第2-1-1章 FastDFS分布式文件服务背景及系统架构介绍
1 背景
1.1 为什么需要分布式文件服务
1.1.1 单机时代
初创时期由于时间紧迫,在各种资源有限的情况下,通常就直接在项目目录下建立静态文件夹,用于用户存放项目中的文件资源。如果按不同类型再细分,可以在项目目录下再建立不同的子目录来区分。例如:resources\static\file、resources\static\iamge等。
- 优点:这样做比较便利,项目直接引用就行,实现起来也简单,无需任何复杂技术,保存数据库记录和访问起来也很方便。
- 缺点:如果只是后台系统的使用一般也不会有什么问题,但是作为一个前端网站使用的话就会存在弊端。一方面,文件和代码耦合在一起,文件越多存放越混乱;另一方面,如果流量比较大,静态文件访问会占据一定的资源,影响正常业务进行,不利于网站快速发展。
1.1.2 独立文件服务器
随着公司业务不断发展,将代码和文件放在同一服务器的弊端就会越来越明显。为了解决上面的问题引入独立图片服务器,工作流程如下:项目上传文件时,首先通过ftp或者ssh将文件上传到图片服务器的某个目录下,再通过ngnix或者apache来访问此目录下的文件,返回一个独立域名的图片URL地址,前端使用文件时就通过这个URL地址读取。
- 优点:图片访问是很消耗服务器资源的(因为会涉及到操作系统的上下文切换和磁盘I/O操作),分离出来后,Web/App服务器可以更专注发挥动态处理的能力;独立存储,更方便做扩容、容灾和数据迁移;方便做图片访问请求的负载均衡,方便应用各种缓存策略(HTTP Header、Proxy Cache等),也更加方便迁移到CDN。
- 缺点:单机存在性能瓶颈,容灾、垂直扩展性稍差
1.1.3 分布式文件系统
通过独立文件服务器可以解决一些问题,如果某天存储文件的那台服务突然down了怎么办?可能你会说,定时将文件系统备份,这台down机的时候,迅速切换到另一台就OK了,但是这样处理需要人工来干预。另外,当存储的文件超过100T的时候怎么办?单台服务器的性能问题?这个时候我们就应该考虑分布式文件系统了。
业务继续发展,单台服务器存储和响应也很快到达了瓶颈,新的业务需要文件访问具有高响应性、高可用性来支持系统。分布式文件系统,一般分为三块内容来配合,服务的存储、访问的仲裁系统,文件存储系统,文件的容灾系统来构成,仲裁系统相当于文件服务器的大脑,根据一定的算法来决定文件存储的位置,文件存储系统负责保存文件,容灾系统负责文件系统和自己的相互备份。
- 优点:扩展能力: 毫无疑问,扩展能力是一个分布式文件系统最重要的特点;高可用性: 在分布式文件系统中,高可用性包含两层,一是整个文件系统的可用性,二是数据的完整和一致性;弹性存储: 可以根据业务需要灵活地增加或缩减数据存储以及增删存储池中的资源,而不需要中断系统运行
- 缺点:系统复杂度稍高,需要更多服务器
1.2 什么是FastDFS
