spark 机器学习基础 数据类型
spark的机器学习库,包含常见的学习算法和工具如分类、回归、聚类、协同过滤、降维等
使用算法时都需要指定相应的数据集,下面为大家介绍常用的spark ml 数据类型。
1.本地向量(Local Vector)
存储在单台机器上,索引采用0开始的整型表示,值采用Double类型的值表示。Spark MLlib中支持两种类型的矩阵,分别是密度向量(Dense Vector)和稀疏向量(Spasre Vector),密度向量会存储所有的值包括零值,而稀疏向量存储的是索引位置及值,不存储零值,在数据量比较大时,稀疏向量才能体现它的优势和价值
scala> import org.apache.spark.mllib.linalg.{Vector, Vectors}
注意:scala默认会导入scala.collection.immutable.Vector,所以必须显式导入org.apache.spark.mllib.linalg.Vector
1.1密度向量,零值也存储
scala> val dv: Vector = Vectors.dense(1.0, 0.0, 3.0)
1.2.1创建稀疏向量,指定元素的个数、索引及非零值,数组方式
基于索引(0,2)和值(1,3)创建稀疏向量
scala> val sv1: Vector = Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0))
1.2.2 创建稀疏向量,指定元素的个数、索引及非零值,采用序列方式
scala> val sv2: Vector = Vectors.sparse(3, Seq((0, 1.0), (2, 3.0)))
2.带类标签的特征向量(Labeled point)
Labeled point是Spark MLlib中最重要的数据结构之一,它在无监督学习算法中使用十分广泛,它也是一种本地向量,只不过它提供了类的标签,对于二元分类,它的标签数据为0和1,而对于多类分类,它的标签数据为0,1,2,…。它同本地向量一样,同时具有Sparse和Dense两种实现方式
scala> import org.apache.spark.mllib.regression.LabeledPoint
2.1LabeledPoint第一个参数是类标签数据,第二参数是对应的特征数据
//密度
scala> val pos = LabeledPoint(1.0, Vectors.dense(1.0, 0.0, 3.0))
scala> println(pos.features)
scala> println(pos.label)
//稀疏
scala> val neg = LabeledPoint(0.0, Vectors.sparse(3, Array(0, 2), Array(1.0, 3.0)))
注意:第2个特征值为0,从编程的角度来说,这样做可以减少内存的使用,并提高做矩阵内积时的运算速度
3.本地矩阵(Local matrix)
本地向量是由从0开始的整数下标和Double类型的数值组成。它有稠密向量(dense vector)和稀疏向量(sparse vertor)两种。在列的主要顺序中,它的非零输入值存储在压缩的稀疏列(CSC)格式中
在一维数组[1.0、3.0、5.0、2.0、4.0、6.0]中,对应的矩阵大小(3、2):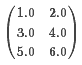
本地矩阵的基类是Matrix,提供了两种实现 DenseMatrix和SparseMatrix. 推荐使用工厂方法实现的Matrices来创建本地矩阵.
