【Python3爬虫】常见反爬虫措施及解决办法(三)
上一篇博客的末尾说到全网代理IP的端口号是经过加密混淆的,而这一篇博客就将告诉你如何破解!如果觉得有用的话,不妨点个推荐哦~
一、全网代理IP的JS混淆
首先进入全网代理IP,打开开发者工具,点击查看端口号,看起来貌似没有什么问题:

如果你已经爬取过这个网站的代理,你就会知道事情并非这么简单。如果没爬过呢?也很简单,点击鼠标右键然后查看网页源代码,搜索”port“,可以找到如下内容:

很明显这不是网页上显示的端口号了,那我们要怎么才能得到真正的端口号呢?
解决办法:
首先需要找到一个JS文件:http://www.goubanjia.com/theme/goubanjia/javascript/pde.js?v=1.0,点开后可以看到如下内容:

这么复杂的JS代码看得人头都大了,不过我们发现这个JS代码是一个eval函数,那我们能不能把它解码一下呢?这时候你需要一个工具--脚本之家在线工具,把这些JS代码复制进去:

然后点击解码:
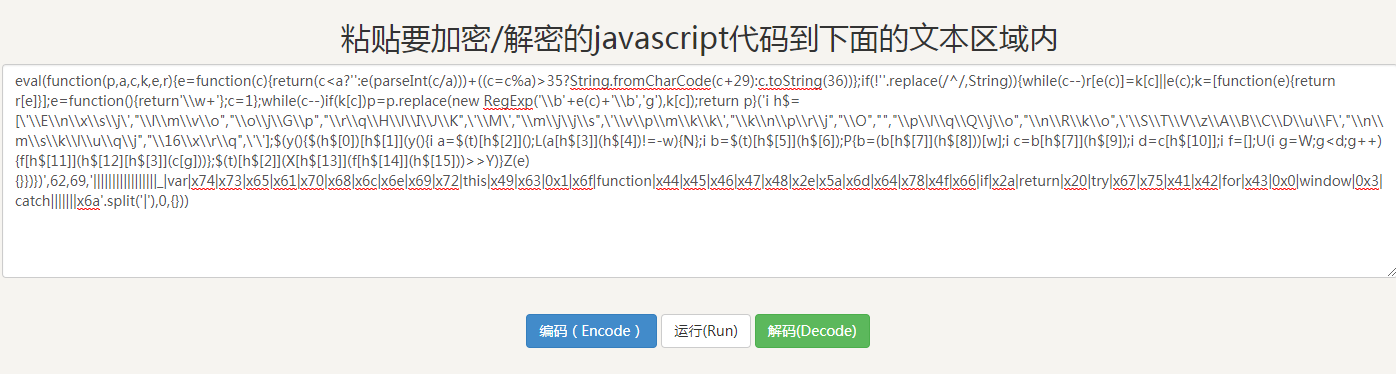
还是一个eval函数,所以再次解码:

到这一步,已经比最开始的代码简洁多了,但是还易读性还是很差,所以我们需要先格式化一下:
var _$ = [
"\x2e\x70\x6f\x72\x74",
"\x65\x61\x63\x68",
"\x68\x74\x6d\x6c",
"\x69\x6e\x64\x65\x78\x4f\x66",
"\x2a",
"\x61\x74\x74\x72",
"\x63\x6c\x61\x73\x73",
"\x73\x70\x6c\x69\x74",
"\x20",
"",
"\x6c\x65\x6e\x67\x74\x68",
"\x70\x75\x73\x68",
"\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a",
"\x70\x61\x72\x73\x65\x49\x6e\x74",
"\x6a\x6f\x69\x6e",
""
];
$(function() {
$(_$[0])[_$[1]](function() {
var a = $(this)[_$[2]]();
if (a[_$[3]](_$[4]) != -0x1) {
return;
}
var b = $(this)[_$[5]](_$[6]);
try {
b = b[_$[7]](_$[8])[0x1];
var c = b[_$[7]](_$[9]);
var d = c[_$[10]];
var f = [];
for (var g = 0x0; g < d; g++) {
f[_$[11]](_$[12][_$[3]](c[g]));
}
$(this)[_$[2]](window[_$[13]](f[_$[14]](_$[15])) >> 0x3);
} catch (e) {}
});
});
可以看到有一个列表和一个函数,而这个函数应该就是混淆的函数了,但是这列表里的数据都是十六进制的,还需要解码一下(这一步可以用Python来做):
_ = ["\x2e\x70\x6f\x72\x74", "\x65\x61\x63\x68", "\x68\x74\x6d\x6c", "\x69\x6e\x64\x65\x78\x4f\x66", "\x2a",
"\x61\x74\x74\x72", "\x63\x6c\x61\x73\x73", "\x73\x70\x6c\x69\x74", "\x20", "", "\x6c\x65\x6e\x67\x74\x68",
