8、ThreadPoolTaskExecutor线程并发
一、线程池的优点:
1、降低资源消耗。通过重复利用自己创建的线程降低线程创建和销毁造成的消耗。
2、提高响应速度。当任务到达时,任务可以不需要等到线程创建就能立即执行。
3、提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅会消耗资源,还会降低系统的稳定性,使用线程池可以进行统一分配,调优和监控。
二、ThreadPoolTaskExecutor实现线程并发:
ThreadPoolTaskExecutor是spring core包中的,而ThreadPoolExecutor是JDK中的JUC。ThreadPoolTaskExecutor是对ThreadPoolExecutor进行了封装处理。
1、声明ThreadPoolTaskExecutor线程池配置:
@Configuration
public class TaskPoolConfig {
/**
* ThreadPoolTaskExecutor是spring core包中的,而ThreadPoolExecutor是JDK中的JUC。
* ThreadPoolTaskExecutor是对ThreadPoolExecutor进行了封装处理。
*
* 拒绝策略:
* (1)、CallerRunsPolicy: 当触发拒绝策略,只要线程池没有关闭的话,则使用调用 线程直接运行任务。一般并发比较小,性能要求不高,不允许失败。
* 但是,由于调用者自己运行任务,如果任务提交速度过快,可能导致程序阻塞,性能效率上必然的损失较大
* (2)、AbortPolicy: 丢弃任务,并抛出拒绝执行
* (3)、RejectedExecutionException 异常信息。线程池默认的拒绝策略。必须处理好抛出的异常,否则会打断当前的执行流程,影响后续的任务执行。
* (4)、DiscardPolicy: 直接丢弃,其他啥都没有
* (5)、DiscardOldestPolicy: 当触发拒绝策略,只要线程池没有关闭的话,丢弃阻塞队列 workQueue 中最老的一个任务,并将新任务加入
*/
@Value("${async.thread.concurrency.coreSize:10}")
private int coreSize; @Value("${async.thread.concurrency.maxSize:20}")
private int maxSize; @Value("${async.thread.concurrency.queueCapacity:1000}")
private int queueCapacity; @Value("${async.thread.concurrency.keepAliveSeconds:10000}")
private int keepAliveSeconds; @Bean
public ThreadPoolTaskExecutor threadPoolTaskExecutor() {
final ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
executor.setCorePoolSize(coreSize); //核心线程数
executor.setMaxPoolSize(maxSize); //最大线程数
executor.setQueueCapacity(queueCapacity); //最大等待队列数
executor.setKeepAliveSeconds(keepAliveSeconds); //除核心线程,其他线程的保留时间
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.CallerRunsPolicy()); //等待队列满后的拒绝策略
executor.initialize(); //执行初始化
executor.setThreadNamePrefix("async-executor-"); //线程前缀名称
return executor;
}
}
2、业务类:
(1)、
@Service
@Slf4j
public class ThreadConcurrencyServiceImpl implements ThreadConcurrencyService {
@Autowired
private ThreadPoolTaskExecutor threadPoolTaskExecutor; //线程池配置声明 @Autowired
private GetCountData getCountData; @Override
public List<ThreadConcurrencyVO> getCountNum() {
