Machine Learning系列--维特比算法
维特比算法(Viterbi algorithm)是在一个用途非常广的算法,本科学通信的时候已经听过这个算法,最近在看 HMM(Hidden Markov model) 的时候也看到了这个算法。于是决定研究一下这个算法的原理及其具体实现,如果了解动态规划的同学应该很容易了解维特比算法,因为维特比算法的核心就是动态规划。
对于 HMM 而言,其中一个重要的任务就是要找出最有可能产生其观测序列的隐含序列。一般来说,HMM问题可由下面五个元素描述:
- 观测序列(observations):实际观测到的现象序列
- 隐含状态(states):所有的可能的隐含状态
- 初始概率(start_probability):每个隐含状态的初始概率
- 转移概率(transition_probability):从一个隐含状态转移到另一个隐含状态的概率
- 发射概率(emission_probability):某种隐含状态产生某种观测现象的概率
下面以维基百科上的具体例子来说明:
想象一个乡村诊所。村民有着非常理想化的特性,要么健康要么发烧。他们只有问诊所的医生的才能知道是否发烧。 聪明的医生通过询问病人的感觉诊断他们是否发烧。村民只回答他们感觉正常、头晕或冷。
假设一个病人每天来到诊所并告诉医生他的感觉。医生相信病人的健康状况如同一个离散马尔可夫链。病人的状态有两种“健康”和“发烧”,但医生不能直接观察到,这意味着状态对他是“隐含”的。每天病人会告诉医生自己有以下几种由他的健康状态决定的感觉的一种:正常、冷或头晕。这些是观察结果。 整个系统为一个隐马尔可夫模型(HMM)。
医生知道村民的总体健康状况,还知道发烧和没发烧的病人通常会抱怨什么症状。 换句话说,医生知道隐马尔可夫模型的参数。则这些上面提到的五个元素表示如下:
states = ('Healthy', 'Fever')
observations = ('normal', 'cold', 'dizzy')
start_probability = {'Healthy': 0.6, 'Fever': 0.4}
transition_probability = {
'Healthy' : {'Healthy': 0.7, 'Fever': 0.3},
'Fever' : {'Healthy': 0.4, 'Fever': 0.6},
}
emission_probability = {
'Healthy' : {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},
'Fever' : {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6},
}
其对应的状态转移图如下所示:

现在的问题是假设病人连续三天看医生,医生发现第一天他感觉正常,第二天感觉冷,第三天感觉头晕。 于是医生产生了一个问题:怎样的健康状态序列最能够解释这些观察结果。维特比算法解答了这个问题。
首先直观地看这个问题,在HMM中,一个观测现象后面的对应的各个状态都有一个概率值,我们只需要选择概率值最大的那个状态即可,但是这个概率值是跟前面一个状态有关的(马尔科夫假设),因此不能独立考虑每个观测现象。
为了从时间复杂度方面进行比较,现在将问题一般化:假设观测序列的长度为 m,隐含状态个数为 n。则有下面的隐含状态转移图(下图为了便于表示,将只画出n = 3 的图)。

假如采用穷举法,穷举出所有可能的状态序列再比较他们的概率值,则时间复杂度是$O(n^m)$, 显然这样的时间复杂度是无法接受的,而通过维特比算法能把时间复杂度降到$O(m*n^2)$。
从动态规划的问题去考虑这个问题,根据上图的定义,记last_state为上一个观测现象对应的各个隐含状态的概率,curr_state为现在的观测现象对应的各个隐含状态的概率。则求解curr_state实际上只依赖于last_state。而他们的依赖关系可通过下面的python代码表示出来:
for cs in states:
curr_state[cs] = max(last_state[ls] *
transition_probability[ls][cs] *
emission_probability[cs][observation]
for ls in states)
计算过程利用了转移概率transition_probability和发射概率emission_probability,选出那个最有可能产生当前状态cs的上一状态ls。
除了上面的计算,同时要为每个隐含状态维护一个路径path,path[s]表示到达状态s前的最优状态序列。通过前面的计算选出那个最有可能产生当前状态cs的上一状态ls后,往path[cs]中插入ls。则依照这种方法遍历完所有的观测序列后,只需要选择curr_state中概率值最大的那个state作为最终的隐含状态,同时从path中取出path[state]作为该最终隐含状态前面的状态序列。
从上面的分析可知,观测序列只需要遍历一遍,时间复杂度为$O(m)$,而每次要计算当前各个状态最可能的前一状态,时间复杂度为$O(n^2)$,因此总体的时间复杂度为$O(m*n^2)$.
