PostgreSQL-HA 高可用集群在 Rainbond 上的部署方案
PostgreSQL 是一种流行的开源关系型数据库管理系统。它提供了标准的SQL语言接口用于操作数据库。
repmgr 是一个用于 PostgreSQL 数据库复制管理的开源工具。它提供了自动化的复制管理,包括:
- 故障检测和自动故障切换:repmgr 可以检测到主服务器故障并自动切换到备用服务器。
- 自动故障恢复:repmgr 可以检测到从服务器故障并自动将其重新加入到复制拓扑中。
- 多个备用服务器:repmgr 支持多个备用服务器,可以在主服务器故障时自动切换到最合适的备用服务器。
- 灵活的复制拓扑:repmgr 支持各种复制拓扑,包括单主服务器和多主服务器。
- 管理和监控:repmgr 提供了用于管理和监控PostgreSQL复制的各种工具和命令。
可以说 repmgr 是一个扩展模块,简化了 PostgreSQL 复制的管理和维护,提高系统的可靠性和可用性。它是一个非常有用的工具,特别是对于需要高可用性的生产环境。同时 repmgr 也是由 Postgresql 社区开发以及维护的。
Pgpool 是一个高性能的连接池和负载均衡器,用于 PostgreSQL 数据库。Pgpool 可以作为中间层,位于客户端和 PostgreSQL 服务器之间,来管理连接请求并分配给不同的 PostgreSQL 服务器进行处理,以提高整体的系统性能和可用性。Pgpool 的一些主要功能包括:
- 连接池:Pgpool在应用程序和数据库之间建立一个连接池,使得多个应用程序可以共享一组数据库连接,避免了重复的连接和断开。
- 负载均衡:Pgpool可以将客户端请求均衡地分配到多个PostgreSQL服务器上,以实现负载均衡和更好的性能。
