[Inside HotSpot] C1编译器工作流程及中间表示
1. C1编译器线程
C1编译器(aka Client Compiler)的代码位于hotspot\share\c1。C1编译线程(C1 CompilerThread)会阻塞在任务队列,当发现队列有编译任务即可CompileTask的时候,线程唤醒然后调用CompilerBroker,CompilerBroker再进一步选择合适编译器,以此进入JIT编译器的世界。

有一个取巧的办法可以得到详细的工作流程:C1编译器会对每个阶段做性能计时,这个计时取名就是阶段名字,所以我们可以通过计时看看详细步骤:
//hotspot\share\c1\c1_Compilation.cpp
typedef enum {
_t_compile, // C1编译
_t_setup, // 1)设置C1编译环境
_t_buildIR, // 2)构造HIR
_t_hir_parse, // 从字节码生成HIR
_t_gvn, // GVN优化
_t_optimize_blocks, // 基本块优化
_t_optimize_null_checks, // null检查优化消除
_t_rangeCheckElimination, // 数组范围检查消除
_t_emit_lir, // 3)构造LIR
_t_linearScan, // 线性扫描寄存器分配
_t_lirGeneration, // 生成LIR
_t_codeemit, // 机器代码生成
_t_codeinstall, // 替换解释执行的代码为机器代码(nmethod)
max_phase_timers
} TimerName;
这里我们主要关心第二三阶段。它们位于c1/compilation模块。从CompilerBroker到该阶段的调用栈如下:
CompileBroker::invoke_compiler_on_method()
-> Compiler::compile_method()
-> Compilation::Compilation()
-> Compilation::compile_method()
-> Compilation::compile_java_method()
在compile_java_method()方法中完成了C1编译最主要的流程:
int Compilation::compile_java_method() {
...
// 构造HIR
{
PhaseTraceTime timeit(_t_buildIR);
build_hir();
}
// 构造LIR
{
PhaseTraceTime timeit(_t_emit_lir);
_frame_map = new FrameMap(method(), hir()->number_of_locks(), MAX2(4, hir()->max_stack()));
emit_lir();
}
// 生成机器代码
{
PhaseTraceTime timeit(_t_codeemit);
return emit_code_body();
}
}
二三阶段将Java字节码转换为各种形式的中间表示(HIR,LIR),然后在其上做代码优化和机器代码生成,这个机器代码就是C1 JIT产出的东西。可以看出,沟通Java字节码和JIT产出的机器代码之前的桥梁就是中间表示,C1的大部分工作也是针对中间表示做各种变换,要明白C1的工作得先说说什么是中间表示。
2. 中间表示简介
C1编译器(Client Compiler)将字节码转化为SSA-based HIR(Single Static Assignment based High-Level Intermediate Representation)。HIR即高级中间表示,我们用Java写代码,编译得到字节码。但即便是字节码对于编译器优化来说也不太理想,编译器会使用一种更适合优化的形式来表征字节码。这个更适合优化的形式就是HIR,HIR又有很多,有些是图的形式,有些是线性的形式,
HotSpot C1使用的HIR是一种基于SSA(静态单赋值形式)的图IR,它由基本块(Basic Block)构成一个控制流图结构(Control Flow Graph),基本块里面是SSA,直观表示如下:
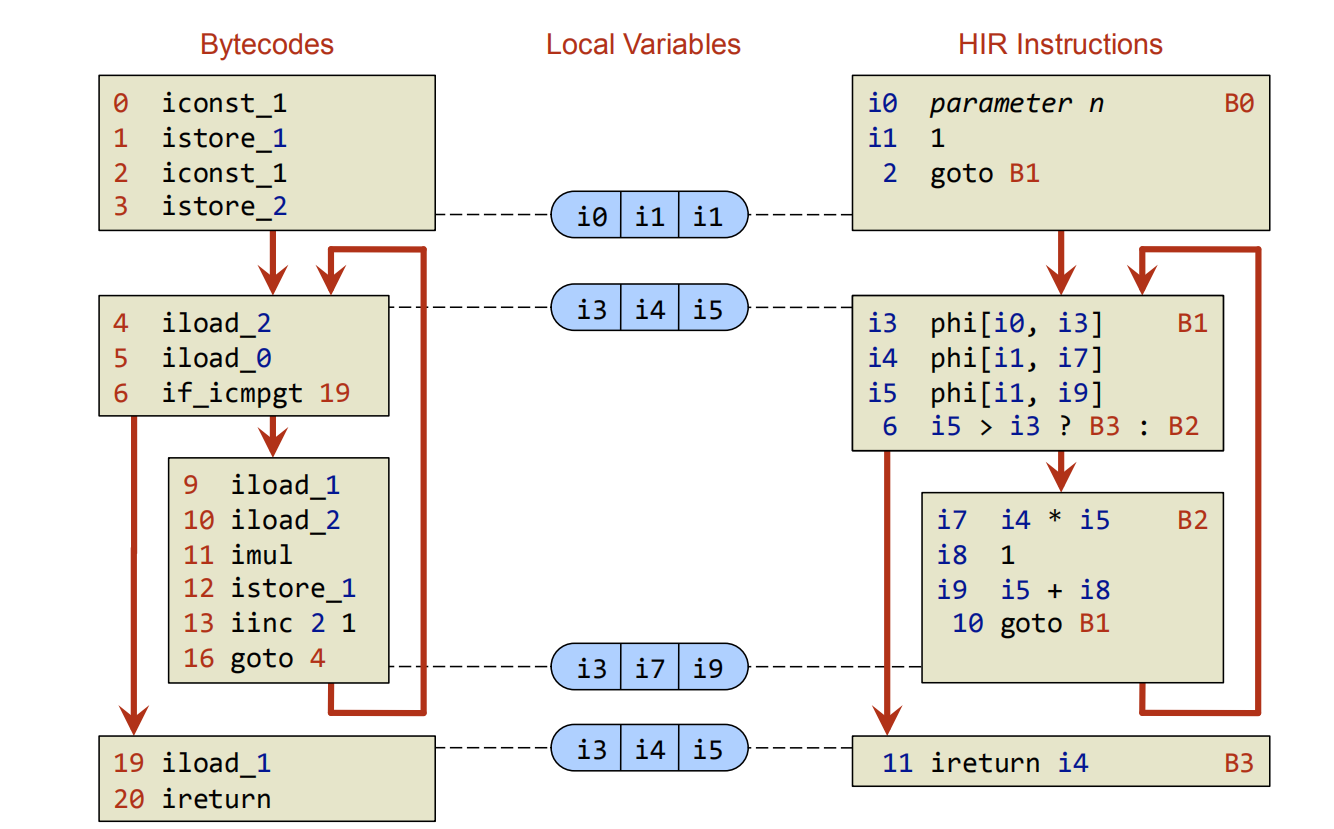
图片来源于Java HotSpot™ Client Compiler - Compiler Design Lab。左边是Java字节码,右边是字节码在C1中的HIR表示,右边的块状结构就是基本块,基本块里面即SSA。
这句话里面名词有点多,我们试着来解释一下。基本块是指单一入口,单一出口的块,块中没有跳转代码。对照图片看,4 5 6行代码是一个基本块,中间没有跳转,由4进入块,出口6的if_icmpgt转移到另一个基本块。这样的构型可以高效的做控制流分析,是编译优化常用的一种IR。CFG即控制流图,是由基本块构成的图结构。那么SSA又是什么呢?SSA表示每次变量的赋值都会创建新的且独一无二的名称,举个例子:
// 源码
int foo(){
int a = 6;
a = 8;
return a;
// SSA表示
foo:
a1 = 6
a2 = 8
return a2
这段代码里a最开始的赋值是多余的,如果用SSA表示这段代码,编译器很容易发现a1这个值在foo块中没有使用,直接优化为:
foo:
a2 = 8
return a2
SSA还有很多好处,这里只是一个小的方面,有兴趣的可以阅读编译理论方面的书籍,入门推荐《编译器设计》和《编译原理》。
回到主题,我们常说的C1编译器优化大部分都是在HIR之上完成的。当优化完成之后它会将HIR转化为LIR(Low-Level Intermediate Representation),LIR又是一种编译器内部用到的表示,这种表示消除了HIR中的PHI节点,然后使用LSRA(Linear Scan Register Allocation,线性寄存器分配算法)将虚拟寄存器映射到物理寄存器,最后再将LIR转化为CPU相关的机器码,完成JIT工作。
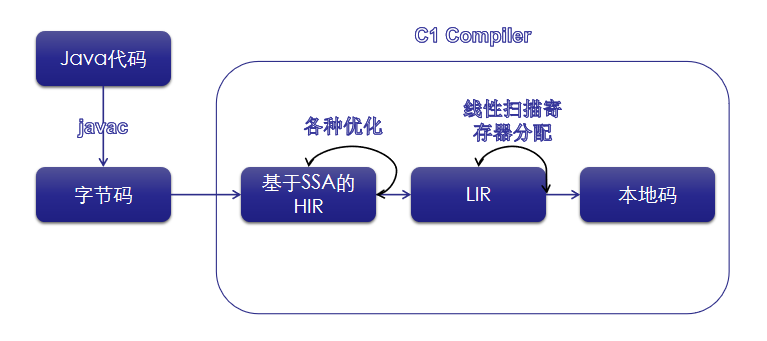
3. 构造HIR
3.1 HIR与优化
build_hir()不仅会构造出HIR,还会执行很多平台无关的代码优化。代码优化不用多讲,JVM给我们带来性能上的信心很大程度上都源于此,这是评判JIT编译器的重要指标,也是编译器后端的主要任务。
void Compilation::build_hir() {
CHECK_BAILOUT();
// 创建HIR
CompileLog* log = this->log();
if (log != NULL) {
log->begin_head("parse method='%d' ",
log->identify(_method));
log->stamp();
log->end_head();
}
{
PhaseTraceTime timeit(_t_hir_parse);
_hir = new IR(this, method(), osr_bci());
}
if (log) log->done("parse");
if (!_hir->is_valid()) {
bailout("invalid parsing");
return;
}
// 验证HIR
_hir->verify();
// 优化:条件表达式消除,基本块消除
if (UseC1Optimizations) {
NEEDS_CLEANUP
PhaseTraceTime timeit(_t_optimize_blocks);
_hir->optimize_blocks();
}
_hir->verify();
_hir->split_critical_edges();
_hir->verify();
_hir->compute_code();
// 优化:全局值编号优化
if (UseGlobalValueNumbering) {
// No resource mark here! LoopInvariantCodeMotion can allocate ValueStack objects.
PhaseTraceTime timeit(_t_gvn);
int instructions = Instruction::number_of_instructions();