StopWatch stopWatch = new StopWatch("ThreadPoolTaskExecutor多线程方式执行任务");
stopWatch.start();
log.info("====================ThreadPoolTaskExecutor多线程方式执行任务开始========================"); List<ThreadConcurrencyVO> list = getListData(); stopWatch.stop();
log.info("====================ThreadPoolTaskExecutor多线程方式执行任务结束========================");
log.info(stopWatch.prettyPrint());
return list;
} //========================================业务逻辑==================================
/**
* 多线程方式
* */
private List<ThreadConcurrencyVO> getListData(){
List<ThreadConcurrencyVO> list = new ArrayList<>(); //获取一间教室下数据的线程
Integer testNumOne = 0;
Double avgGradeOne = 0.0;
log.info("线程一执行");
Callable<Map<String, QueryVO>> oneRoomData = () -> getCountData.getData(1);
Future<Map<String, QueryVO>> oneRoomFuture = threadPoolTaskExecutor.submit(oneRoomData); //获取二间教室下数据的线程
Integer testNumTwo = 0;
Double avgGradeTwo = 0.0;
log.info("线程二执行");
Callable<Map<String, QueryVO>> twoRoomData = () -> getCountData.getData(2);
Future<Map<String, QueryVO>> twoRoomFuture = threadPoolTaskExecutor.submit(twoRoomData); try {
//获取一间教室下数据
Map<String, QueryVO> oneRoomMap = oneRoomFuture.get();
testNumOne = oneRoomMap.get("testCount").getTestNum();
avgGradeOne = oneRoomMap.get("testCount").getAvgGrade();
//获取二间教室下数据
Map<String, QueryVO> twoRoomMap = twoRoomFuture.get();
testNumTwo = twoRoomMap.get("testCount").getTestNum();
avgGradeTwo = twoRoomMap.get("testCount").getAvgGrade(); //List集合返回数据
ThreadConcurrencyVO threadConcurrencyVO1 = ThreadConcurrencyVO.builder()
.uuid(UUID.randomUUID().toString())
.name("ONE")
.testNum(testNumOne)
.avgGrade(avgGradeOne)
.build();
ThreadConcurrencyVO threadConcurrencyVO2 = ThreadConcurrencyVO.builder()
.uuid(UUID.randomUUID().toString())
.name("TWO")
.testNum(testNumTwo)
.avgGrade(avgGradeTwo)
.build();
list.add(threadConcurrencyVO1);
list.add(threadConcurrencyVO2); } catch (InterruptedException e) {
log.info("线程中断异常:{}", e.getMessage());
} catch (ExecutionException e) {
log.info("线程执行异常:{}", e.getMessage());
}
log.info("返回结果:"+list);
return list;
}
}
(2)、
@Override
public Map<String, QueryVO> getData(Integer room) {
