插入数据可以直接填写表中的实际字段
models.Book.objects.create(title='三国演义', price=888.88, publish_id=1)
models.Book.objects.create(title='人性的弱点', price=777.55, publish_id=1)
# 针对一对多 插入数据也可以填写表中的类中字段名
publish_obj = models.Publish.objects.filter(pk=1).first()
models.Book.objects.create(title='水浒传', price=555.66, publish=publish_obj)
'''一对一与一对多一致,既可以传数字也可以传对象'''
# 针对多对多关系绑定
# 添加记录
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.add(1) # 在第三张关系表中给当前书籍绑定作者
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.add(2, 3) # 书和作者的外键是authors
book_obj = models.Book.objects.filter(pk=3).first()
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
book_obj.authors.add(author_obj1)
book_obj = models.Book.objects.filter(pk=4).first()
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
book_obj.authors.add(author_obj1, author_obj2)
# 修改记录
# 这里是用值修改
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.set((1, 3)) # 修改关系
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.set([2, ]) # 修改关系
# 这里是用获取到的对象进行修改
book_obj = models.Book.objects.filter(pk=1).first()
author_obj1 = models.Author.objects.filter(pk=1).first()
author_obj2 = models.Author.objects.filter(pk=2).first()
book_obj.authors.set((author_obj1,))
book_obj.authors.set((author_obj1, author_obj2))
# 删除记录,也是分成根据值对象进行删除
book_obj = models.Book.objects.filter(pk=1).first()
book_obj.authors.remove(2)
book_obj.authors.remove(1, 3)
book_obj.authors.remove(author_obj1,)
book_obj.authors.remove(author_obj1,author_obj2)
book_obj.authors.clear()
参数使用讲解
add()
把指定的model对象添加到第三张关联表中。
参数可以是多个位置参数(数字或对象)
remove()
从关联对象集中移除执行的model对象(移除对象在第三张表中与某个关联对象的关系)
参数可以是多个位置参数(数字或对象)
set()
更新某个对象在第三张表中的关联对象。不同于上面的add是添加,set相当于重置
可迭代对象(参数要放到元组或列表中,元组或列表中存放的参数可以是数据值或对象)
clear()
从关联对象集中移除一切对象。(移除所有与对象相关的关系信息)
五、ORM跨表查询
复习MySQL跨表查询的思路
子查询
分步操作:将一条SQL语句用括号括起来当做另外一条SQL
语句的条件
连表操作
先整合多张表之后基于单表查询即可
inner join 内连接
left join 左连接
right join 右连接
union 全连接
正反向查询的概念(重要)
- 正向查询
由外键字段所在的表数据查询关联的表数据是正向
或者说外键在自己手上则是正向查询
- 反向查询
没有外键字段的表数据查询关联的表数据是反向
或者说外键在别人手上则是反向查询
ps:正反向的核心就看外键字段在不在当前数据所在的表中
ORM跨表查询的口诀(重要)
正向查询按外键字段
反向查询按表名小写
六、基于对象的跨表查询
'''基于对象的跨表查询'''
# 1.查询主键为1的书籍对应的出版社名称
# 先根据条件获取数据对象
book_obj = models.Book.objects.filter(pk=1).first()
# 再判断正反向的概念 由书查出版社 外键字段在书所在的表中 所以是正向查询
print(book_obj.publish.name)
# 2.查询主键为4的书籍对应的作者姓名
# 先根据条件获取数据对象
book_obj = models.Book.objects.filter(pk=4).first()
# 再判断正反向的概念 由书查作者 外键字段在书所在的表中 所以是正向查询
print(book_obj.authors) # app01.Author.None
print(book_obj.authors.all())
print(book_obj.authors.all().values('name'))
# 3.查询jason的电话号码
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.author_detail.phone)
# 4.查询北方出版社出版过的书籍
publish_obj = models.Publish.objects.filter(name='北方出版社').first()
print(publish_obj.book_set) # app01.Book.None
print(publish_obj.book_set.all())
# 5.查询jason写过的书籍
author_obj = models.Author.objects.filter(name='jason').first()
print(author_obj.book_set) # app01.Book.None
print(author_obj.book_set.all())
# 6.查询电话号码是110的作者姓名
author_detail_obj = models.AuthorDetail.objects.filter(phone=110).first()
print(author_detail_obj.author)
print(author_detail_obj.author.name)