"\x70\x75\x73\x68", "\x41\x42\x43\x44\x45\x46\x47\x48\x49\x5a", "\x70\x61\x72\x73\x65\x49\x6e\x74",
"\x6a\x6f\x69\x6e", ""
]
_ = [i.encode('utf-8').decode('utf-8') for i in _]
print(_)
# ['.port', 'each', 'html', 'indexOf', '*', 'attr', 'class', 'split', ' ', '', 'length', 'push', 'ABCDEFGHIZ', 'parseInt', 'join', '']
然后把这个列表里的元素添加到上面的JS函数中,可以得到如下结果:
$(function() {
$(".port")["each"](function() {
var a = $(this)["html"]();
if (a["indexOf"]("*") != -0x1) {
return;
}
var b = $(this)["attr"]("class");
try {
b = b["split"](" ")[0x1];
var c = b["split"]("");
var d = c["length"];
var f = [];
for (var g = 0x0; g < d; g++) {
f["push"]("ABCDEFGHIZ"["indexOf"](c[g]));
}
$(this)["html"](window["parseInt"](f["join"]("")) >> 0x3);
} catch (e) {}
});
});
可以看到这段JS代码就是先找到每个端口节点,然后把端口的class值提取出来,再进行拆分字符串,然后获取每个字母在”ABCDEFGHIZ“中的下标值,并把这些值拼接成字符串,再转为整型数据,最后把这个整型数据向右移3位。比如”GEA“对应的下标组成的字符串是”640“,转为整型数据后向右移3位的结果就是80,也就是真实的端口值了。最后附上用Python解密端口号的代码:
et = etree.HTML(html)
port_list = et.xpath('//*[contains(@class,"port")]/@class')
for port in port_list:
port = port.split(' ')[1]
num = ""
for i in port:
num += str("ABCDEFGHIZ".index(i))
print(int(num) >> 3)
二、用图片代替文字
之前就有人评论说有的网站使用图片代替文字以实现反爬虫,然后我这次就找到了一个网站--新蛋网,随意点击一个商品查看一下:
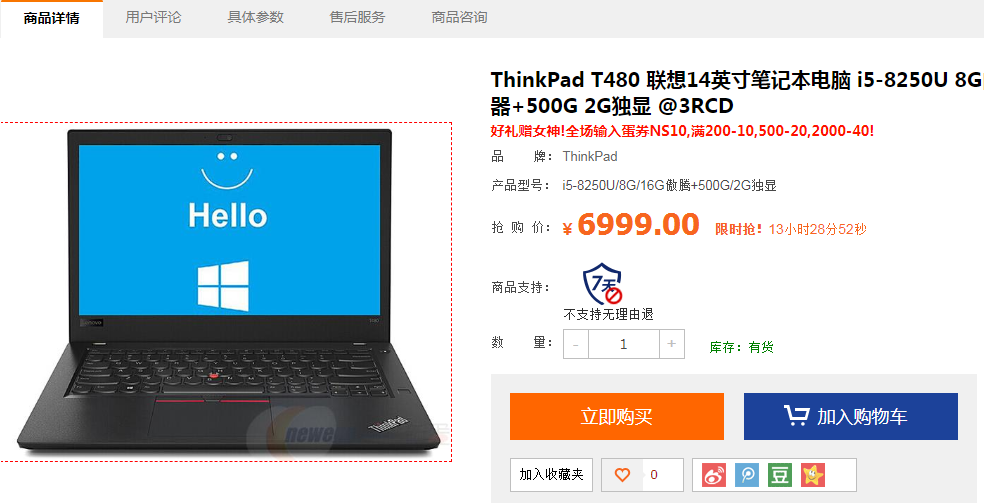
打开开发者工具,然后点击查看价格,想不到价格居然是通过图片来显示的:
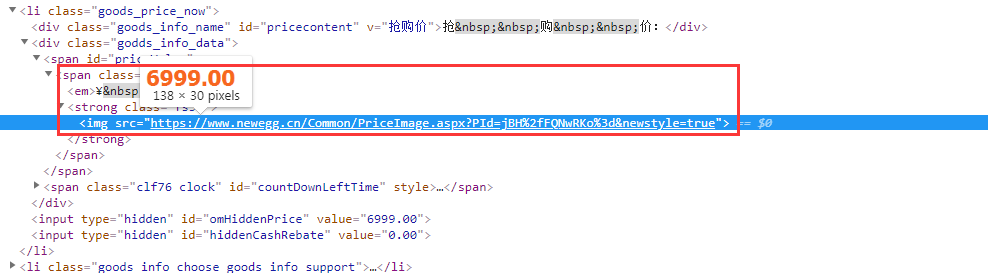
解决办法:
我找到两个可以得到价格的办法,一个简单的,一个难一点的。简单的方法是用正则表达式,因为在源码中的其他地方是包含商品的基本信息的,比如名称和价格,所以我们可以使用正则表达式进行匹配,代码如下:
import re
import requests url = "https://www.newegg.cn/Product/A36-125-E5L.htm?neg_sp=Home-_-A36-125-E5L-_-CountdownV1"