GlobalValueNumbering gvn(_hir);
}
_hir->verify();
// 优化:范围检查消除
if (RangeCheckElimination) {
if (_hir->osr_entry() == NULL) {
PhaseTraceTime timeit(_t_rangeCheckElimination);
RangeCheckElimination::eliminate(_hir);
}
}
// 优化:null检查消除
if (UseC1Optimizations) {
NEEDS_CLEANUP
PhaseTraceTime timeit(_t_optimize_null_checks);
_hir->eliminate_null_checks();
}
_hir->verify();
_hir->compute_use_counts();
_hir->verify();
}
build_hir()第一阶段解析字节码生成HIR;之后会检查HIR是否有效,如果无效会发生Compilation Bailout,即编译脱离,这个词在JIT编译器中经常出现,它指的是当编译器在编译过程中遇到一些很难处理的情况,或者一些极特殊情况时会停止编译,然后回退到解释器。当对HIR的检查通过后,C1对其进行条件表达式消除,基本块消除;接着使用全局值编号(GVN,Global Value Numbering);后再消除一些数组范围检查(Range Check Elimination);最后做NULL检查消除。另外要注意的是,如果开启了分层编译(TieredCompilation),那么条件表达式消除和基本块消除只会发生在Tier1,Tier2层。
3.2 查看各阶段的HIR
如果JVM是fastdebug版,加上-XX:+PrintIR参数可以输出每一个步骤的HIR:
(我使用的完整参数是:-XX:+UnlockDiagnosticVMOptions -XX:+PrintCompilation -XX:CompileCommand=compileonly,com.github.kelthuzadx.HelloWorld::jerkSum -Xcomp -XX:TieredStopAtLevel=1 -XX:+PrintIR -XX:+PauseAtExit)
17669 28 b 1 com.github.kelthuzadx.HelloWorld::jerkSum (23 bytes)
IR after parsing
B4 [0, 0] -> B0 sux: B0
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
. 0 0 17 std entry B0
B0 (SV) [0, 4] -> B1 sux: B1 pred: B4
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
2 0 i5 0
. 4 0 6 goto B1
B1 (LHV) [4, 8] -> B3 B2 sux: B3 B2 pred: B0 B2
Locals:
1 i7 [ i4 i11]
2 i8 [ i5 i13]
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
5 0 i9 10000
. 8 0 10 if i8 >= i9 then B3 else B2
B2 (V) [11, 18] -> B1 sux: B1 pred: B1
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
13 0 i11 i7 + i8
15 0 i12 1
15 0 i13 i8 + i12
. 18 0 14 goto B1 (safepoint)
B3 (V) [21, 22] pred: B1
empty stack
inlining depth 0
__bci__use__tid____instr____________________________________
. 22 0 i15 ireturn i7
....