ps:在进行反向查询的时候,因为会用掉小写的表名,这时候需要在表名后面跟下_set才能获取到信息,这时候获取到的内容如下:
app01.Book.None
获取到内容后点all方法就能看到内部的数据值
七、基于双下划线的跨表查询
'''基于双下划线的跨表查询'''
# 1.查询主键为1的书籍对应的出版社名称
res = models.Book.objects.filter(pk=1).values('publish__name','title')
print(res)
# 2.查询主键为4的书籍对应的作者姓名
res = models.Book.objects.filter(pk=4).values('title', 'authors__name')
print(res)
# 3.查询jason的电话号码
res = models.Author.objects.filter(name='jason').values('author_detail__phone')
print(res)
# 4.查询北方出版社出版过的书籍名称和价格
res = models.Publish.objects.filter(name='北方出版社').values('book__title','book__price','name')
print(res)
# 5.查询jason写过的书籍名称
res = models.Author.objects.filter(name='jason').values('book__title', 'name')
print(res)
# 6.查询电话号码是110的作者姓名
res = models.AuthorDetail.objects.filter(phone=110).values('phone', 'author__name')
print(res)
八、进阶操作
'''基于双下划线的跨表查询'''
# 1.查询主键为1的书籍对应的出版社名称
res = models.Book.objects.filter(pk=1).values('publish__name','title')
print(res)
# 2.查询主键为4的书籍对应的作者姓名
res = models.Book.objects.filter(pk=4).values('title', 'authors__name')
print(res)
# 3.查询jason的电话号码
res = models.Author.objects.filter(name='jason').values('author_detail__phone')
print(res)
# 4.查询北方出版社出版过的书籍名称和价格
res = models.Publish.objects.filter(name='北方出版社').values('book__title','book__price','name')
print(res)
# 5.查询jason写过的书籍名称
res = models.Author.objects.filter(name='jason').values('book__title', 'name')
print(res)
# 6.查询电话号码是110的作者姓名
res = models.AuthorDetail.objects.filter(phone=110).values('phone', 'author__name')
print(res)
'''进阶操作'''
# 1.查询主键为1的书籍对应的出版社名称
res = models.Publish.objects.filter(book__pk=1).values('name')
print(res)
# 2.查询主键为4的书籍对应的作者姓名
res = models.Author.objects.filter(book__pk=4).values('name','book__title')
print(res)
# 3.查询jason的电话号码
res = models.AuthorDetail.objects.filter(author__name='jason').values('phone')
print(res)
# 4.查询北方出版社出版过的书籍名称和价格
res = models.Book.objects.filter(publish__name='北方出版社').values('title','price')
print(res)
# 5.查询jason写过的书籍名称
res = models.Book.objects.filter(authors__name='jason').values('title')
print(res)
# 6.查询电话号码是110的作者姓名
res = models.Author.objects.filter(author_detail__phone=110).values('name')
print(res)
'''补充'''
# 查询主键为4的书籍对应的作者的电话号码
res = models.Book.objects.filter(pk=4).values('authors__author_detail__phone')
print(res)
res = models.AuthorDetail.objects.filter(author__book__pk=4).values('phone')
print(res)
res = models.Author.objects.filter(book__pk=4).values('author_detail__phone')
print(res)
12月15日内容总结——ORM执行原生SQL语句、双下划线数据查询、ORM外键字段的创建、外键字段的相关操作、ORM跨表查询、基于对象的跨表查询、基于双下划线的跨表查询、进阶查询操作的更多相关文章
- Django之ORM执行原生sql语句
django中的ORM提供的操作功能有限,在模型提供的查询API不能满足实际工作需要时,可以在ORM中直接执行原生sql语句. Django 提供两种方法使用原生SQL进行查询:一种是使用raw()方 ...
- ORM执行原生SQL语句
# 1.connectionfrom django.db import connection, connections cursor = connection.cursor() # cursor = ...
- django系列5.4--ORM中执行原生SQL语句, Python脚本中调用django环境
ORM执行原生sql语句 在模型查询API不够用的情况下,我们还可以使用原始的SQL语句进行查询. Django 提供两种方法使用原始SQL进行查询:一种是使用raw()方法,进行原始SQL查询并返回 ...
- python 之 Django框架(orm单表查询、orm多表查询、聚合查询、分组查询、F查询、 Q查询、事务、Django ORM执行原生SQL)
12.329 orm单表查询 import os if __name__ == '__main__': # 指定当前py脚本需要加载的Django项目配置信息 os.environ.setdefaul ...
