OpenAI CLIP 关键点 - 连接图像和文字
- 标签: #CLIP #Image2Text #Text2Image #OpenAI
- 创建时间:2023-04-21 00:17:52
基本原理
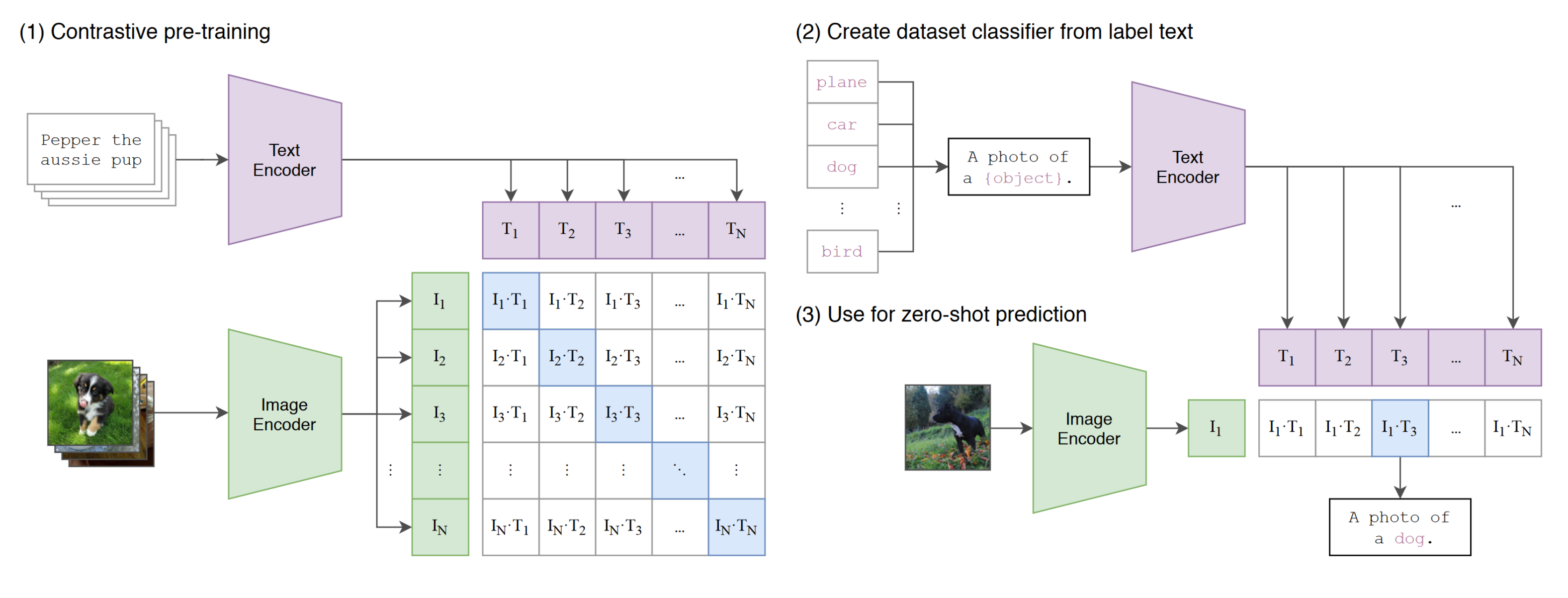
- CLIP是一个图像分类模型。
- 准备训练数据:准备大量的文本描述和图片的训练对,然后把进行对比训练。
- 文本描述和图片的训练对的数据获取:从互联网上获得400Million的图像文本数据对。这个 规模大致和GPT-2的数据规模相当。
1. 好处1:数据获取容易。传统的做法会对图像进行分类,以ImageNet为例,获得图片后需要人工进行分类标注,这个周期长成本高。
2. 好处2:迁移能力强。过去是精确分类一张图片,这样当出现一个未包含的图片的时候,在已知图片分类里就找不到对应的答案了。而CLIP因为训练的素材里面的描述是文本性的(而不是一两个单词的简单分类名称),因此它获得了更好的泛化能力。 - 因为有了这么大的数据,所以需要更好大量的算力,以及优质的算法。
- Text Encoder采用的是Transformer。
- Image Encoder采用的是Vision Transformer。
- 整个计算在256个V100 GPU上训练2周(12天),得出了ViT-L/14@336px模型。
- CLIP的设计初衷是为了能够做到零样本迁移(Zero-Shot)到下游数据集上的,也就是说,希望训练完的模型,在遇到一个完全没有见过的图片训练集的时候,可以进行高效的分类。为了达到这个零样本学习的能力:
- 研发人员摒弃了传统的数据集,因为传统的数据集通常是建立在明确分类基础上的,所以当一个新分类的图片出现的时候,这个模型就不知所措了。
- 把一般的分类换成一个描述性的文本,则可以比较好的解决这个问题。这里列出了他们准备文本描述的模板,通过这些模板,可以把一个带有歧义的单词,变成一个有意义的图像描述,比如论文里举例:boxer,当只提到这个词的时候,我们可能以为它是个拳击手,但是当结合了模板
A photo of a {label}, a type of pet.(其中{label}替换成boxer)那么boxer就可以被理解为一种狗(其中在生成数据的时候,比如a type of pet部分也是可以自动拼进去的,比如图片本来就来自牛津词典宠物图片集,那么自然就可以增加这样的分类信息,这会进一步让图像识别变得更加精准)。
- 主要用途:图像搜索(基于文本)、自然语言描述图像等。
- 限制:参考论文P18(6. Limitations)
- 结果:CLIP在Zero-Shot的情况下,在大部分常见数据集上都比特定训练的模型表现的好。在一些特别的模型基础上,Zero-Shot可能不一定有很好的效果,但是进行Few-shot则比特定训练的模型表现要好,因此模型具备很强的迁移能力。
- 引发的思考:
- 数据量大,就可以获得不一样的研究方法和模型效果。其实CLIP用到的方法并不新鲜,前人也有用过类似的方法,但是因为没有采用这么大的数据量,所以没有达到SOTA的效果。