- 高可用性:Pgpool可以检测到PostgreSQL服务器的故障,并自动将客户端请求重新路由到其他可用服务器,从而提高系统的可用性和稳定性。
- 并行查询:Pgpool可以将大型查询分成几个子查询,然后将这些子查询并行发送到多个PostgreSQL服务器上执行,以提高查询性能。
本文将介绍在 Rainbond 上使用 Postgresql-repmgr + Pgpool 实现 Postgresql 高可用集群的部署和管理。
架构
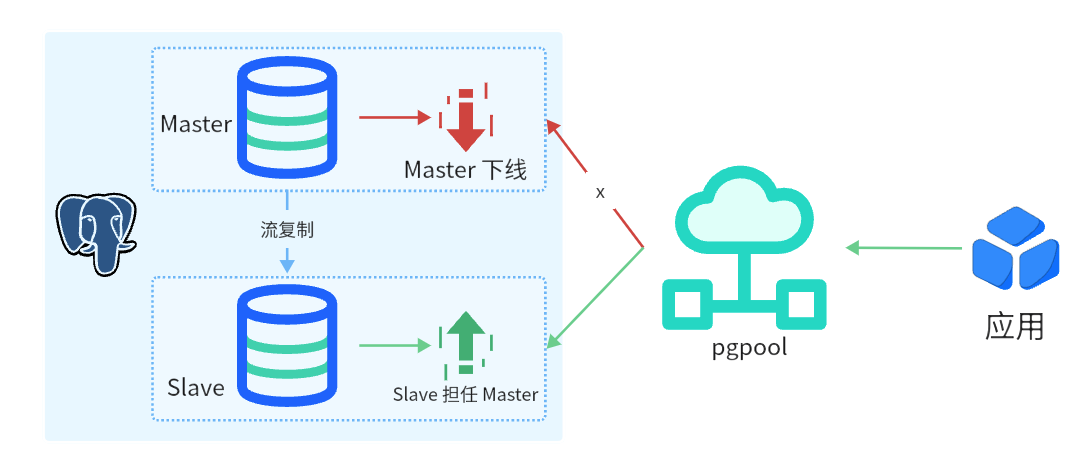
当使用 Postgresql HA 集群时,应用只需连接 pgpool 即可。
- 通过 pgpool 实现读写分离,写入操作由 Master 执行,读取操作由 Slave 执行。
- 由 repmgr 实现流复制,Master 数据自动复制到 Slave。
- 当 Master 遇故障下线时,由 repmgr 自定选择 Slave 为 Master,并继续执行写入操作。
- 当某个节点遇故障下线时,由 pgpool 自动断开故障节点的连接,并切换到可用的节点上。
部署 Rainbond
安装 Rainbond,可通过一条命令快速安装 Rainbond,或选择 基于主机安装 和 基于 Kubernetes 安装 Rainbond。
curl -o install.sh https://get.rainbond.com && bash ./install.sh
通过 Rainbond 开源应用商店部署 PostgreSQL 集群
Postgresql HA 集群已发布到 Rainbond 开源应用商店,可一键部署 Postgresql HA 集群。
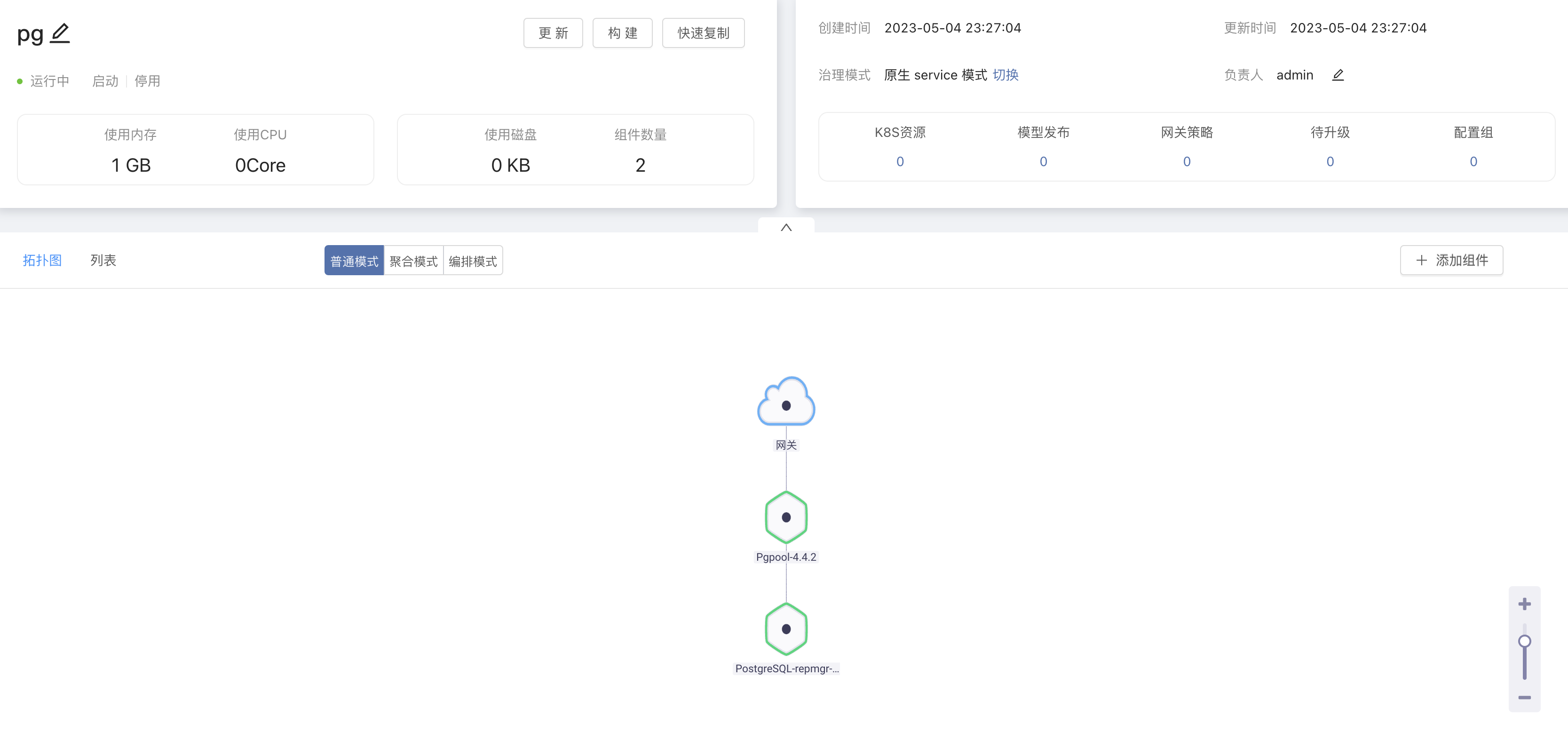
登陆 Rainbond 控制台,进入 平台管理 -> 应用市场 -> 开源应用商店 中搜索 postgresql-ha 并安装。