scala> import org.apache.spark.mllib.linalg.{Matrix, Matrices}
3.1 创建稠密矩阵
scala> val dm: Matrix = Matrices.dense(3, 2, Array(1.0, 3.0, 5.0, 2.0, 4.0, 6.0))
3.2 创建稀疏矩阵
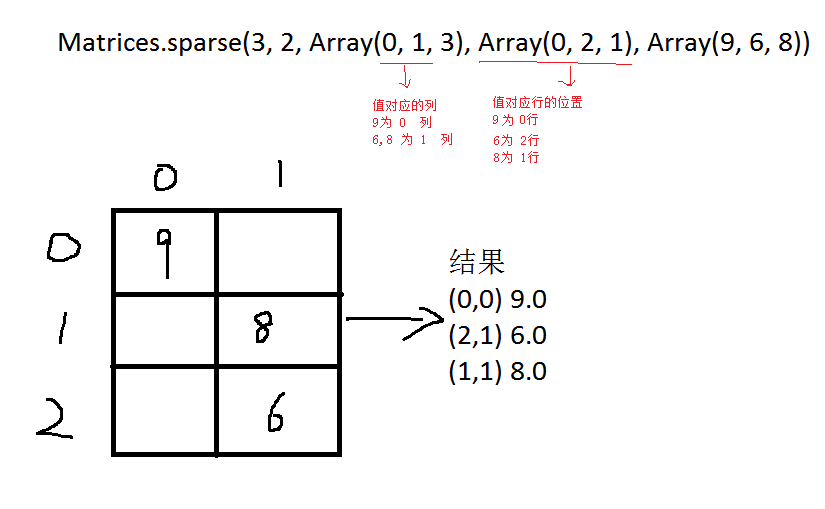
scala> val sm: Matrix = Matrices.sparse(3, 2, Array(0, 1, 3), Array(0, 2, 1), Array(9, 6, 8))
4.分布式矩阵(Distributed matrix)
分布式矩阵有Long类型的行列数据和Double类型值,存储在一个或多个RDDs中
4.1. 行矩阵(RowMatrix)
行矩阵是一个没有行索引的,以行为导向(row-oriented )的分布式矩阵,它的行只支持RDD格式,每一行都是一个本地向量。由于每一行都由一个局部向量表示,所以列的数量是由整数范围所限制的,但是在实际操作中应该要小得多
scala> import org.apache.spark.mllib.linalg.Vector
scala> import org.apache.spark.mllib.linalg.distributed.RowMatrix
scala> import org.apache.spark.mllib.linalg.{Vector, Vectors}
4.1.1 生成DataFrame
scala> val df1 = Seq(
(1.0, 2.0, 3.0),
(1.1, 2.1, 3.1),
(1.2, 2.2, 3.2)).toDF("c1", "c2", "c3")
scala> df1.show
c1 c2 c3
1.0 2.0 3.0
1.1 2.1 3.1
1.2 2.2 3.2
4.1.2 DataFrame转换成RDD[Vector]
scala> val rv1= df1.rdd.map {
x =>Vectors.dense(
x(0).toString().toDouble,
x(1).toString().toDouble,
x(2).toString().toDouble)
}
scala> rv1.collect()
4.1.3 创建行矩阵
scala> val mt1: RowMatrix = new RowMatrix(rv1)
scala> val m = mt1.numRows()
scala> val n = mt1.numCols()
查看:
scala> mt1.rows.collect()
或
scala>mt1.rows.map { x =>
(x(0).toDouble,
x(1).toDouble,
x(2).toDouble)
}.collect()
4.2 CoordinateMatrix坐标矩阵
CoordinateMatrix是一个分布式矩阵,每行数据格式为三元组(i: Long, j: Long, value: Double), i表示行索引,j表示列索引,value表示数值。只有当矩阵的两个维度都很大且矩阵非常稀疏时,才应该使用坐标矩阵。可以通过RDD[MatrixEntry]实例来创建一个CoordinateMatrix。MatrixEntry包装类型(Long, Long, Double)
scala> import org.apache.spark.mllib.linalg.distributed.CoordinateMatrix
scala> import org.apache.spark.mllib.linalg.distributed.MatrixEntry
4.2.1 生成df(行坐标,列坐标,值)
scala> val df = Seq(
(0, 0, 1.1), (0, 1, 1.2), (0, 2, 1.3),
(1, 0, 2.1), (1, 1, 2.2), (1, 2, 2.3),
(2, 0, 3.1), (2, 1, 3.2), (2, 2, 3.3)).toDF("row", "col", "value")
4.2.2 生成入口矩阵
scala> val m1 = df.rdd.map { x =>
val a = x(0).toString().toLong
val b = x(1).toString().toLong
val c = x(2).toString().toDouble
MatrixEntry(a, b, c)
}
scala> m1.collect()
4.2.3 生成坐标矩阵
scala> val m2 = new CoordinateMatrix(m1)
scala> m2.numRows()
scala> m2.numCols()
查看
scala> m2.entries.collect().take(10)
spark 机器学习基础 数据类型的更多相关文章
- Spark机器学习基础三
监督学习 0.线性回归(加L1.L2正则化) from __future__ import print_function from pyspark.ml.regression import Linea ...