res = requests.get(url)
result = re.findall("name:'(.+?)', price:'(.+?)'", res.text)
print(result)
难一点的方法是把图片下载到本地之后进行识别,由于这个图片的清晰度很高,也没有扭曲或者加入干扰线什么的,所以可以直接使用OCR进行识别。但是用这种方法的话需要安装好Tesseract-OCR,这个工具的安装过程还是比较麻烦的。用这种方法破解的代码如下:
import requests
import pytesseract
from PIL import Image
from lxml import etree url = "https://www.newegg.cn/Product/A36-125-E5L.htm?neg_sp=Home-_-A36-125-E5L-_-CountdownV1"
res = requests.get(url)
et = etree.HTML(res.text)
img_url = et.xpath('//*[@id="priceValue"]/span/strong/img/@src')[0]
with open('price.png','wb') as f:
f.write(requests.get(img_url).content)
pytesseract.pytesseract.tesseract_cmd = 'E:/Python/Tesseract-OCR/tesseract.exe'
text = pytesseract.image_to_string(Image.open('price.png'))
print(text)
# 6999.00
【Python3爬虫】常见反爬虫措施及解决办法(三)的更多相关文章
- Python爬虫与反爬虫(7)
[Python基础知识]Python爬虫与反爬虫(7) 很久没有补爬虫了,相信在白蚁二周年庆的活动大厅比赛中遇到了关于反爬虫的问题吧 这节我会做个基本分享. 从功能上来讲,爬虫一般分为数据采集,处理, ...
- Python爬虫从入门到放弃(二十二)之 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- 【Python】爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- Python之爬虫(二十四) 爬虫与反爬虫大战
爬虫与发爬虫的厮杀,一方为了拿到数据,一方为了防止爬虫拿到数据,谁是最后的赢家? 重新理解爬虫中的一些概念 爬虫:自动获取网站数据的程序反爬虫:使用技术手段防止爬虫程序爬取数据误伤:反爬虫技术将普通用 ...
- python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性)
python爬虫之反爬虫(随机user-agent,获取代理ip,检测代理ip可用性) 目录 随机User-Agent 获取代理ip 检测代理ip可用性 随机User-Agent fake_usera ...
- Python爬虫入门教程 65-100 爬虫与反爬虫的修罗场,点评网站,字体反爬之三
爬虫与反爬虫的修罗场 哪种平台最吸引爬虫爱好者,当然是社区类的,那里容易产生原生态,高质量的数据啊, 你看微博,知乎,豆瓣爬的不亦乐乎. 评论也是产生内容的好地方 生活类点评网站 旅游类点评网站 音乐 ...