安装完成后的拓扑图如下。
配置 Pgpool 组件
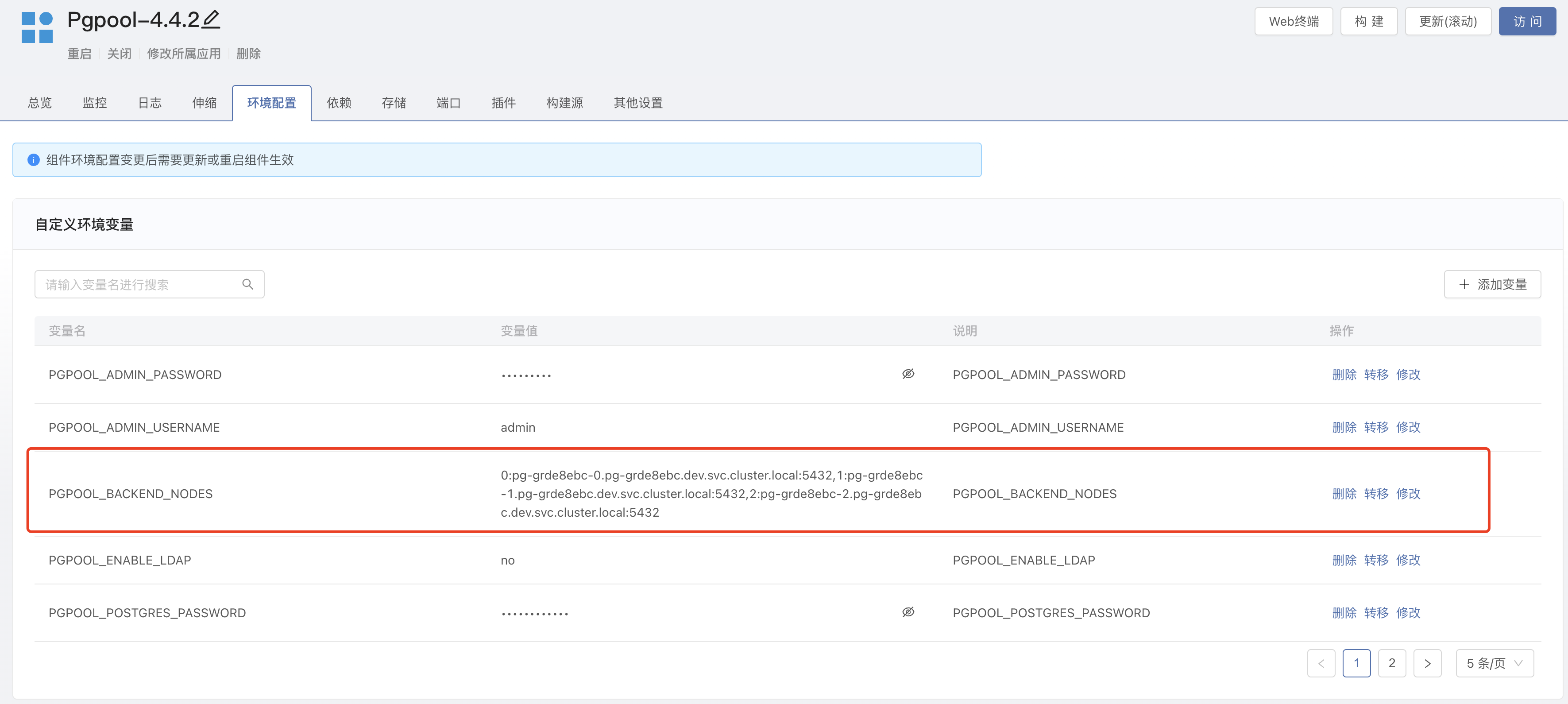
- 获取 PostgreSQL-repmgr 连接地址,进入 PostgreSQL-repmgr 组件的 Web 终端内。
env | grep REPMGR_PARTNER_NODES

- 将上述的内容复制出并修改成以下格式,然后进入 Pgpool 组件内,修改
PGPOOL_BACKEND_NODES环境变量,并更新组件。
0:pg-grde8ebc-0.pg-grde8ebc.dev.svc.cluster.local:5432,1:pg-grde8ebc-1.pg-grde8ebc.dev.svc.cluster.local:5432,2:pg-grde8ebc-2.pg-grde8ebc.dev.svc.cluster.local:5432
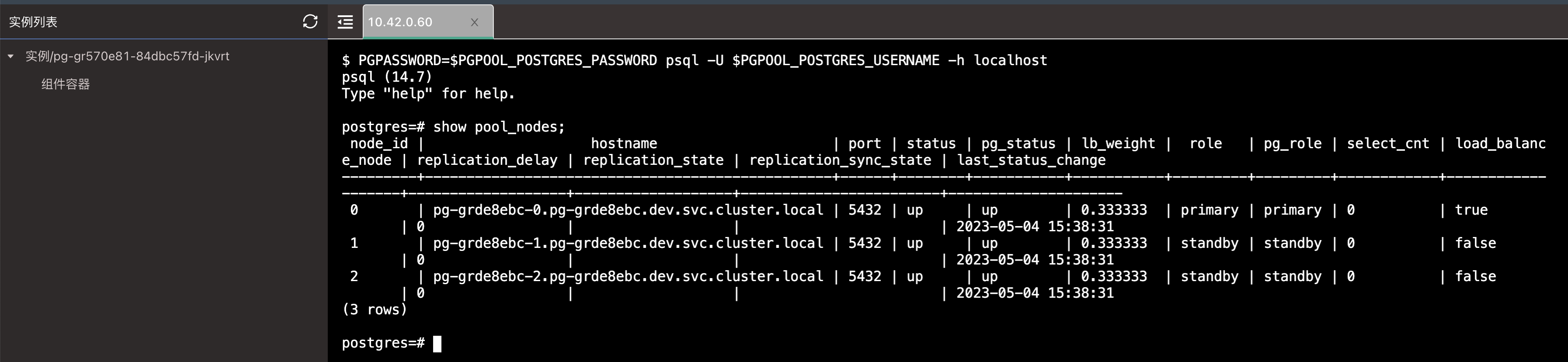
- 验证集群,进入 Pgpool 组件的 Web 终端中。
# 连接 postgresql
PGPASSWORD=$PGPOOL_POSTGRES_PASSWORD psql -U $PGPOOL_POSTGRES_USERNAME -h localhost
# 查询集群节点
show pool_nodes;
status 字段均为 UP 即可。
从零开始部署 PostgreSQL 集群
从零开始在 Rainbond 上部署 Postgresql HA 集群也是非常简单的,大致分为以下几个步骤:
- 基于镜像部署 PostgreSQL-repmgr 组件,并修改组件配置。
- 基于镜像部署 pgpool 组件,并修改组件配置。