Map<String, QueryVO> mapData = new HashMap<>(); //Atomic家族(事务的四个特性ACID,其中A就是原子性)主要是保证多线程环境下的原子性(指一个操作是不可中断的,同时成功,同时失败),相比synchronized而言更加轻量级
AtomicInteger testNum = new AtomicInteger(0);
AtomicReference<Double> avgGrade = new AtomicReference<>(0.0); Integer num = 0;
double avg = 0.0;
for (int i = 0; i < room * 30; i++) {
num++;
}
avg = num / (num + 1000.0);
//统计测试人数
testNum.set(num);
//计算占比值
avgGrade.set(avg); QueryVO queryVO = QueryVO.builder()
.testNum(testNum.get())
.avgGrade(avgGrade.get())
.build();
mapData.put("testCount", queryVO); return mapData;
}
三、线程池底层工作原理:
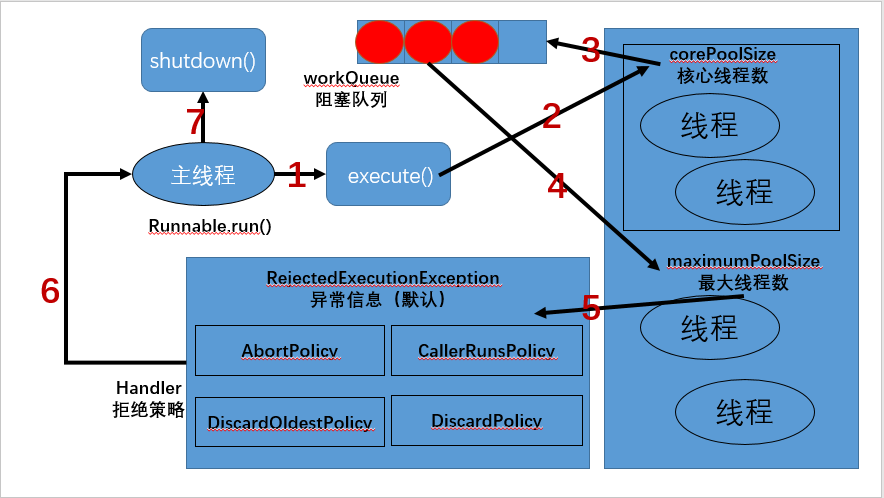
1、在创建了线程池后,等待提交过来的任务请求。
2、当调用execute()方法添加一个请求任务时,线程池会做如下判断:
(1)、如果正在运行的线程数量小于corePoolSize(线程池的核心线程数),那么马上创建线程运行这个任务;
(2)、如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入workQueue阻塞队列中;
(3)、如果这时候workQueue阻塞队列饱和且正在运行的线程数量还小于 maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
(4)、如果workQueue 阻塞队列满了且正在运行的线程数量大于或等于 maximumPoolSize(即:workQueue.size() + maximumPoolSize),那么线程池会启动饱和拒绝策略来执行。
3、当一个线程完成任务时,它会从workQueue 阻塞队列中取下一个任务来执行。
4、当一个线程无事可做,超过一定的时间(keepAliveTime) 时,线程池会判断:
如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
四、Thread类、Runnable接口与Callable接口的区别:
1、实现 Runnable 接口相比继承 Thread 类的优势:
(1)、可以避免由于 Java 的单继承特性而带来的局限
(2)、增强程序的健壮性,代码能够被多个线程共享,代码与数据是独立的
(3)、线程池只能放入实现 Runable 或 Callable 类线程,不能直接放入继承 Thread 的类
2、实现 Runnable 接口和实现 Callable 接口的区别:
(1)、Runnable 是自从 java1.1 就有了,而 Callable 是 1.5 之后才加上去的
(2)、实现 Callable 接口的任务线程能返回执行结果,而实现 Runnable 接口的任务线程不能返回结果
(3)、Callable 接口的 call()方法允许抛出异常,而 Runnable 接口的 run()方法的异常只能在内部消化,不能继续上抛
(4)、加入线程池运行,Runnable 使用 ExecutorService 的 execute 方法,Callable 使用 submit 方法
注:Callable 接口支持返回执行结果,此时需要调用 FutureTask.get()方法实现,此方法会阻塞主线程直到获取返回结果,当不调用此方法时,主线程不会阻塞
五、Future接口与FutureTask类获取Callable线程的返回结果详解:
在并发编程中,我们经常用到非阻塞的模型,在多线程的三种实现方式中,不管是继承Thread类还是实现Runnable接口,都无法保证获取到之前的执行结果。而使用Callable接口创建线程,需要实现call()方法,call()在完成时返回结果必须存储在主线程已知的对象中,可以使用Future接口或FutureTask类获取该线程的返回结果。
源码:get()用于获取任务的结果
public Object get()throws InterruptedException,ExecutionException;
1、Future对象可以在后台完成主线程中比较耗时的操作,但不会导致主线程阻塞,当主线程将来需要其执行结果时,可通过Future对象获得后台作业的计算结果或者执行状态。