假如在NLP中应用HMM,则将词序列看做是观测到的现象,而词性、标签等信息看做是隐含状态,那么就可以通过维特比算法求解其隐含状态序列,而这也是HMM在分词,词性标注,命名实体识别中的应用。其关键往往是找出上面提到的初始概率(start_probability)、转移概率(transition_probability)、发射概率(emission_probability)。
而在通信领域中,假如将收到的编码信息看作是观测序列,对应的解码信息为隐含状态,那么通过维特比算法也能够找出概率最大的解码信息。
需要注意的是维特比算法适用于多步骤多选择的最优问题,类似于下面的网络,《数学之美》中将其叫做“篱笆网络(Lattice)”。每一步都有多个选择,并且保留了前面一步各个选择的最优解,通过回溯的方法找到最优选择路径。
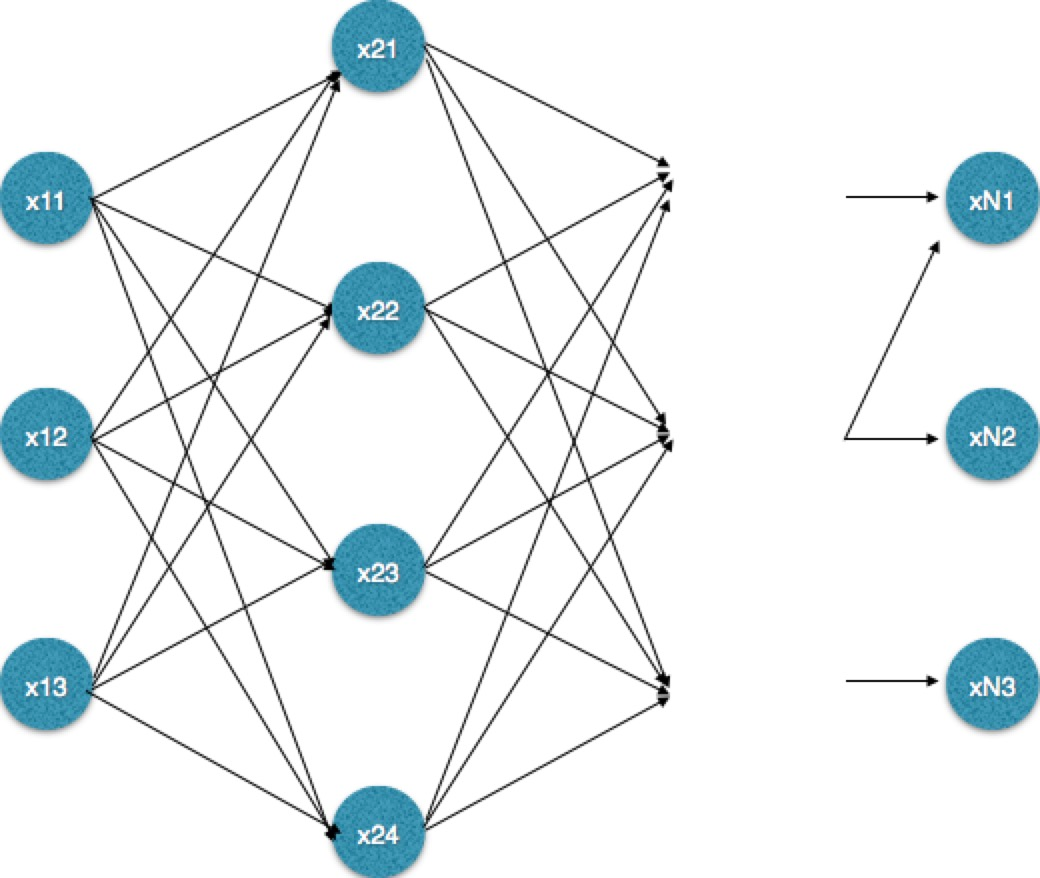
这里要强调的是viterbi算法可以用于解决HMM问题,但是也可以用于解决其他符合上面描述的问题。
转自博文:http://wulc.me/2017/03/02/维特比算法/
Machine Learning系列--维特比算法的更多相关文章
- Machine Learning读书会,面试&算法讲座,算法公开课,创业活动,算法班集锦
Machine Learning读书会,面试&算法讲座,算法公开课,创业活动,算法班集锦 近期活动: 2014年9月3日,第8次西安面试&算法讲座视频 + PPT 的下载地址:http ...
- Machine Learning系列--CRF条件随机场总结
根据<统计学习方法>一书中的描述,条件随机场(conditional random field, CRF)是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出 ...
- [Machine Learning] 浅谈LR算法的Cost Function
了解LR的同学们都知道,LR采用了最小化交叉熵或者最大化似然估计函数来作为Cost Function,那有个很有意思的问题来了,为什么我们不用更加简单熟悉的最小化平方误差函数(MSE)呢? 我个人理解 ...