- 建立组件之间的依赖关系。
镜像均采用 bitnami 制作的 postgresql-repmgr 和 pgpool,因 bitnami 制作的镜像将很多配置文件都抽离成了环境变量,配置比较方便。
部署 PostgreSQL-repmgr 组件
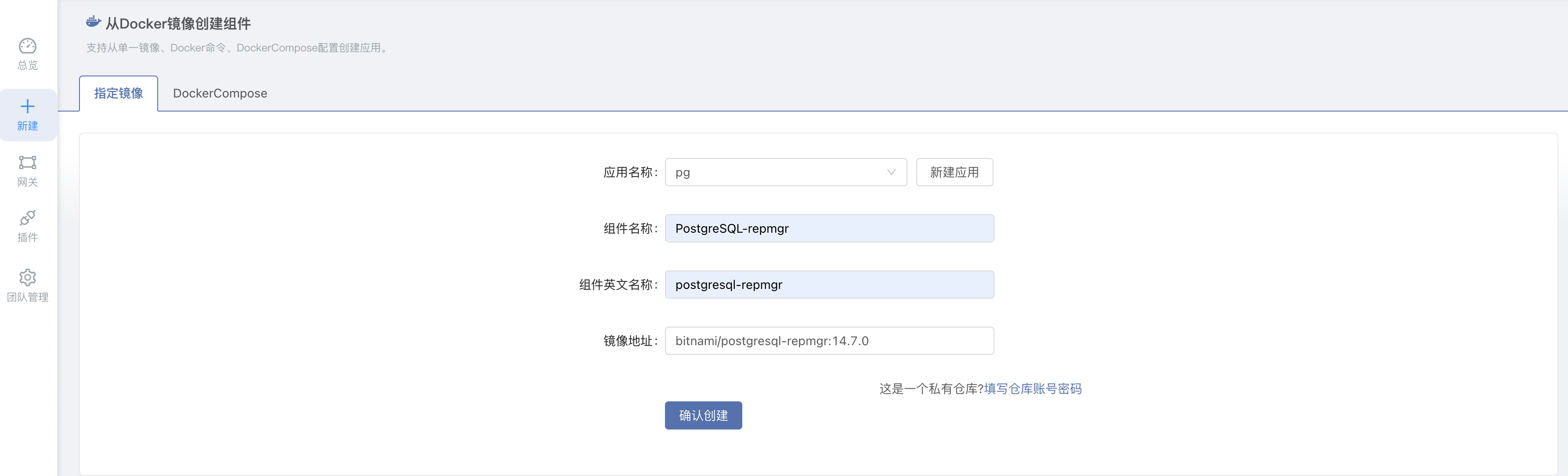
1. 创建组件
进入团队内 -> 新建组件 -> 基于镜像创建组件,应用、组件、英文名称等自定义即可,镜像填写 bitnami/postgresql-repmgr:14.7.0。
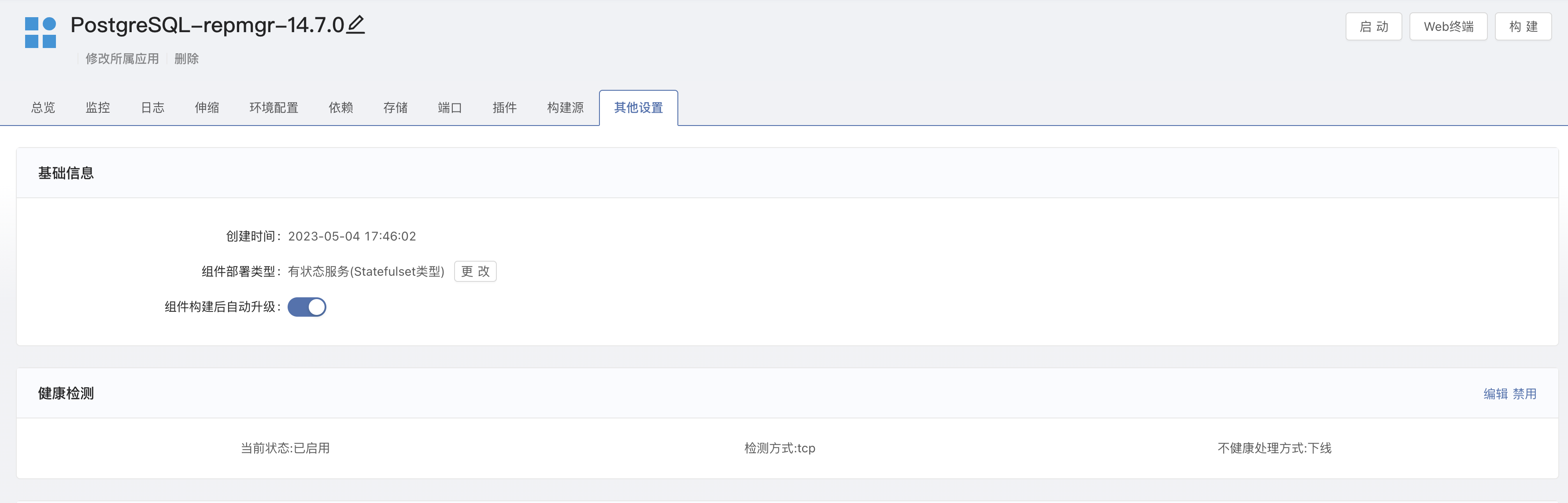
2. 修改组件类型
进入组件内 -> 其他设置,将组件部署类型修改为 有状态服务。
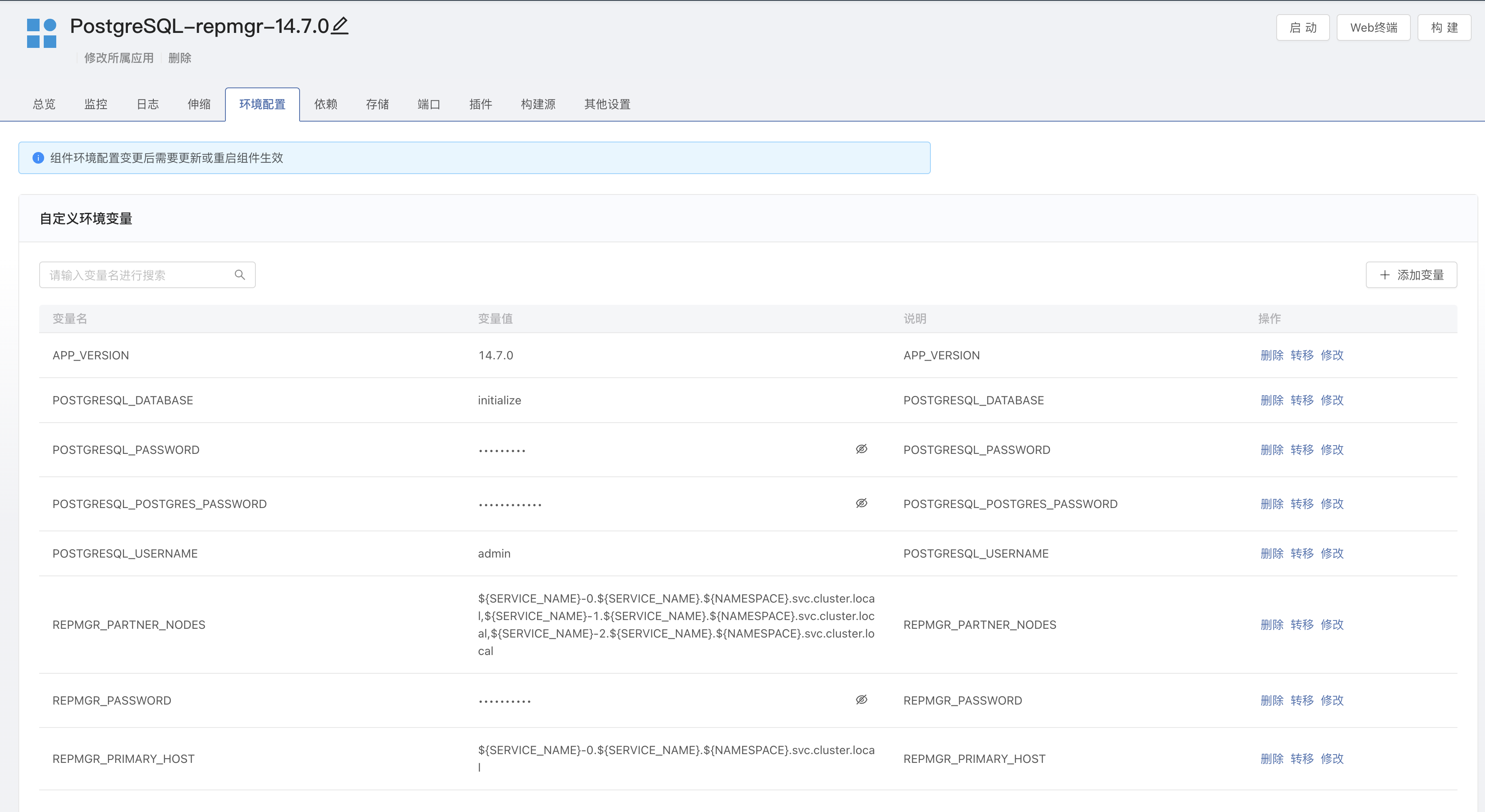
3. 添加环境变量
进入组件内 -> 环境变量,新增以下环境变量:
# 默认初始化的数据库
POSTGRESQL_DATABASE=initialize
# 创建普通用户和密码
POSTGRESQL_USERNAME=admin
POSTGRESQL_PASSWORD=admin@123
# 管理员 postgres 密码
POSTGRESQL_POSTGRES_PASSWORD=postgres@123
# repmgr 用户密码
REPMGR_PASSWORD=repmgrpass
# 初始化主节点的 HOST。Rainbond 控制台自动渲染 SERVICE_NAME 变量,获取当前 Statefulset 的控制器名称。
REPMGR_PRIMARY_HOST=${SERVICE_NAME}-0.${SERVICE_NAME}.${NAMESPACE}.svc.cluster.local
