AI - TensorFlow - 过拟合(Overfitting)
过拟合
过拟合(overfitting,过度学习,过度拟合):
过度准确地拟合了历史数据(精确的区分了所有的训练数据),而对新数据适应性较差,预测时会有很大误差。
过拟合是机器学习中常见的问题,解决方法主要有下面几种:
1. 增加数据量
大部分过拟合产生的原因是因为数据量太少。
2. 运用正则化
例如L1、L2 regularization等等,适用于大多数的机器学习,包括神经网络。
3. Dropout
专门用在神经网络的正则化的方法。
Dropout regularization是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络。
只需要给予它一个不被drop掉的百分比,就能很好地降低overfitting。
也就是说,在训练的时候,随机忽略掉一些神经元和神经联结 ,使这个神经网络变得”不完整”,然后用一个不完整的神经网络训练一次。
到第二次再随机忽略另一些, 变成另一个不完整的神经网络。
有了这些随机drop掉的规则, 每一次预测结果都不会依赖于其中某部分特定的神经元。
Dropout的做法是从根本上让神经网络没机会过度依赖。
TensorFlow中的Dropout方法
TensorFlow提供了强大的dropout方法来解决overfitting问题。
示例
# coding=utf-8
from __future__ import print_function
import tensorflow as tf
from sklearn.datasets import load_digits # 使用sklearn中的数据
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelBinarizer
import os os.environ['TF_CPP_MIN_LOG_LEVEL'] = '' digits = load_digits()
X = digits.data
y = digits.target
y = LabelBinarizer().fit_transform(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=.3) # X_train是训练数据, X_test是测试数据 def add_layer(inputs, in_size, out_size, layer_name, activation_function=None, ):
Weights = tf.Variable(tf.random_normal([in_size, out_size]))
biases = tf.Variable(tf.zeros([1, out_size]) + 0.1, )
Wx_plus_b = tf.matmul(inputs, Weights) + biases
Wx_plus_b = tf.nn.dropout(Wx_plus_b, keep_prob) # dropout
if activation_function is None:
outputs = Wx_plus_b
else:
outputs = activation_function(Wx_plus_b, )
tf.summary.histogram(layer_name + '/outputs', outputs)
return outputs keep_prob = tf.placeholder(tf.float32) # keep_prob(保留的结果所占比例)作为placeholder在run时传入
xs = tf.placeholder(tf.float32, [None, 64])
ys = tf.placeholder(tf.float32, [None, 10]) l1 = add_layer(xs, 64, 50, 'l1', activation_function=tf.nn.tanh) # 隐含层
prediction = add_layer(l1, 50, 10, 'l2', activation_function=tf.nn.softmax) # 输出层 cross_entropy = tf.reduce_mean(-tf.reduce_sum(ys * tf.log(prediction),
reduction_indices=[1])) # loss between prediction and real data
tf.summary.scalar('loss', cross_entropy)
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy) sess = tf.Session()
merged = tf.summary.merge_all()
train_writer = tf.summary.FileWriter("logs/train", sess.graph)
test_writer = tf.summary.FileWriter("logs/test", sess.graph)
init = tf.global_variables_initializer()
sess.run(init) for i in range(500):
sess.run(train_step, feed_dict={xs: X_train, ys: y_train, keep_prob: 0.5}) # keep_prob=0.5相当于50%保留
if i % 50 == 0:
train_result = sess.run(merged, feed_dict={xs: X_train, ys: y_train, keep_prob: 1})
test_result = sess.run(merged, feed_dict={xs: X_test, ys: y_test, keep_prob: 1})
train_writer.add_summary(train_result, i)
test_writer.add_summary(test_result, i)
对比运行结果
在TensorBoard中查看。
训练中keep_prob=1时,暴露出overfitting问题,模型对训练数据的适应性优于测试数据,存在overfitting。
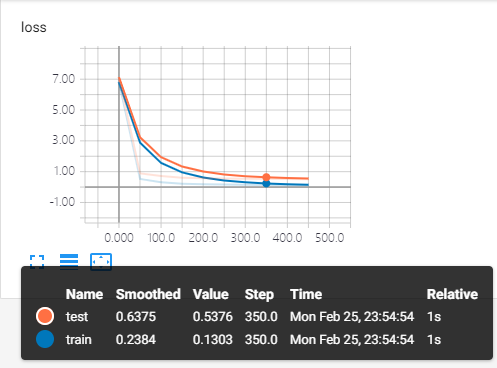
keep_prob=0.5时,dropout发挥了作用,减少了过拟合。

AI - TensorFlow - 过拟合(Overfitting)的更多相关文章
- AI - TensorFlow - 示例04:过拟合与欠拟合
过拟合与欠拟合(Overfitting and underfitting) 官网示例:https://www.tensorflow.org/tutorials/keras/overfit_and_un ...