- C#爬虫与反爬虫--字体加密篇
爬虫和反爬虫是一条很长的路,遇到过js加密,flash加密.重点信息生成图片.css图片定位.请求头.....等手段:今天我们来聊一聊字体: 那是一个偶然我遇到了这个网站,把价格信息全加密了:浏览器展 ...
- C#不用union,而是有更好的方式实现 .net自定义错误页面实现 .net自定义错误页面实现升级篇 .net捕捉全局未处理异常的3种方式 一款很不错的FLASH时种插件 关于c#中委托使用小结 WEB网站常见受攻击方式及解决办法 判断URL是否存在 提升高并发量服务器性能解决思路
C#不用union,而是有更好的方式实现 用过C/C++的人都知道有个union,特别好用,似乎char数组到short,int,float等的转换无所不能,也确实是能,并且用起来十分方便.那C# ...
- 【Python3爬虫】常见反爬虫措施及解决办法(二)
这一篇博客,还是接着说那些常见的反爬虫措施以及我们的解决办法.同样的,如果对你有帮助的话,麻烦点一下推荐啦. 一.防盗链 这次我遇到的防盗链,除了前面说的Referer防盗链,还有Cookie防盗链和 ...
- 【Python3爬虫】常见反爬虫措施及解决办法(一)
这一篇博客,是关于反反爬虫的,我会分享一些我遇到的反爬虫的措施,并且会分享我自己的解决办法.如果能对你有什么帮助的话,麻烦点一下推荐啦. 一.UserAgent UserAgent中文名为用户代理,它 ...
随机推荐
- C++的find函数使用小技巧
一个小问题:原始字符串如CRYPT,FUNCTION,我要确定里面是否存在CRYPT,于是调用C++的find()函数,结果判断是不存在,怎么回事? 我的判断代码if(strUseFlagsTmp.F ...
- java算法之超级丑数
问题描述: 写一个程序来找第 n 个超级丑数. 超级丑数的定义是正整数并且所有的质数因子都在所给定的一个大小为 k 的质数集合内. 比如给你 4 个质数的集合 [2, 7, 13, 19], 那么 [ ...
- js基础进阶--编码实用技巧(二)
我的个人博客:http://www.xiaolongwu.cn 接上篇文章 js编码的实用技巧(一) 5.合理利用||运算符 使用||可以作为参数之外的默认值,当第一个参数返回值为false时,那么第 ...
- 对于 Netty ByteBuf 的零拷贝(Zero Copy) 的理解
此文章已同步发布在我的 segmentfault 专栏. 根据 Wiki 对 Zero-copy 的定义: "Zero-copy" describes computer opera ...
- Myeclipse10破解版安装包
下载地址;http://pan.baidu.com/s/1pLka0un
- MYSQL复制原理及其流程
Mysql内建的复制功能是构建大型,高性能应用程序的基础.将Mysql的数据分布到多个系统上去,这种分布的机制,是通过将Mysql的某一台主机的数据复制到其他主机(slave)上,并重新执行一遍来实现 ...
- InnoDB页压缩技术
Ⅰ.想起一个报错 1.1 创建表报错 (root@localhost) [(none)]> create tablespace ger_space add datafile 'ger_space ...
- toFixed()一不小心踩了一个坑
toFixed,多么简单的一个函数,昨天突发奇想做两道算法题练练手.结果,踩到了一个从未遇到的坑! \n 简单来讲是要对输入的很多组数据,自己写一个函数做个处理,把每次函数处理的结果要相加求和.最后输 ...
- Java开源生鲜电商平台-监控模块的设计与架构(源码可下载)
Java开源生鲜电商平台-监控模块的设计与架构(源码可下载) 说明:Java开源生鲜电商平台-监控模块的设计与架构,我们谈到监控,一般设计到两个方面的内容: 1. 服务器本身的监控.(比如:linux ...
- Python startswith()方法
描述 Python startswith() 方法用于检查字符串是否是以指定子字符串开头,如果是则返回 True,否则返回 False.如果参数 beg 和 end 指定值,则在指定范围内检查. 语法 ...