# 集群中的所有节点,以逗号分隔
REPMGR_PARTNER_NODES=${SERVICE_NAME}-0.${SERVICE_NAME}.${NAMESPACE}.svc.cluster.local,${SERVICE_NAME}-1.${SERVICE_NAME}.${NAMESPACE}.svc.cluster.local,${SERVICE_NAME}-2.${SERVICE_NAME}.${NAMESPACE}.svc.cluster.local
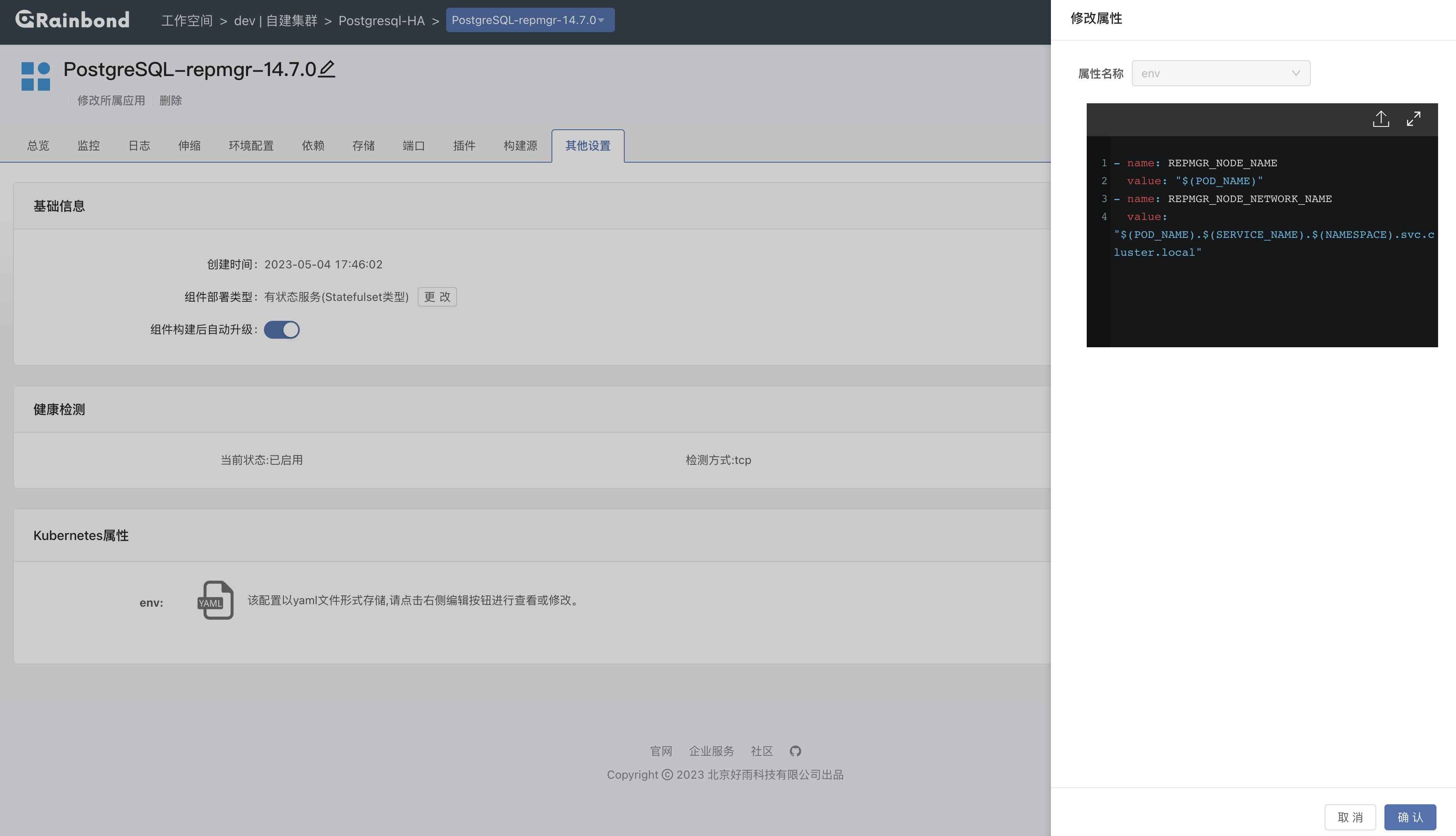
进入组件内 -> 其他设置,添加 Kubernetes 属性,选择 env,添加以下内容:
# repmgr 节点名称
- name: REPMGR_NODE_NAME
value: "$(POD_NAME)"
# repmgr 节点网络名称
- name: REPMGR_NODE_NETWORK_NAME
value: "$(POD_NAME).$(SERVICE_NAME).$(NAMESPACE).svc.cluster.local"
### "$(POD_NAME)" 用于定义 env 之间的相互依赖
4. 添加组件存储
进入组件内 -> 存储,添加新的存储,存储路径为 /bitnami/postgresql,其他自定义即可。
5. 启动组件
在组件视图内构建组件等待构建完成并启动。
6. 修改组件实例数量
进入组件内 -> 伸缩,将组件实例数量设置为 3,等待所有实例启动即可。
部署 pgpool 组件
1. 创建组件
进入团队内 -> 新建组件 -> 基于镜像创建组件,应用、组件、英文名称等自定义即可,镜像填写 bitnami/pgpool:4.4.2。
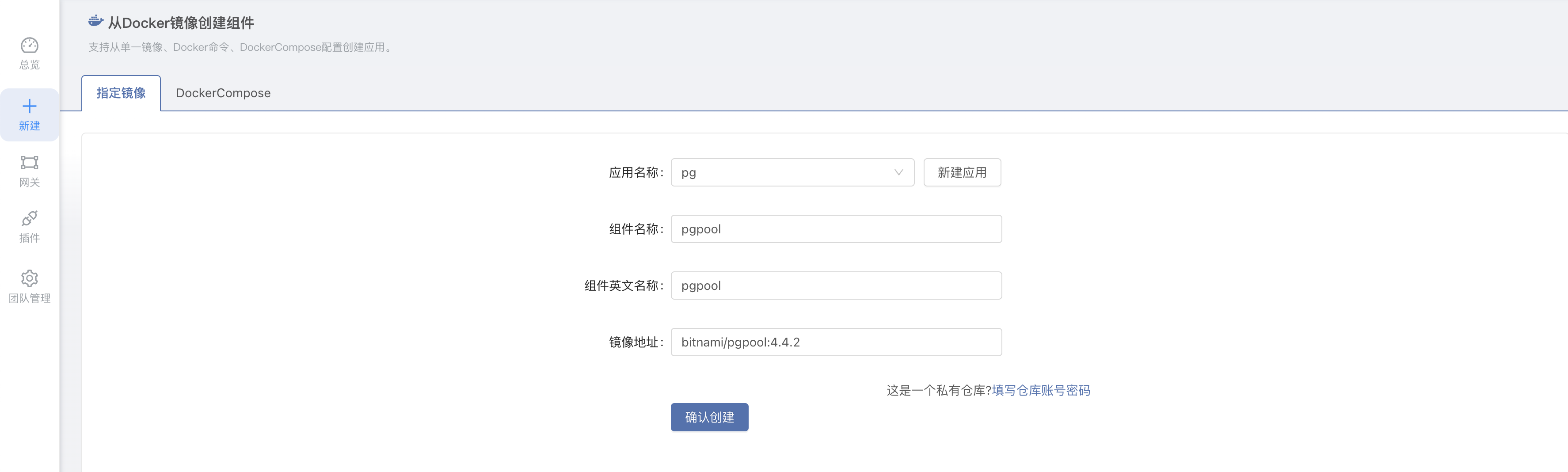