FastDFS是一个开源的轻量级分布式文件系统。它解决了大数据量存储和负载均衡等问题。特别适合以中小文件(建议范围:4KB < file_size <500MB)为载体的在线服务,如相册网站、视频网站等等。在UC基于FastDFS开发向用户提供了:网盘,社区,广告和应用下载等业务的存储服务。
FastDFS是一款开源的轻量级分布式文件系统纯C实现,支持Linux、FreeBSD等UNIX系统类google FS,不是通用的文件系统,只能通过专有API访问,目前提供了C、Java和PHP API为互联网应用量身定做,解决大容量文件存储问题,追求高性能和高扩展性FastDFS可以看做是基于文件的key value pair存储系统,称作分布式文件存储服务更为合适。
FastDFS特性:
- 文件不分块存储,上传的文件和OS文件系统中的文件一一对应
- 支持相同内容的文件只保存一份,节约磁盘空间
- 下载文件支持HTTP协议,可以使用内置Web Server,也可以和其他Web Server配合使用
- 支持在线扩容
- 支持主从文件
- 存储服务器上可以保存文件属性(meta-data)V2.0网络通信采用libevent,支持大并发访问,整体性能更好
开源地址: https://github.com/happyfish100/fastdfs
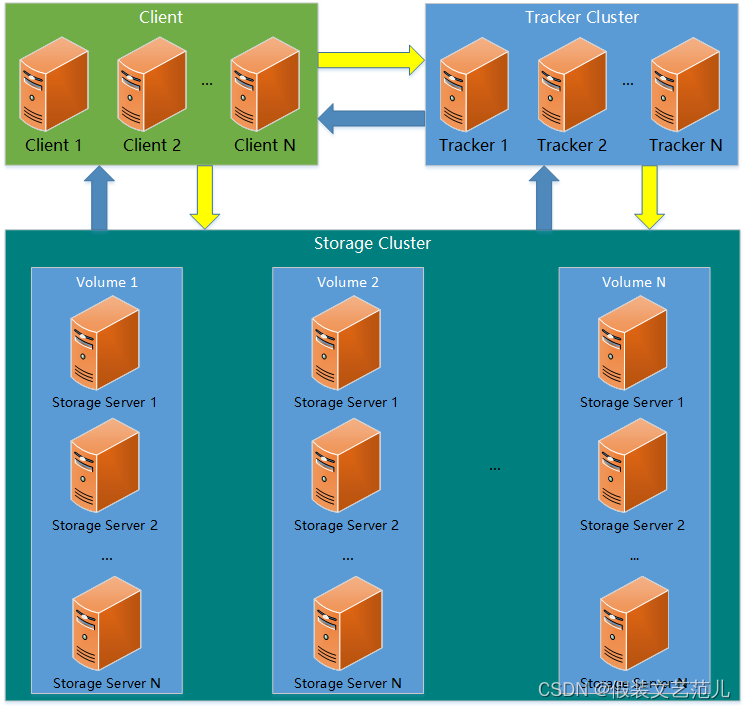
2 系统架构
FastDFS服务端有三个角色:跟踪服务器(tracker server)、存储服务器(storage server)和客户端(client)。
tracker server:跟踪服务器,主要做调度工作,起负载均衡的作用。在内存中记录集群中所有存储组和存储服务器的状态信息,是客户端和数据服务器交互的枢纽。相比GFS中的master更为精简,不记录文件索引信息,占用的内存量很少。
Tracker是FastDFS的协调者,负责管理所有的storage server和group,每个storage在启动后会连接Tracker,告知自己所属的group等信息,并保持周期性的心跳,tracker根据storage的心跳信息,建立group==>[storage server list]的映射表。
Tracker需要管理的元信息很少,会全部存储在内存中;另外tracker上的元信息都是由storage汇报的信息生成的,本身不需要持久化任何数据,这样使得tracker非常容易扩展,直接增加tracker机器即可扩展为tracker cluster来服务,cluster里每个tracker之间是完全对等的,所有的tracker都接受stroage的心跳信息,生成元数据信息来提供读写服务。
storage server:存储服务器(又称:存储节点或数据服务器),文件和文件属性(meta data)都保存到存储服务器上。Storage server直接利用OS的文件系统调用管理文件。