- Spark机器学习基础二
无监督学习 0.K-means from __future__ import print_function from pyspark.ml.clustering import KMeans #from ...
- Spark机器学习基础一
特征工程 对连续值处理 0.binarizer/二值化 from __future__ import print_function from pyspark.sql import SparkSessi ...
- Spark机器学习基础-监督学习
监督学习 0.线性回归(加L1.L2正则化) from __future__ import print_function from pyspark.ml.regression import Linea ...
- Spark机器学习基础-无监督学习
0.K-means from __future__ import print_function from pyspark.ml.clustering import KMeans#硬聚类 #from p ...
- Spark机器学习基础-特征工程
对连续值处理 0.binarizer/二值化 from __future__ import print_function from pyspark.sql import SparkSession fr ...
- Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API
Spark机器学习MLlib系列1(for python)--数据类型,向量,分布式矩阵,API 关键词:Local vector,Labeled point,Local matrix,Distrib ...
- Spark机器学习4·分类模型(spark-shell)
线性模型 逻辑回归--逻辑损失(logistic loss) 线性支持向量机(Support Vector Machine, SVM)--合页损失(hinge loss) 朴素贝叶斯(Naive Ba ...
- 掌握Spark机器学习库(课程目录)
第1章 初识机器学习 在本章中将带领大家概要了解什么是机器学习.机器学习在当前有哪些典型应用.机器学习的核心思想.常用的框架有哪些,该如何进行选型等相关问题. 1-1 导学 1-2 机器学习概述 1- ...
随机推荐
- 用Excel导入Oracle数据库plsql
打开plsql之后,在工具栏点击[tools]--[ODBC Imoprter] 选择导入文件的类型,这里是excel文件,所以选择Excel Files 输入连接数据库的用户名和密码 点击Conne ...
- consoleWriter.go
package blog4go import ( "fmt" "os" "time" ) // ConsoleWriter is a con ...
- 【源码分析】Canal之Binlog的寻找过程
binlog的寻找过程可能的场景如下: instance第一次启动 发生数据库主备切换 canal server HA情况下的切换 所以这个过程是能够保证binlog不丢失的关键点. 本文从源码的角度 ...
- BZOJ_2622_[2012国家集训队测试]深入虎穴_最短路
BZOJ_2622_[2012国家集训队测试]深入虎穴_最短路 Description 虎是中国传统文化中一个独特的意象.我们既会把老虎的形象用到喜庆的节日装饰画上,也可能把它视作一种邪恶的可怕的动物 ...
- BZOJ_1925_[Sdoi2010]地精部落_递推
BZOJ_1925_[Sdoi2010]地精部落_递推 Description 传说很久以前,大地上居住着一种神秘的生物:地精. 地精喜欢住在连绵不绝的山脉中.具体地说,一座长度为 N 的山脉 H可分 ...
- CentOS7 通过YUM安装MySQL5.7
1.进入到要存放安装包的位置 cd /home/lnmp 2.查看系统中是否已安装 MySQL 服务,以下提供两种方式: rpm -qa | grep mysql yum list installed ...
- CountDownLatch和CyclicBarrier 区别
CountDownLatch : 一个线程(或者多个), 等待另外N个线程完成某个事情之后才能执行. CyclicBarrier : N个线程相互等待,任何一个线程完成之前,所有的线程都 ...
- MFC多语言程序版本,在不同的windows系统上的使用
如何使MFC程序界面支持多国语言?这次使用后给自己做一个总结. 我们使用vc6.0的版本来试验 1. 切换到资源视图,右键Dialog->Insert Copy 2. ok后,会出来一个语言的选 ...
- MIP 与 AMP 合作进展(3月7日)
"到目前为止,全网通过 MIP 校验的网页已超10亿.除了代码和缓存, MIP 还想做更多来改善用户体验移动页面." 3月7日,MIP 项目负责人在首次 AMP CONF 上发言. ...
- 微服务架构 - SpringBoot整合Jooq和Flyway
在一次学习分布式跟踪系统zipkin中,发现了jooq这个组件,当时不知这个组件是干嘛的,后来抽空学习了一下,感觉这个组件还挺用的.它主要有以下作用: 通过DSL(Domain Specific La ...