2. 添加环境变量
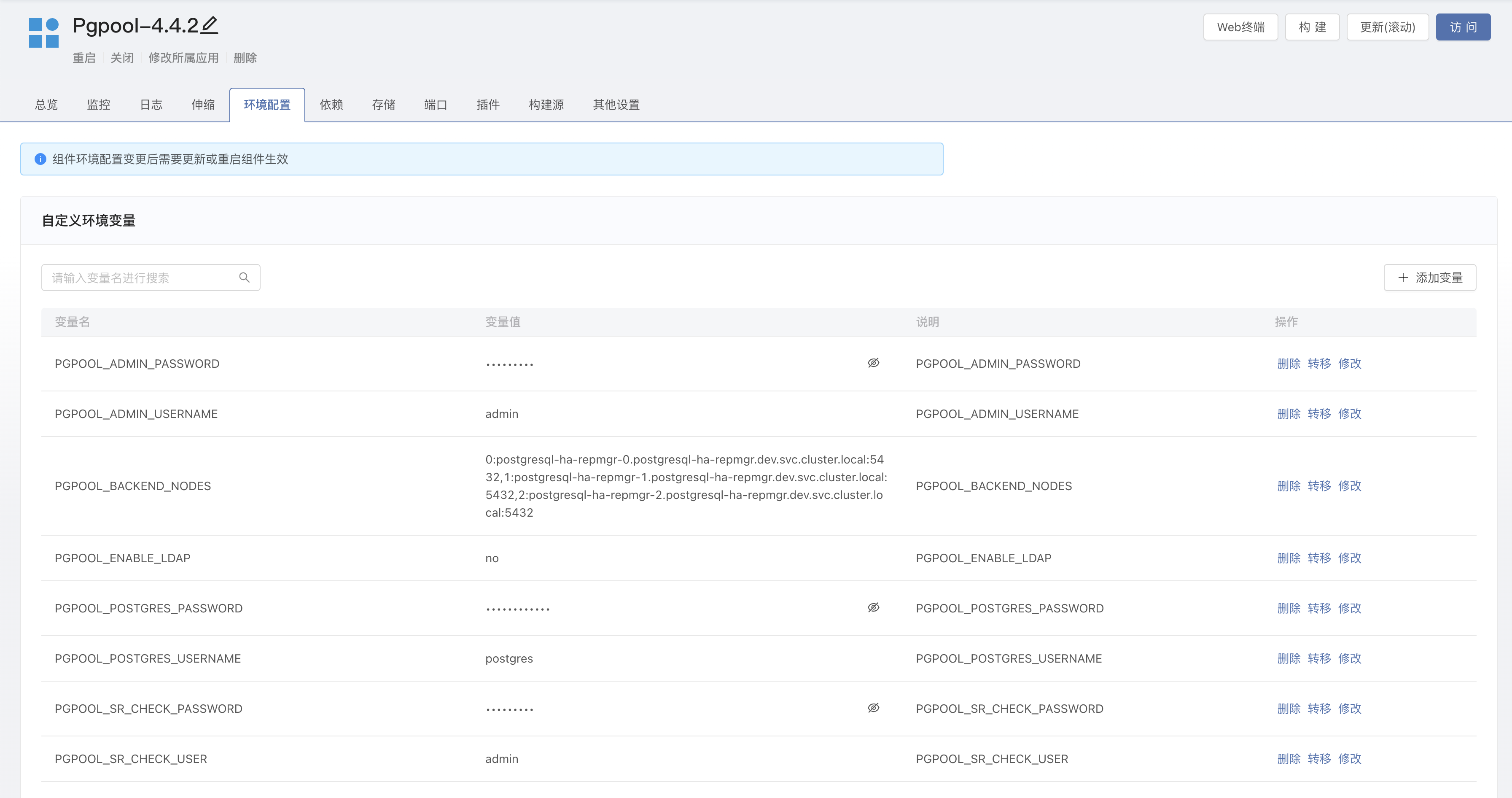
进入组件内 -> 环境变量,新增以下环境变量:
# pgpool admin 用户与密码
PGPOOL_ADMIN_USERNAME=admin
PGPOOL_ADMIN_PASSWORD=admin@123
# postgres 用户与密码
PGPOOL_POSTGRES_USERNAME=postgres
PGPOOL_POSTGRES_PASSWORD=postgres@123
# 用于执行流检查的用户和密码
PGPOOL_SR_CHECK_USER=admin
PGPOOL_SR_CHECK_PASSWORD=admin@123
# postgresql 后端节点。节点列表获取进入到 PostgreSQL-repmgr 组件的 Web 终端内,使用 env | grep REPMGR_PARTNER_NODES 命令获取,然后修改为以下格式
PGPOOL_BACKEND_NODES=0:postgresql-ha-repmgr-0.postgresql-ha-repmgr.dev.svc.cluster.local:5432,1:postgresql-ha-repmgr-1.postgresql-ha-repmgr.dev.svc.cluster.local:5432,2:postgresql-ha-repmgr-2.postgresql-ha-repmgr.dev.svc.cluster.local:5432
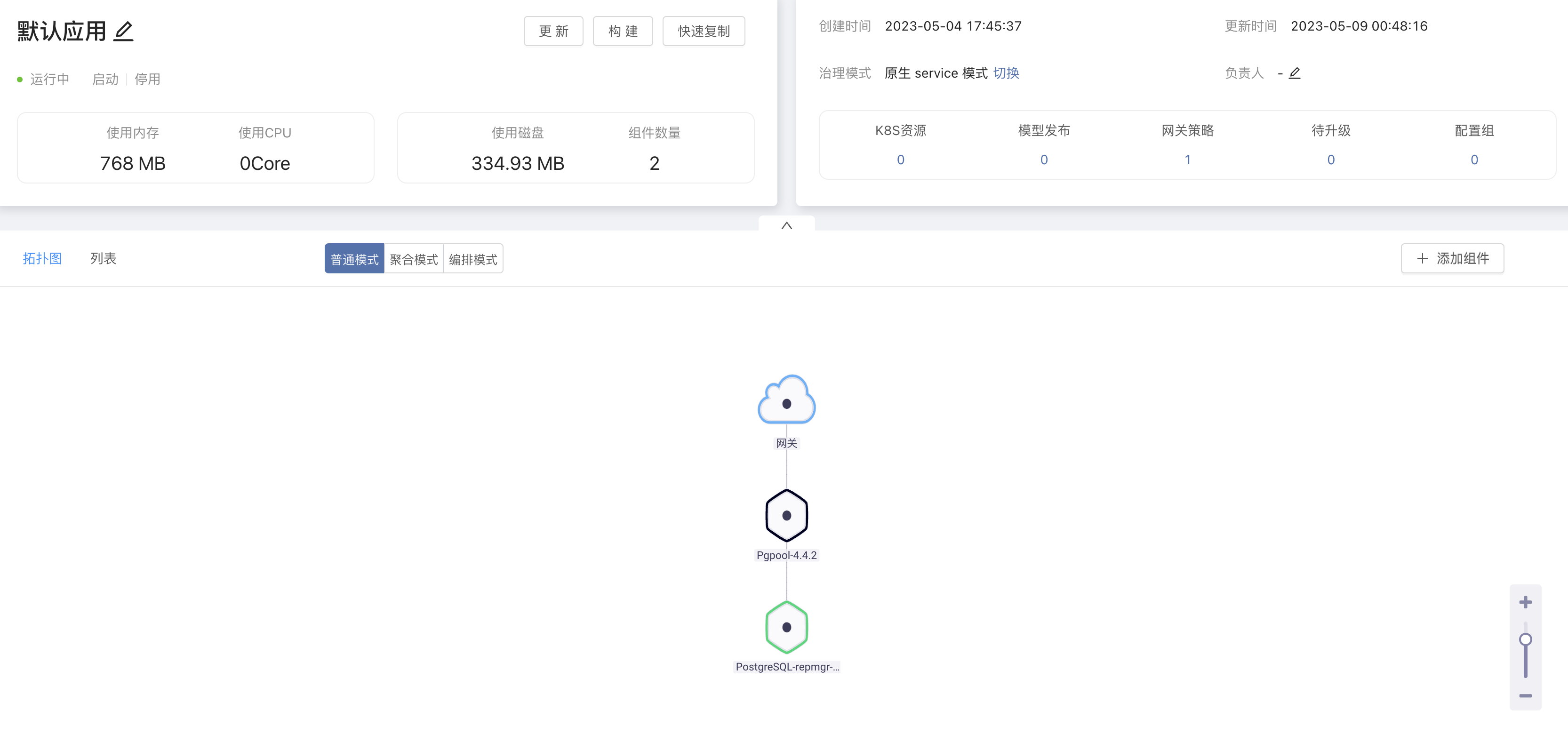
3. 添加依赖
在应用视图,将 pgpool 组件依赖至 PostgreSQL-repmgr 组件。
4. 启动组件