Storage server(后简称storage)以组(卷,group或volume)为单位组织,一个group内包含多台storage机器,数据互为备份,存储空间以group内容量最小的storage为准,所以建议group内的多个storage尽量配置相同,以免造成存储空间的浪费。
以group为单位组织存储能方便的进行应用隔离、负载均衡、副本数定制(group内storage server数量即为该group的副本数),比如将不同应用数据存到不同的group就能隔离应用数据,同时还可根据应用的访问特性来将应用分配到不同的group来做负载均衡;缺点是group的容量受单机存储容量的限制,同时当group内有机器坏掉时,数据恢复只能依赖group内地其他机器,使得恢复时间会很长。
group内每个storage的存储依赖于本地文件系统,storage可配置多个数据存储目录,比如有10块磁盘,分别挂载在
/data/disk1-/data/disk10,则可将这10个目录都配置为storage的数据存储目录。storage接受到写文件请求时,会根据配置好的规则(后面会介绍),选择其中一个存储目录来存储文件。为了避免单个目录下的文件数太多,在storage第一次启动时,会在每个数据存储目录里创建2级子目录,每级256个,总共65536个文件,新写的文件会以hash的方式被路由到其中某个子目录下,然后将文件数据直接作为一个本地文件存储到该目录中。
client:客户端,作为业务请求的发起方,通过专有接口,使用TCP/IP协议与跟踪器服务器或存储节点进行数据交互。FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。
group :组, 也可称为卷。 同组内服务器上的文件是完全相同的 ,同一组内的storage server之间是对等的, 文件上传、 删除等操作可以在任意一台storage server上进行 。
meta data :文件相关属性,键值对( Key Value Pair) 方式,如:width=1024,heigth=768 。
2.1 Tracker集群
FastDFS集群中的Tracker server可以有多台,Trackerserver之间是相互平等关系同时提供服务,Trackerserver不存在单点故障。客户端请求Trackerserver采用轮询方式,如果请求的tracker无法提供服务则换另一个tracker。
2.2 Storage集群
为了支持大容量,存储节点(服务器)采用了分卷(或分组)的组织方式。存储系统由一个或多个卷组成,卷与卷之间的文件是相互独立的,所有卷的文件容量累加就是整个存储系统中的文件容量。一个卷由一台或多台存储服务器组成,卷内的Storage server之间是平等关系,不同卷的Storageserver之间不会相互通信,同卷内的Storageserver之间会相互连接进行文件同步,从而保证同组内每个storage上的文件完全一致的。一个卷的存储容量为该组内存储服务器容量最小的那个,由此可见组内存储服务器的软硬件配置最好是一致的。卷中的多台存储服务器起到了冗余备份和负载均衡的作用