- 模型的输入输出都变成了token,也可以理解都都是文本,它和NLP领域的GPT模型带来的颠覆性相似。
- 因为是一般性的文本描述,而不是特定分类描述,所以模型具备了多模态的特性。
- 因为是一般性的文本描述,所以模型可以用于自然语言描述图像。
- 这个项目的训练方法没有开源,但是训练结果的模型开源了。
基于CLIP延展的项目
- StyleCLIP:变化发型、眼睛等。
- CLIPDraw :CLIPDraw: Exploring Text-to-Drawing Synthesis through Language-Image Encoders 可以通过CLIP绘制一些蜡笔画。
- Paper:Open-Vocabulary Object Detection Using Captions 基于字幕的开放词汇目标检测 目标检测。
- Contrastive Language-Image Forensic Search 基于文本对视频中的内容进行检索。
参考资料
- Paper: Learning Transferable Visual Models From Natural Language Supervision 从自然语言监督中学习可迁移的视觉模型
- OpenAI | CLIP: Connecting text and images CLIP:连接文本和图像
转载请注明出处:https://www.cnblogs.com/volnet/p/openai-clip.html
OpenAI CLIP 关键点 - 连接图像和文字的更多相关文章
- 在OCR文字识别软件选项卡中怎么设置图像和文字
PDF是广泛使用的文档格式.在ABBYY Finereader中,PDF文档的显示不会因电脑不同而有差异,可加密保护,非常适合在电子存档中进行保存.下面给 大家讲解如何在PDF选项设置图像和文字. 图 ...
- Matlab绘图基础——给图像配文字说明(text对象)
text对象 (1)text(x坐标,y坐标,'string')在图形中指定位置(x,y)显示字符串string.(2)Editing有效值为on/off,off时,用户在执行GUI操作时无法直接 ...
- opencv图像加文字与运行时间
//获取推断时间 vector<double>layterTimings; double freq = getTickFrequency() / 1000; //得到ms double t ...
- 机器学习进阶-案例实战-图像全景拼接-图像全景拼接(RANSCA) 1.sift.detectAndComputer(获得sift图像关键点) 2.cv2.findHomography(计算单应性矩阵H) 3.cv2.warpPerspective(获得单应性变化后的图像) 4.cv2.line(对关键点位置进行连线画图)
1. sift.detectAndComputer(gray, None) # 计算出图像的关键点和sift特征向量 参数说明:gray表示输入的图片 2.cv2.findHomography(kp ...