2、FutureTask多用于耗时的计算,主线程可以在完成自己的任务后,再去获取结果
3、Future对象或FutureTask对象调用get()方法获取结果只有在计算完成时获取,否则会一直阻塞直到任务转入完成状态,一旦计算完成,就不能再重新开始或取消计算,只会返回结果或者抛出异常。
六、线程池中submit()和execute()方法的区别:
1、execute():只能执行Runnable 类型的任务。
2、submit():可以执行Runnable和Callable类型的任务。
Callable 类型的任务可以获取执行的返回值,而Runnable执行无返回值。
七、多线程之Atomic原子类:
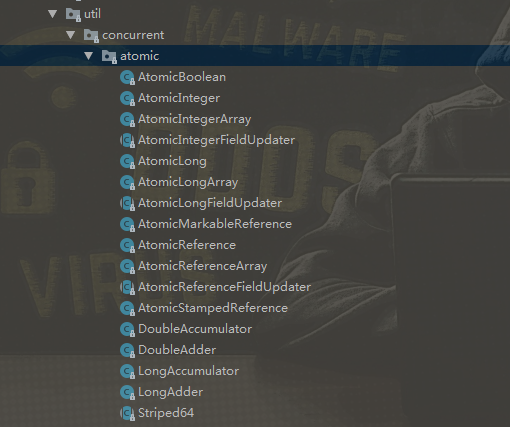
1、Atomic原子类:
Atomic (事务的四个特性ACID,其中A就是原子性) 指一个操作是不可中断的。即使是在多个线程一起执行的时候,一个操作一旦开始,就不会被其他线程干扰。所以,所谓原子类说简单点就是具有原子/原子操作特征的类。
原子类存放在java.util.concurrent.atomic下:
2、实现原理:
Atomic类主要利用CAS (Compare And Swap)算法、volatile变量与native方法来保证原子操作,从而避免synchronized的高开销,执行效率大为提升。
八、多线程中的CAS算法:
1、CAS算法的理解:
(1)、CAS(Compare And Swap),即比较再替换。JDK5之前Java语言是靠synchronized关键字保证同步的,这是一种独占锁,也是悲观锁。JDK5增加了并发包java.util.concurrent.*,该类下采用CAS算法实现,CAS算法是一种区别于synchronouse同步锁的乐观锁。
(2)、CAS操作包含三个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,才将内存值V修改为B并返回true,否则什么都不做并返回false(需要volatile变量配合)
2、CAS算法存在的问题:
(1)、CPU开销较大
(2)、不能保证代码块的原子性
(3)、ABA问题(最大问题)
ABA问题,即并发环境下,并发1在修改数据时,虽然还是A,但已经不是初始条件的A了,中间发生了A变B,B又变A的变化,此A已经非彼A,数据却成功修改,可能导致错误。
搜索
复制
8、ThreadPoolTaskExecutor线程并发的更多相关文章
- Java线程并发:知识点
Java线程并发:知识点 发布:一个对象是使它能够被当前范围之外的代码所引用: 常见形式:将对象的的引用存储到公共静态域:非私有方法中返回引用:发布内部类实例,包含引用. 逃逸:在对象尚未准备 ...
- Java多线程与并发库高级应用-java5线程并发库
java5 中的线程并发库 主要在java.util.concurrent包中 还有 java.util.concurrent.atomic子包和java.util.concurrent.lock子包 ...
- Spring如何处理线程并发
Spring如何处理线程并发 我们知道Spring通过各种DAO模板类降低了开发者使用各种数据持久技术的难度.这些模板类都是线程安全的,也就是说,多个DAO可以复用同一个模板实例而不会发生冲突.我 ...
- 线程高级应用-心得8-java5线程并发库中同步集合Collections工具类的应用及案例分析
1. HashSet与HashMap的联系与区别? 区别:前者是单列后者是双列,就是hashmap有键有值,hashset只有键: 联系:HashSet的底层就是HashMap,可以参考HashSe ...
- 线程高级应用-心得5-java5线程并发库中Lock和Condition实现线程同步通讯
1.Lock相关知识介绍 好比我同时种了几块地的麦子,然后就等待收割.收割时,则是哪块先熟了,先收割哪块. 下面举一个面试题的例子来引出Lock缓存读写锁的案例,一个load()和get()方法返回值 ...
- 线程高级应用-心得4-java5线程并发库介绍,及新技术案例分析
1. java5线程并发库新知识介绍 2.线程并发库案例分析 package com.itcast.family; import java.util.concurrent.ExecutorServi ...
- CoreJava_线程并发(堵塞队列):在某个目录下搜索含有某keyword的文件
Java多线程编程是很考验一个程序猿水平的. 传统的WEB程序中.由于框架提供了太多的健壮性.并发性.可靠性的支持,所以我们都是将全部的注意力放到了业务实现上.我们不过依照业务逻辑的要求.不停的积累自 ...