在卷中增加服务器时,同步已有的文件由系统自动完成,同步完成后,系统自动将新增服务器切换到线上提供服务。当存储空间不足或即将耗尽时,可以动态添加卷。只需要增加一台或多台服务器,并将它们配置为一个新的卷,这样就扩大了存储系统的容量。
采用分组存储方式的好处是灵活、可控性较强。比如上传文件时,可以由客户端直接指定上传到的组也可以由tracker进行调度选择。一个分组的存储服务器访问压力较大时,可以在该组增加存储服务器来扩充服务能力(纵向扩容)。当系统容量不足时,可以增加组来扩充存储容量(横向扩容)。
2.3 Storage状态收集
Storage server会连接集群中所有的Tracker server,定时向他们报告自己的状态,包括磁盘剩余空间、文件同步状况、文件上传下载次数等统计信息。
2.4 FastDFS的上传过程
FastDFS向使用者提供基本文件访问接口,比如upload、download、append、delete等,以客户端库的方式提供给用户使用。
Storage Server会定期的向Tracker Server发送自己的存储信息。当Tracker Server Cluster中的Tracker Server不止一个时,各个Tracker之间的关系是对等的,所以客户端上传时可以选择任意一个Tracker。
当Tracker收到客户端上传文件的请求时,会为该文件分配一个可以存储文件的group,当选定了group后就要决定给客户端分配group中的哪一个storage server。当分配好storage server后,客户端向storage发送写文件请求,storage将会为文件分配一个数据存储目录。然后为文件分配一个fileid,最后根据以上的信息生成文件名存储文件。
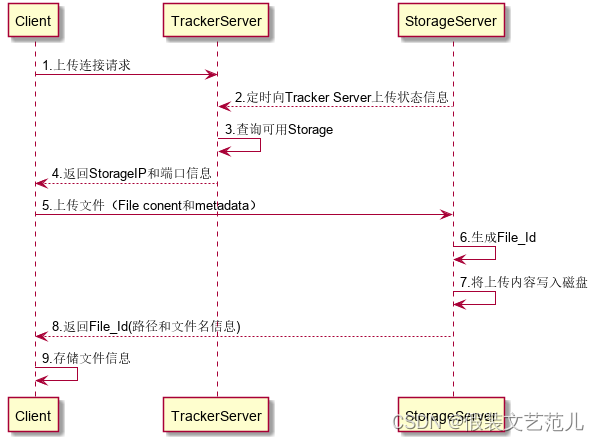
客户端上传文件后存储服务器将文件ID返回给客户端,此文件ID用于以后访问该文件的索引信息。文件索引信息包括:组名,虚拟磁盘路径,数据两级目录,文件名。
组名:文件上传后所在的storage组名称,在文件上传成功后有storage服务器返回,需要客户端自行保存。
虚拟磁盘路径:storage配置的虚拟路径,与磁盘选项store_path*对应。如果配置了store_path0则是M00,如果配置了store_path1则是M01,以此类推。
数据两级目录:storage服务器在每个虚拟磁盘路径下创建的两级目录,用于存储数据文件。
文件名:与文件上传时不同。是由存储服务器根据特定信息生成,文件名包含:源存储服务器IP地址、文件创建时间戳、文件大小、随机数和文件拓展名等信息。
2.5 FastDFS的文件同步