- OpenAI Java SDK——chatgpt-java-v1.0.3更新支持GPT-3.5-Turbo,支持语音转文字,语音翻译。
简介 chatgpt-java是一个OpenAI的Java版SDK,支持开箱即用.目前以支持官网全部Api.支持最新版本GPT-3.5-Turbo模型以及whisper-1模型.增加chat聊天对话以 ...
- [ javascript css clip ] javascript css clip 的奇思妙想之文字拼接效果
语法: clip : auto | rect ( number number number number ) 参数: auto : 对象无剪切 rect ( number number numbe ...
- Zybo智能小车识别图像中的文字
智能小车识别图像中的文字 [TOC] 运行平台 这次的内容是基于Xilinx公司的Zybo开发板以及其配套的Zrobot套件开发 Zybo上面的sd卡搭载了Ubuntu12.04LTS的linux版本 ...
- javacpp-opencv图像处理之1:实时视频添加文字水印并截取视频图像保存成图片,实现文字水印的字体、位置、大小、粗度、翻转、平滑等操作
欢迎大家积极开心的加入讨论群 群号:371249677 (点击这里进群) javaCV图像处理系列: javaCV图像处理之1:实时视频添加文字水印并截取视频图像保存成图片,实现文字水印的字体.位置. ...
- 使用 Python 识别并提取图像中的文字
1. 介绍 介绍使用 python 进行图像的文字识别,将图像中的文字提取出来,可以帮助我们完成很多有趣的事情. 2. 必备工具 tesseract-ocr 下载地址: https://github. ...
- 《Hierarchical Text-Conditional Image Generation with CLIP Latents》阅读笔记
概括 模型总述 本篇论文主要介绍DALL·E 2模型,它是OpenAI在2022年4月推出的一款模型,OpenAI在2021年1月推出了DALL·E模型,2021年年底推出了GLIDE模型. DALL ...
随机推荐
- 无法将类 org.example.sh.utils.PageInfo<T>中的构造器 PageInfo应用到给定类型;
是因为没有在工具类中加入构造器, @Data @NoArgsConstructor @AllArgsConstructor @ToString
- 微信公众号授权登录,整合spring security
公司的业务需求,对接了微信公众号授权,通过微信公众号的接口拿到用户信息进行业务系统的登录,话不多说上代码,我的实现方式是整合了spingSecurity 首先是接口 @PostMapping(&quo ...
- 代码片断:GDI绘制带一定角度的椭圆
//先将DXF文件中的Ellipse 解析到elpList 中 foreach (Ellipse ellipse in elpList) { //定义一个矩形 RectangleF rect = ne ...
- Apache Ranger系列九:修改源码支持URI类型为s3的操作
问题描述:ranger在checkPrivileges(org.apache.ranger.authorization.hive.authorizer.RangerHiveAuthorizer)时,当 ...
- DNS Capture: UDP, TCP, IP-Fragmentation, EDNS, ECS, Cookie
EDNS 扩展实现"EDNS Client Subnet" (ECS) 和 DNS cookies.' 这里不讨论相关概念,实现如有疑问请查看: https://weberblog ...
- python实例1(石头 剪刀 布)
#random .randint 模块导入 import random #定义一个用户需要输入的数据内容入口 user = int(input("请输入(石头1,剪刀2,布3 ...
- Quine-McCluskey两级逻辑化简算法原理解析
转载请务必注明出处:https://www.cnblogs.com/the-wind/p/15764283.html 目录 1 背景介绍:两级逻辑 2 Quine-McCluskey两级逻辑化简 2. ...
- Spring Boot笔记--Spring Boot相关介绍+快速入门
相关介绍 简化了Spring开发,避免了Spring开发的繁琐过程 提供了自动配置.起步依赖.辅助功能 快速入门 结果呈现: 相关过程: helloController.java package or ...
- 如何使用 vue + intro 实现后台管理系统的引导
引言 为了让用户更好的适应新版,或更方便使用公司内部系统,可以加入新手指引功能.如果你也想在自己的网页加入用户指引,那就试试在 vue 中使用 Intro.js 吧,它能够很轻松的制作出新手指引的效果 ...
- 可靠消息最终一致性【本地消息表、RocketMQ 事务消息方案】
更多内容,前往IT-BLOG 一.可靠消息最终一致性事务概述 可靠消息最终一致性方案是指当事务发起方执行完成本地事务后并发出一条消息,事务参与方(消息消费者)一定能够接收消息并处理事务成功,此方案强调 ...