- 14.6.6 Configuring Thread Concurrency for InnoDB 配置线程并发
14.6.6 Configuring Thread Concurrency for InnoDB 配置线程并发 InnoDB 使用操作系统线程来处理请求(用户事务) 事务可能执行很多次在它们提交或者回 ...
- java--加强之 Java5的线程并发库
转载请申明出处:http://blog.csdn.net/xmxkf/article/details/9945499 01. 传统线程技术回顾 创建线程的两种传统方式: 1.在Thread子类覆盖的r ...
- 面试心得随谈&线程并发的总结
---恢复内容开始--- 线程同步有两种实现方式: 基于用户模式实现和用内核对象实现.前者偏于轻量级,性能也更好,但是只能用于同一进程间的线程同步,后者重量级,性能消耗更大,跨进程. 研读了一下win ...
随机推荐
- 微软出品自动化神器Playwright(Playwright+Java)系列(四) 之 浏览器操作
写在前面 今天是国庆节的最后一天,明天又要上班了,真的是感觉好像才开始放假一样,还是因为失恋没缓过来吗? 我的国庆七天 第1天,当了近半天的司机,陪家人去各大超市去购物,下午在家躺····· 第2-5 ...
- 一个C#开发者学习SpringCloud搭建微服务的心路历程
前言 Spring Cloud很火,很多文章都有介绍如何使用,但对于我这种初学者,我需要从创建项目开始学起,所以这些文章对于我的启蒙,帮助不大,所以只好自己写一篇文章,用于备忘. SpringClou ...
- 代码随想录第二天| 977.有序数组的平方 ,209.长度最小的子数组 ,59.螺旋矩阵II
2022/09/22 第二天 第一题 这题我就直接平方后排序了,很无脑但很快乐啊(官方题解是双指针 第二题 滑动窗口的问题,本来我也是直接暴力求解发现在leetCode上超时,看了官方题解,也是第一次 ...
- TF-GNN踩坑记录(一)
引言 Batch size作为一个在训练中经常被使用的参数,在图神经网络的训练中也是必不可少,但是在TF-GNN中要求使用 merge_batch_to_components() 把batch之后的图 ...
- Docker | dockerfile构建centos镜像,以及CMD和ENTRYPOINT的区别
构建自己的centos镜像 docker pull centos下载下来的镜像都是基础版本,缺少很多常用的命令功能,比如:ll.vim等等, 下面介绍制作一个功能较全的自己的centos镜像. 步骤 ...
- Vue学习之--------深入理解Vuex、原理详解、实战应用(2022/9/1)
@ 目录 1.概念 2.何时使用? 3.搭建vuex环境 3.1 创建文件:src/store/index.js 3.2 在main.js中创建vm时传入store配置项 4.基本使用 4.1.初始化 ...
- 驱动开发:内核枚举进程与线程ObCall回调
在笔者上一篇文章<驱动开发:内核枚举Registry注册表回调>中我们通过特征码定位实现了对注册表回调的枚举,本篇文章LyShark将教大家如何枚举系统中的ProcessObCall进程回 ...
- Java多线程(7):JUC(上)
您好,我是湘王,这是我的博客园,欢迎您来,欢迎您再来- 前面把线程相关的生命周期.关键字.线程池(ThreadPool).ThreadLocal.CAS.锁和AQS都讲完了,现在就剩下怎么来用多线程了 ...
- ISCTF2022WP
ISCTF2022改名叫套CTF吧(bushi),博主菜鸡一个,套题太多,挑一些题写下wp,勿喷. MISC 可爱的emoji 下载下来是个加密压缩包,根据hint掩码爆破密码 得到密码:KEYI ...
- python中展示json数据不换行(手动换行)
https://blog.csdn.net/chichu261/article/details/82784904 Settings ->keymap -> 在搜索框输入 wraps -&g ...