写文件时,客户端将文件写至group内一个storage server即认为写文件成功,storage server写完文件后,会由后台线程将文件同步至同group内其他的storage server。
每个storage写文件后,同时会写一份binlog,binlog里不包含文件数据,只包含文件名等元信息,这份binlog用于后台同步,storage会记录向group内其他storage同步的进度,以便重启后能接上次的进度继续同步;进度以时间戳的方式进行记录,所以最好能保证集群内所有server的时钟保持同步。
storage的同步进度会作为元数据的一部分汇报到tracker上,tracke在选择读storage的时候会以同步进度作为参考。
2.6 FastDFS的文件下载
客户端uploadfile成功后,会拿到一个storage生成的文件名,接下来客户端根据这个文件名即可访问到该文件。
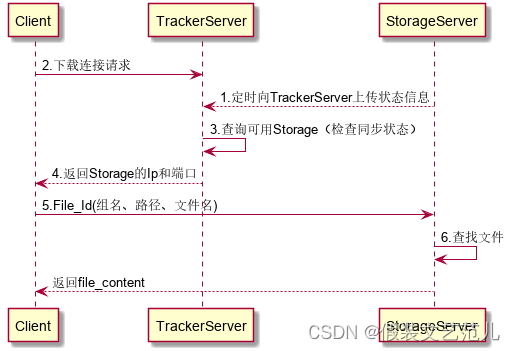
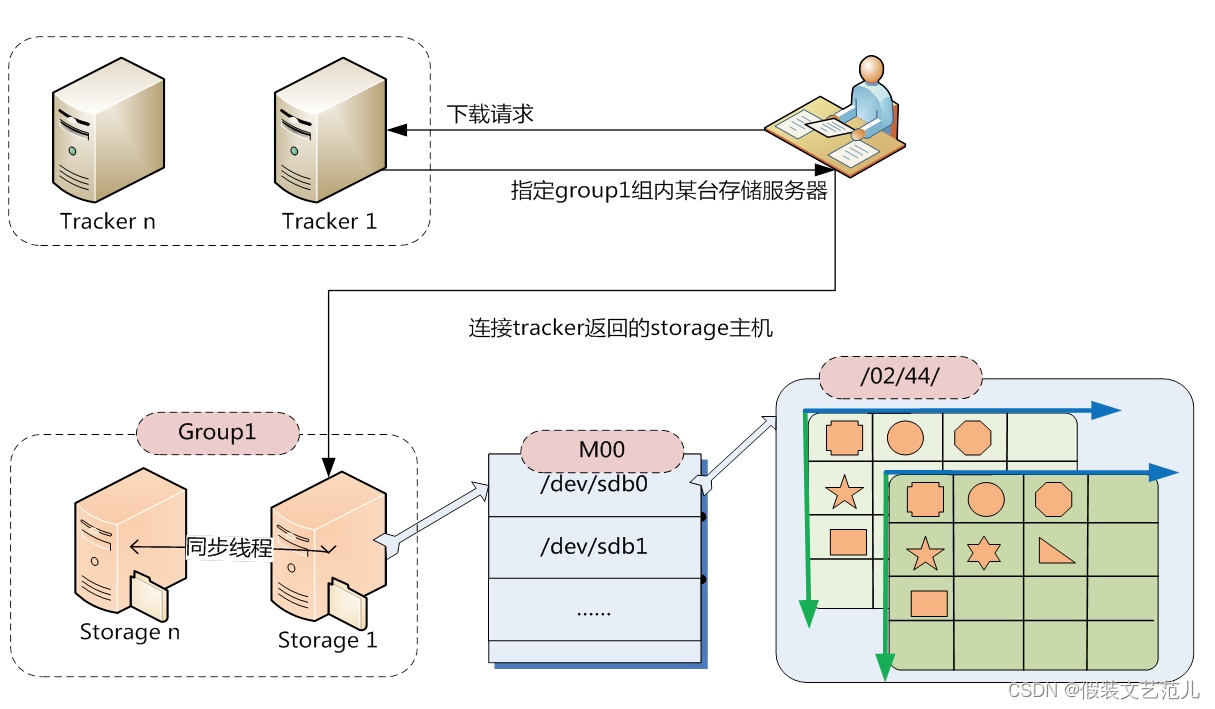
跟upload file一样,在downloadfile时客户端可以选择任意tracker server。tracker发送download请求给某个tracker,必须带上文件名信息,tracke从文件名中解析出文件的group、大小、创建时间等信息,然后为该请求选择一个storage用来服务读请求。tracker根据请求的文件路径即文件ID 来快速定义文件。
比如请求下边的文件:
group1/M00/02/44/Swtdssdsdfsdf.txt
通过组名tracker能够很快的定位到客户端需要访问的存储服务器组是group1,并选择合适的存储服务器提供客户端访问。
存储服务器根据“文件存储虚拟磁盘路径”和“数据文件两级目录”可以很快定位到文件所在目录,并根据文件名找到客户端需要访问的文件。
第2-1-1章 FastDFS分布式文件服务背景及系统架构介绍的更多相关文章
- 一文搞定FastDFS分布式文件系统配置与部署
Ubuntu下FastDFS分布式文件系统配置与部署 白宁超 2017年4月15日09:11:52 摘要: FastDFS是一个开源的轻量级分布式文件系统,功能包括:文件存储.文件同步.文件访问(文件 ...
- Linux FastDFS 分布式文件系统安装
Linux FastDFS 分布式文件系统安装 2013 年 3 月 11 日 – 09:21 | 930 views | 收藏 (No Ratings Yet) FastDFS是一款类Google ...
- FastDFS分布式文件系统研究
FastDFS分布式文件系统 这个主要是针对应用型的,很使用,特别是对于电商等 一.编译安装 ubuntu平台: apt-get install libevent(这个默认就有,没有就装下) libe ...