- AHKManager.ahk AHK管理器 2019年12月15日
AHKManager.ahk AHK管理器 2019年12月15日 快捷键 {Alt} + {F1} ///////////////////////////////////////////// ...
- 2016年12月15日 星期四 --出埃及记 Exodus 21:10
2016年12月15日 星期四 --出埃及记 Exodus 21:10 If he marries another woman, he must not deprive the first one o ...
- 【C++】命令行Hangman #2015年12月15日 00:20:27
增加了可以在构造Hangman对象时通过传入参数设定“最大猜测次数”的功能.少量修改.# 2015年12月15日 00:20:22 https://github.com/shalliestera/ha ...
- 北京Uber优步司机奖励政策(12月15日)
用户组:人民优步及电动车(适用于12月15日) 滴快车单单2.5倍,注册地址:http://www.udache.com/ 如何注册Uber司机(全国版最新最详细注册流程)/月入2万/不用抢单:htt ...
- Django中的ORM相关操作:F查询,Q查询,事物,ORM执行原生SQL
一 F查询与Q查询: 1 . F查询: 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个常量做比较.如果我们要对两个字段的值做比较,那该怎么做呢? Django 提供 F() 来做这样的 ...
- Django的F查询和Q查询,事务,ORM执行原生SQL
F查询和Q查询,事务及其他 F查询和Q查询 F查询 在上面所有的例子中,我们构造的过滤器都只是将字段值与某个我们自己设定的常量做比较.如果我们要对两个字段的值做比较,那该怎么做呢? Django ...
随机推荐
- 【操作说明】全能型H.265播放器如何使用?
本播放器集成了公司业务的接口,包含了实播,回放,云台控制和回放速度控制,截图和全屏功能可以根据type直接初始化接口地址如果是第三方业务对接,也可以单独配置接口地址 正确使用H.265播放器需要按以下 ...
- OpenMP 教程(一) 深入人剖析 OpenMP reduction 子句
OpenMP 教程(一) 深入人剖析 OpenMP reduction 子句 前言 在前面的教程OpenMP入门当中我们简要介绍了 OpenMP 的一些基础的使用方法,在本篇文章当中我们将从一些基础的 ...
- ValidList
package com.dlzb.enterprising.config; import javax.validation.Valid; import java.util.*; public clas ...
- Vue3 企业级优雅实战 - 组件库框架 - 5 组件库通用工具包
该系列已更新文章: 分享一个实用的 vite + vue3 组件库脚手架工具,提升开发效率 开箱即用 yyg-cli 脚手架:快速创建 vue3 组件库和vue3 全家桶项目 Vue3 企业级优雅实战 ...
- CPU体系(1):内存模型 & CPU Cache一致性 (待整理)
C++中的 volatile, atomic, memory barrier 应用场景对比 -- volatile memory barrier atomic 抑制编译器重排 Yes Yes Yes ...
- WeetCode2滑动窗口系列
系列文章目录和关于我 一丶[无重复字符的最长子串](3. 无重复字符的最长子串 - 力扣(Leetcode)) 思路: 维护一个窗口,窗口中不存在重复的字符,窗口右边界从第一个字符移动到最后,使用一个 ...
- 【大数据-课程】高途-天翼云侯圣文-Day3-实时计算原理解析
〇.老师及课程介绍 一.今日内容 二.实时计算理论解析 1.什么是实时计算 微批处理.流式处理.实时计算 水流和车流的例子 spark streaming就是一种微批处理,水满了才处理,进入下一个地方 ...
- 从一个 issue 出发,带你玩图数据库 NebulaGraph 内核开发
如何 build NebulaGraph?如何为 NebulaGraph 内核做贡献?即便是新手也能快速上手,从本文作为切入点就够了. NebulaGraph 的架构简介 为了方便对 NebulaGr ...
- 介绍一款高性能分布式MQTT Broker(带web)
SMQTTX介绍 SMQTTX是基于SMQTT的一次重大技术升级,基于Java开发的分布式MQTT集群,是一款高性能,高吞吐量,并且可以完成二次开发的优秀的开源MQTT broker,主要采用技术栈: ...
- SpringBoot源码2——SpringBoot x Mybatis 原理解析(如何整合,事务如何交由spring管理,mybatis如何进行数据库操作)
阅读本文需要spring源码知识,和springboot相关源码知识 对于springboot 整合mybatis,以及mybatis源码关系不密切的知识,本文将简单带过 系列文章目录和关于我 涉及到 ...