在 pgpool 组件视图内构建组件等待构建完成并启动。
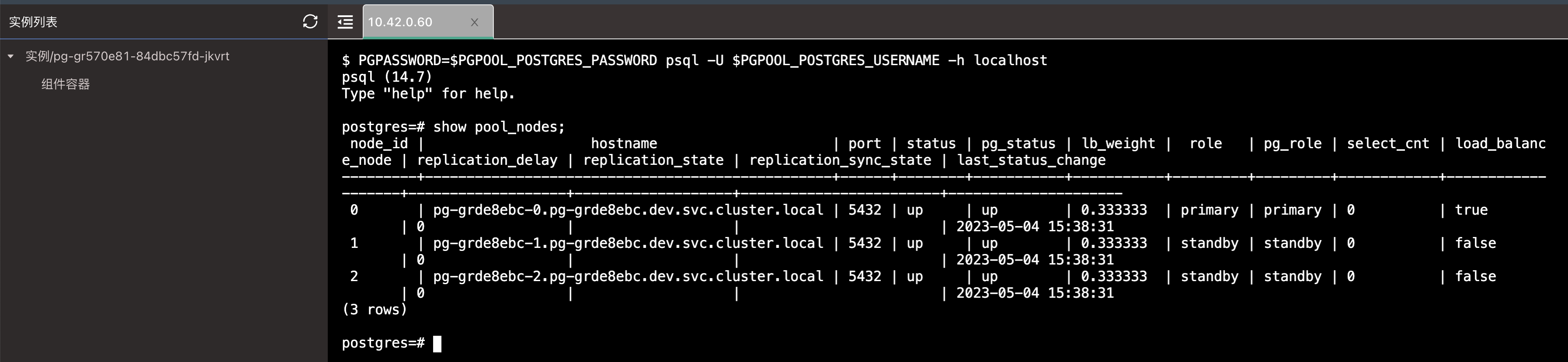
5. 验证集群
进入 Pgpool 组件的 Web 终端中,输入以下命令验证集群:
# 连接 postgresql
PGPASSWORD=$PGPOOL_POSTGRES_PASSWORD psql -U $PGPOOL_POSTGRES_USERNAME -h localhost
# 查询集群节点
show pool_nodes;
status 字段均为 UP 即可。
最后
外部连接
如想使用本地工具连接到 postgresql,可在 pgpool 组件的端口内打开对外服务端口,通过该端口连接到 postgresql,默认用户密码为 postgres/postgres@123。
验证高可用集群
为了保障高可用集群,Kubernetes 集群至少有 3 个节点,且底层存储使用分布式存储,如没有分布式存储,需将 Postgresql 存储切换为本地存储也可保障高可用集群的数据。可通过以下方式进行高可用集群验证:
- 通过 Pgpool 连接后,创建数据库并写入数据,再进入 PostgreSQL-repmgr 组件的 Web 终端内查询每个实例是否都有数据。
- 挂掉主节点,验证是否主节点自动切换并可正常连接并写入。
PostgreSQL-HA 高可用集群在 Rainbond 上的部署方案的更多相关文章
- Hadoop HA高可用集群搭建(Hadoop+Zookeeper+HBase)
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 一.服务器环境 主机名 IP 用户名 密码 安装目录 master188 192.168.29.188 hadoop hadoop /home/ha ...