另外加上-XX:+PrintCFGToFile标志在字节码文件同目录下得到一个output_xx.cfg文件,里面的begin_block和end_block表示一个基本块;predecessors是当前块的前驱块;successors是后继块,这两个属性用于控制流的转移,以此构成CFG(Control Flow Graph);from_bci表示当前基本块对应的字节码起始偏移,to_bci表示对应的终止偏移;flags表示一些属性,比如该块是标准入口,还是OSR(On-Stack Replacement)入口,还是异常入口等;xhandlers表示异常处理器。
使用c1 visualizer还可以对它进行可视化:

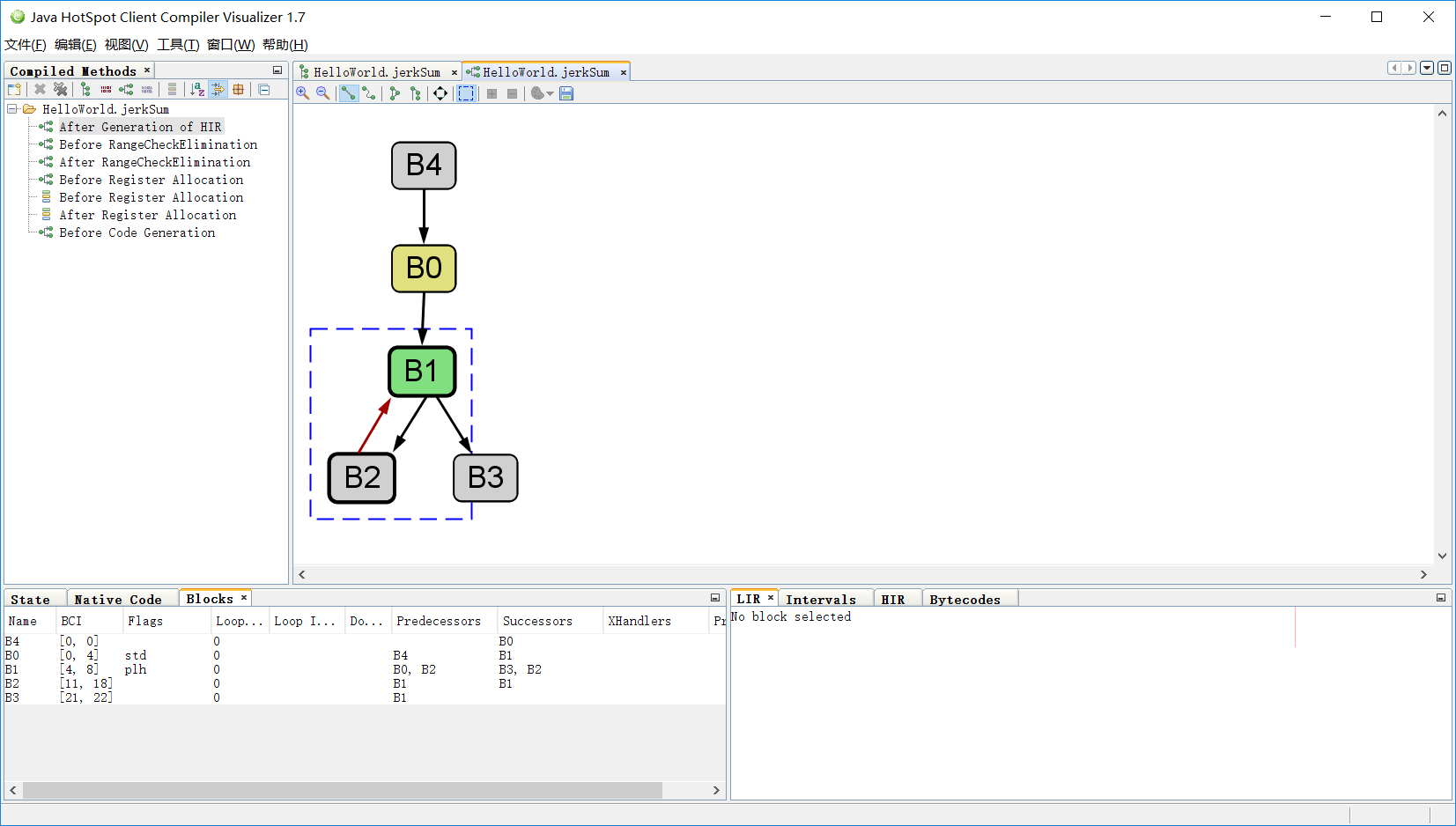
4. 构造LIR
C2使用图着色算法做寄存器分配;C1使用相对简单的线性扫描寄存器分配算法将虚拟寄存器映射到具体机器架构的物理寄存器上。更多LSRA内容请参见论文Linear Scan Register Allocation for the Java HotSpot™ Client Compiler
HotSpot对LIR也有很多虚拟机标志,都位于hotspot\share\c1\c1_global.hpp。比如-XX:+PrintLIR可以得到产出的LIR,-XX:+PrintLIRWithAssembly可以得到LIR对应的汇编表示。说了这么多,不如来实战一下。我们准备了一段Java代码:
package com.github.kelthuzadx;
public class HelloWorld {
public static int jerkSum(int start){
int total = start;
for(int i=0;i<10000;i++){
total+=i;
}
return total;
}
public static void main(String[] args) {
System.out.println(jerkSum(1024));
}
}
然后得到了对应的C1产出(-XX:+PrintLIRWithAssembly):
jerkSum:
;函数开始
0x000001999a7109a0: mov %eax,-0x9000(%rsp)
0x000001999a7109a7: push %rbp
0x000001999a7109a8: sub $0x30,%rsp
;int i = 0
0x000001999a7109ac: mov $0x0,%eax