- FastDFS分布式文件系统设计原理
转载自http://blog.chinaunix.net/uid-20196318-id-4058561.html FastDFS是一个开源的轻量级分布式文件系统,由跟踪服务器(tracker ser ...
- 1Nginx+fastdfs分布式文件存储
准备,将所需的软件传到服务器上,服务器的列表如下: fastdfs-nginx-module_v1.15.tar.gz FastDFS_v4.06.tar.gz libevent-2.0.21- ...
- FastDFS 分布式文件存储目录
1.fastdfs安装和配置 https://blog.csdn.net/hy245120020/article/details/78658081 2.使用nginx代理fastdfs以及图片裁剪(f ...
- FastDFS分布式文件系统安装与使用(单节点)
http://blog.csdn.net/xyang81/article/details/52837974 http://download.csdn.net/detail/xyang81/966749 ...
- 使用docker+consul+nginx集成分布式的服务发现与注册架构
一.环境说明: 1.一台虚拟机,该系统已经装好了docker: ip 192.168.10.224 虚拟网卡,与主机互通 操作系统rhel6 内核 2.6.32 64位 docker版本 1.7.1 ...
- 分布式、服务化的ERP系统架构设计
ERP之痛 曾几何时,我混迹于电商.珠宝行业4年多,为这两个行业开发过两套大型业务系统(ERP).作为一个ERP系统,系统主要功能模块无非是订单管理.商品管理.生产采购.仓库管理.物流管理.财务管理等 ...
随机推荐
- SpringBean的实例化
在Spring框架中,想使用Spring容器中的Bean,需要先实例化Bean SpringBean的实例化有3种方式 构造方法实例化 (最常用) 在Java配置类中,写一个构造方法,在这个构造方法中 ...
- 国家都给NISP证书的补贴了!关于NISP考试的政策有哪些?
NISP证书由中国信息安全测评中心依据中编办赋予"信息安全服务和信息安全专业人员的能力评估与资质审核"的职能而推出的证书,是中国信息安全测评中心代表国家实施的信息安全人员能力评定证 ...
- C#基础_手动书写XML
XML文档内容: 1.文档声明2.元素=标签 文档总至少要有一个根元素3.属性4.注释 <!--注释内容-->5.CDATA区.特殊字符 <![CDATA[不想解析的内容]]&g ...
- C#基础_变量的命名规则
变量: 1.作用 :可以让我们在计算机中存储数据 2.语法:变量类型 变量名=赋值: 3.常用的数据类型: int 整数类型 取值范围:最大2147483647;最小-214748364 ...
- 流媒体协议扫盲(rtp/rtcp/rtsp/rtmp/mms/hls)
RTP 参考文档 RFC3550/RFC3551 Real-time Transport Protocol)是用于Internet上针对多媒体数据流的一种传输层协议.RTP协议详细 ...
- torch.meshgrid
1:https://blog.csdn.net/weixin_39504171/article/details/106356977 2: https://pytorch.org/docs/stable ...
- Linux下自动删除过期备份和自动异地备份
每天自动删除过期备份 首先编写一个简单的Shell脚本DeleteExpireBackup.sh: #!/bin/bash # 修改需要删除的路径 location="/database/b ...
- web字体浮在图像中央
在做项目的过程中遇到了需要将图像作为背景,将字体显示在图像中央需求. 尝试了两种做法: 第一种方法为设置一个div设置属性为relative固定这个框的位置,将图片铺在div块里. 在div再设一个d ...
- 利用ldt_struct 与 modify_ldt 系统调用实现任意地址读写
利用ldt_struct 与 modify_ldt 系统调用实现任意地址读写 ldt_struct与modify_ldt系统调用的介绍 ldt_struct ldt是局部段描述符表,里面存放的是进程的 ...
- vscode常用快捷键及插件
macOS 全局 Command + Shift + P / F1 显示命令面板 Command + P 快速打开 Command + Shift + N 打开新窗口 Command + W 关闭窗口 ...