- Machine Learning系列--隐马尔可夫模型的三大问题及求解方法
本文主要介绍隐马尔可夫模型以及该模型中的三大问题的解决方法. 隐马尔可夫模型的是处理序列问题的统计学模型,描述的过程为:由隐马尔科夫链随机生成不可观测的状态随机序列,然后各个状态分别生成一个观测,从而 ...
- Machine Learning系列--EM算法理解与推导
EM算法,全称Expectation Maximization Algorithm,译作最大期望化算法或期望最大算法,是机器学习十大算法之一,吴军博士在<数学之美>书中称其为“上帝视角”算 ...
- Machine Learning系列--L0、L1、L2范数
今天我们聊聊机器学习中出现的非常频繁的问题:过拟合与规则化.我们先简单的来理解下常用的L0.L1.L2和核范数规则化.最后聊下规则化项参数的选择问题.这里因为篇幅比较庞大,为了不吓到大家,我将这个五个 ...
- Machine Learning in Action-chapter2-k近邻算法
一.numpy()函数 1.shape[]读取矩阵的长度 例: import numpy as np x = np.array([[1,2],[2,3],[3,4]]) print x.shape / ...
- Machine Learning系列--TF-IDF模型的概率解释
信息检索概述 信息检索是当前应用十分广泛的一种技术,论文检索.搜索引擎都属于信息检索的范畴.通常,人们把信息检索问题抽象为:在文档集合D上,对于由关键词w[1] ... w[k]组成的查询串q,返回一 ...
- Machine Learning系列--归一化方法总结
一.数据的标准化(normalization)和归一化 数据的标准化(normalization)是将数据按比例缩放,使之落入一个小的特定区间.在某些比较和评价的指标处理中经常会用到,去除数据的单位限 ...
随机推荐
- 【bzoj5123】[Lydsy12月赛]线段树的匹配 树形dp+记忆化搜索
题目描述 求一棵 $[1,n]$ 的线段树的最大匹配数目与方案数. $n\le 10^{18}$ 题解 树形dp+记忆化搜索 设 $f[l][r]$ 表示根节点为 $[l,r]$ 的线段树,匹配选择根 ...
- BZOJ5071 小A的数字
设f[i]为选择i对i-1和i+1所带来的贡献.则有f[i-1]+f[i+1]+a[i]-2f[i]=b[i],特殊地,f[2]+a[1]=b[1],f[n-1]+a[n]-2f[n]=b[n].可以 ...
- [HNOI2014]江南乐 博弈论
题面 题面 题解 首先我们知道一个关于除法的重要性质:对于一个固定的\(i\),表达式\(\frac{i}{m}\)的取值只有根号个. 因此我们考虑如何优化SG函数的求解. 观察到在取值相同的同一段中 ...
- Elasticsearch在windows上安装好了之后怎么使用?
windows 10上安装Elasticsearch过程记录 一.安装和配置Java JDK1.下载:http://download.oracle.com/otn ... 4.exe2.设置环境变量: ...
- 【BZOJ2437】【NOI2011】兔兔与蛋蛋(博弈论,二分图匹配)
[BZOJ2437][NOI2011]兔兔与蛋蛋(博弈论,二分图匹配) 题面 BZOJ 题解 考虑一下暴力吧. 对于每个状态,无非就是要考虑它是否是必胜状态 这个直接用\(dfs\)爆搜即可. 这样子 ...
- 跨域通信的解决方案JSONP
在web2.0时代,熟练的使用ajax是每个前端攻城师必备的技能.然而由于受到浏览器的限制,ajax不允许跨域通信. JSONP就是就是目前主流的实现跨域通信的解决方案. 虽然在在jquery中,我们 ...
- Linux必知必会——od命令
1.功能 od命令用于将指定文件内容以八进制.十进制.十六进制.浮点格式或ASCII编码字符方式显示,通常用于显示或查看文件中不能直接显示在终端的字符.od命令系统默认的显示方式是八进制,名称源于Oc ...
- AtCoder Regular Contest 086 E - Smuggling Marbles(树形迭屁)
好强的题. 方案不好算,改成算概率,注意因为是模意义下的概率所以直接乘法逆元就好不要傻傻地开double. 设$f[i][d][0]$为第i个节点离d层的球球走到第i个点时第i个点没有球的概率, $f ...
- 解题:由乃OI 2018 五彩斑斓的世界
题面 写在前面的扯淡: 分块的总体学习告一段落,这算是分块集中学习的最后一题么:以后当然也可能会写,就是零零散散的题了=.= 在洛谷上搜ynoi发现好像只有这道题和 由乃OI 2018 未来日记 是分 ...
- LOJ #6037.「雅礼集训 2017 Day4」猜数列 状压dp
这个题的搜索可以打到48分…… #include <cstdio> #include <cstring> #include <algorithm> ; bool m ...