0x000001999a7109b1: jmpq 0x000001999a7109b6
;循环开始
0x000001999a7109b6: nop
0x000001999a7109b7: nop
; total += i
0x000001999a7109b8: add %eax,%edx
; i++
0x000001999a7109ba: inc %eax
; 循环结束处插入安全点
34 safepoint [bci:18]
0x000001999a7109bc: mov 0x120(%r15),%r10
0x000001999a7109c3: test %eax,(%r10)
; i<10000
0x000001999a7109c6: cmp $0x2710,%eax
; 小于就跳到循环开始,否则结束循环
0x000001999a7109cc: jl 0x000001999a7109b8
; total放入rax,作为返回值
0x000001999a7109ce: mov %rdx,%rax
; 函数返回
0x000001999a7109d1: add $0x30,%rsp
0x000001999a7109d5: pop %rbp
0x000001999a7109d6: mov 0x120(%r15),%r10
0x000001999a7109dd: test %eax,(%r10)
0x000001999a7109e0: retq
C1在一次循环结束(B2基本块)插入了一个安全点(Safepoint),也就是说每次循环结束都有机会进行垃圾回收,这样是有意义的:试想一个死循环里面一直new Object(),如果在循环体外面插入安全点,那么GC根本得不到执行就会内存溢出,所以必须在每次循环结束时插入安全点让GC可执行,当然随之带来的还有每次循环多执行几条指令的性能惩罚,说JVM略慢不是没有理由的...然后这个例子C1没有做其他优化。
[Inside HotSpot] C1编译器工作流程及中间表示的更多相关文章
- [Inside HotSpot] C1编译器HIR的构造
1. 简介 这篇文章可以说是Christian Wimmer硕士论文Linear Scan Register Allocation for the Java HotSpot™ Client Compi ...
- [Inside HotSpot] C1编译器优化:全局值编号(GVN)
1. 值编号 我们知道C1内部使用的是一种图结构的HIR,它由基本块构成一个图,然后每个基本块里面是SSA形式的指令,关于这点如可以参考[Inside HotSpot] C1编译器工作流程及中间表示. ...