- tensorflow学习4-过拟合-over-fitting
过拟合: 真实的应用中,并不是让模型尽量模拟训练数据的行为,而是希望训练数据对未知做出判断. 模型过于复杂后,模型会积极每一个噪声的部分,而不是学习数据中的通用 趋势.当一个模型的参数比训练数据还要多 ...
- 过拟合(Overfitting)和正规化(Regularization)
过拟合: Overfitting就是指Ein(在训练集上的错误率)变小,Eout(在整个数据集上的错误率)变大的过程 Underfitting是指Ein和Eout都变大的过程 从上边这个图中,虚线的左 ...
- AI - TensorFlow - 示例03:基本回归
基本回归 回归(Regression):https://www.tensorflow.org/tutorials/keras/basic_regression 主要步骤:数据部分 获取数据(Get t ...
- AI - TensorFlow - 示例01:基本分类
基本分类 基本分类(Basic classification):https://www.tensorflow.org/tutorials/keras/basic_classification Fash ...
- tensorflow神经网络拟合非线性函数与操作指南
本实验通过建立一个含有两个隐含层的BP神经网络,拟合具有二次函数非线性关系的方程,并通过可视化展现学习到的拟合曲线,同时随机给定输入值,输出预测值,最后给出一些关键的提示. 源代码如下: # -*- ...
- TensorFlow非线性拟合
1.心得: 在使用TensorFlow做非线性拟合的时候注意的一点就是输出层不能使用激活函数,这样就会把整个区间映射到激活函数的值域范围内无法收敛. # coding:utf-8 import ten ...
- AI - TensorFlow - 示例02:影评文本分类
影评文本分类 文本分类(Text classification):https://www.tensorflow.org/tutorials/keras/basic_text_classificatio ...
- AI - TensorFlow - 分类与回归(Classification vs Regression)
分类与回归 分类(Classification)与回归(Regression)的区别在于输出变量的类型.通俗理解,定量输出称为回归,或者说是连续变量预测:定性输出称为分类,或者说是离散变量预测. 回归 ...
随机推荐
- Python3.6安装报错 configure: error: no acceptable C compiler found in $PATH
安装python的时候出现如下的错误: [root@master ~]#./configure --prefix=/usr/local/python3.6 checking build system ...
- Python简介之输入和输出
输出 输入 输出 用print()在括号中加上字符串就可以向屏幕上输出指定的文字.比如输出'hello,world!',用代码实现如下:print('hello world!'). print()函数 ...
- 错误:编码GBK的不可映射字符
当Java源代码中包含中文字符时,我们在用javac编译时会出现"错误:编码GBK的不可映射字符". 由于JDK是国际版的,我们在用javac编译时,编译程序首先会获得我们操作系统 ...
- 开机进入grub命令行之后。。。。
最近由于经常整理自己电脑上的文件,难免都会遇到误删系统文件或者操作失误导致系统不能够正常进入的情况.这时就会出现grub错误的提示,只能输入命令才能进入系统.那么该输入什么命令呢?其实非常简单. gr ...
- go源文件中是否有main函数
import ( "go/parser" "go/token" "go/ast" ) func HasMain(file s ...
- iscc2018(一只猫的心思)
由于这一个杂项类没有更新,所以今天特地来写一下博文.希望能够帮助到你们!!!! 其他关于杂项类的解析,可以查看(https://blog.csdn.net/qq_41187256/article/de ...
- springboot redis多数据源
springboot中默认的redis配置是只能对单个redis库进行操作的. 那么我们需要多个库操作的时候这个时候就可以采用redis多数据源. 本代码参考RedisAutoConfiguratio ...
- 前端随笔 - JavaScript中的闭包
前阵子重新复习了一下js基础知识,第一篇博客就以分享闭包心得为开始吧. 首先,要理解闭包,就必须要了解一个概念:作用域链. 作用域链 作用域代表着可访问变量的集合,变量分为全局变量和局部变量两种,在函 ...
- PostCSS 基本用法
1.postcss相关网站 https://www.postcss.com.cn/ https://www.ibm.com/developerworks/cn/web/1604-postcss-css ...
- 菜鸟如何反转到资深Web安全工程师
90后理工男,计算机专业,毕业于985院校,从事Web安全工作,两年多的时间里先后跳槽3家公司,跳槽理由主要有以下几点:加班多.薪资低.工作内容枯燥,不想安于现状,寄希望于通过跳槽找到一个“钱多.活少 ...