- Hadoop 3.1.2(HA)+Zookeeper3.4.13+Hbase1.4.9(HA)+Hive2.3.4+Spark2.4.0(HA)高可用集群搭建
目录 目录 1.前言 1.1.什么是 Hadoop? 1.1.1.什么是 YARN? 1.2.什么是 Zookeeper? 1.3.什么是 Hbase? 1.4.什么是 Hive 1.5.什么是 Sp ...
- linux -- 基于zookeeper搭建yarn的HA高可用集群
linux -- 基于zookeeper搭建yarn的HA高可用集群 实现方式:配置yarn-site.xml配置文件 <configuration> <property> & ...
- centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课
centos HA高可用集群 heartbeat搭建 heartbeat测试 主上停止heartbeat服务 测试脑裂 两边都禁用ping仲裁 第三十二节课 heartbeat是Linu ...
- HA 高可用集群概述及其原理解析
HA 高可用集群概述及其原理解析 1. 概述 1)所谓HA(High Available),即高可用(7*24小时不中断服务). 2)实现高可用最关键的策略是消除单点故障.HA严格来说应该分成各个组件 ...
- 七、Hadoop3.3.1 HA 高可用集群QJM (基于Zookeeper,NameNode高可用+Yarn高可用)
目录 前文 Hadoop3.3.1 HA 高可用集群的搭建 QJM 的 NameNode HA Hadoop HA模式搭建(高可用) 1.集群规划 2.Zookeeper集群搭建: 3.修改Hadoo ...
- Kubeadm 1.9 HA 高可用集群本地离线镜像部署【已验证】
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,易宝支付,北森等等. kubernetes1.9版本发布2017年12月15日,每三个月一个迭代 ...
- [K8s 1.9实践]Kubeadm 1.9 HA 高可用 集群 本地离线镜像部署
k8s介绍 k8s 发展速度很快,目前很多大的公司容器集群都基于该项目,如京东,腾讯,滴滴,瓜子二手车,北森等等. kubernetes1.9版本发布2017年12月15日,每是那三个月一个迭代, W ...
- Hadoop HA 高可用集群的搭建
hadoop部署服务器 系统 主机名 IP centos6.9 hadoop01 192.168.72.21 centos6.9 hadoop02 192.168.72.22 centos6.9 ha ...
- Hadoop HA高可用集群搭建(2.7.2)
1.集群规划: 主机名 IP 安装的软件 执行的进程 drguo1 192.168.80.149 j ...
随机推荐
- vue input有值但还是验证不通过
验证失败原因: 因为input自动把输入的值转换为string类型,导致验证失败. 解决方案: 一. Input中的v-model改为v-model.number: 二.rules里面需要加type: ...
- ssh双击互信
默认公钥文件/root/.ssh/id_rsa.pub默认私钥文件/root/.ssh/id_rsa 只有将公钥文件文件拷到其他的服务器上才能登录别的服务器. 服务器A 192.168.1.133 ...
- 实验1.SDN拓扑实践
实验1:SDN拓扑实践 一.基本要求 (一)Mininet运行结果截图 (二) 使用Mininet的命令行生成如下拓扑: 1. 3台交换机,每个交换机连接1台主机,3台交换机连接成一条线. 2. 3台 ...
- [imx6ull] 源码下载
uboot git clone https://source.codeaurora.org/external/imx/uboot-imx cd uboot-imx make distclean mak ...
- 玩转SpringBoot原理:掌握核心技术,成为高级开发者
本文通过编写一个自定义starter来学习springboot的底层原理,帮助我们更好的使用springboot集成第三方插件 步骤一:创建项目 步骤二:添加依赖 步骤三:创建自动配置类 步骤四:创建 ...
- java循环结构中局部变量和成员变量
前言 在前两篇文章中,壹哥给大家讲解了Java里的条件分支,包括if和switch两种情况.我们知道,除了条件分支结构,还有循环结构,所以接下来的一个学习重点就是Java里的循环.但在学习循环之前,我 ...
- flutter feature---->quick action
reference: https://www.filledstacks.com/snippet/managing-quick-actions-in-flutter/ code import 'dart ...
- JetBrains 2022全家桶-激活
## JetBrains 全家桶 激活教程 https://tech.souyunku.com/?page_id=50199
- [MAUI 项目实战] 手势控制音乐播放器(一): 概述与架构
这是一篇系列博文.请关注我,学习更多.NET MAUI开发知识! [MAUI 项目实战] 手势控制音乐播放器(一): 概述与架构 [MAUI 项目实战] 手势控制音乐播放器(二): 手势交互 [MAU ...
- Idea快捷键——Extract Method
idea快捷键 ctrl+alt+M 作用:将一段代码提取为一个方法