- [Inside HotSpot] C1编译器优化:条件表达式消除
1. 条件传送指令 日常编程中有很多根据某个条件对变量赋不同值这样的模式,比如: int cmov(int num) { int result = 10; if(num<10){ result ...
- [Inside HotSpot] 模板解释器
0. 简介 众所周知,hotspot默认使用解释+编译混合(-Xmixed)的方式执行代码.它首先使用模板解释器对字节码进行解释,当发现一段代码是热点的时候,就使用C1/C2 JIT进行优化编译再执行 ...
- Git 分支-利用分支进行开发的工作流程
3.4 Git 分支 - 利用分支进行开发的工作流程 利用分支进行开发的工作流程 现在我们已经学会了新建分支和合并分支,可以(或应该)用它来做点什么呢?在本节,我们会介绍一些利用分支进行开发的工作流程 ...
- 【嵌入式开发】 Bootloader 详解 ( 代码环境 | ARM 启动流程 | uboot 工作流程 | 架构设计)
作者 : 韩曙亮 博客地址 : http://blog.csdn.net/shulianghan/article/details/42462795 转载请著名出处 相关资源下载 : -- u-boo ...
- springmvc 运行原理 Spring ioc的实现原理 Mybatis工作流程 spring AOP实现原理
SpringMVC的工作原理图: SpringMVC流程 . 用户发送请求至前端控制器DispatcherServlet. . DispatcherServlet收到请求调用HandlerMappin ...
- Spark Client和Cluster两种运行模式的工作流程
1.client mode: In client mode, the driver is launched in the same process as the client that submits ...
- C1编译器的实现
总览 词法.语法分析 分析方案 词法 语法 符号表 类型系统 AST 语义检查 EIR代码生成器 MIPS代码生成器 寄存器分配 体系结构相关特性优化 使用说明 编译 运行 总览 C1语言编译器及流程 ...
随机推荐
- Git协作流程
Git 作为一个源码管理系统,不可避免涉及到多人协作. 协作必须有一个规范的流程,让大家有效地合作,使得项目井井有条地发展下去."协作流程"在英语里,叫做"workflo ...
- Javascript高级程序设计复习——第五章引用类型 【原创】
5.1 Object类型 1:创建Object实例的两种方式 ①new构造法 var obj1 = new Object(); 注意大写!不传递参数时可以省略圆括号 obj1.hehe = &quo ...
- 由一条sql语句想到的子查询优化
摘要:相信大家都使用过子查询,因为使用子查询可以一次性的完成很多逻辑上需要多个步骤才能完成的SQL操作,比较灵活,我也喜欢用,可最近因为一条包含子查询的select count(*)语句导致点开管理系 ...
- springboot中使用自定义两级缓存
工作中用到了springboot的缓存,使用起来挺方便的,直接引入redis或者ehcache这些缓存依赖包和相关缓存的starter依赖包,然后在启动类中加入@EnableCaching注解,然后在 ...
- error.go源码笔记
] { case errorCodeConnFailed: return ErrConnectionFailed(err) case errorCodeHttpServ ...
- 【贪心+背包】BZOJ1334 [Baltic2008]Elect
Description 从N个数中选出任意个数且和尽量大,但要满足去掉任意一个和就小于总和的一半.n<=300, ai<=1e5. Solution 这个条件其实就是 去掉选出的最小的一个 ...
- [Noi2015]软件包管理器 BZOJ4196
分析:水题 每次安装的时候和根节点求lca的过程中区间覆盖+区间查询 每次删除的时候查询子树中安装的数量+区间覆盖 附上代码: #include <cstdio> #include < ...
- vue enter事件无效,加入native
<Input type="password" v-model="password" placeholder="password" @k ...
- Postman----基础使用篇(没有接口文档的情况下如何着手做接口测试)
[备注说明]内文中的图片由于页面的限制,图片显示不清晰,为了能更加的看清图片,请点击"图片",点击"右键"选择"在新标签页中打开图片",可查 ...
- iPhone6 AirDrop找不到我的mac解决方法!注销mac和iPhone的icloud账号
注销mac和iPhone的icloud账号,icloud 会自动同步个人热点,个人热点开启状态,mac 和 iPhone 无法看到对方!