改善深层神经网络(三)超参数调试、Batch正则化和程序框架
1、超参数调试:
(1)超参数寻找策略:
对于所有超参数遍历求最优参数不可取,因为超参数的个数可能很多,可选的数据过于庞大.
由于最优参数周围的参数也可能比较好,所以可取的方法是:在一定的尺度范围内随机取值,先寻找一个较好的参数,再在该参数所在的区域更精细的寻找最优参数.
(2)选择合适的超参数范围:
假设 n[l] 可选取值 50~100:在整个范围内随机均匀取值
选取神经网络层数 #layers,L的可选取值为 2~4:在整个范围内随机均匀取值
学习速率 α 的可选取值 0.0001~1:在对数轴上随机均匀取值
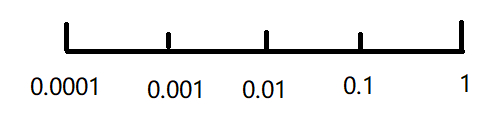
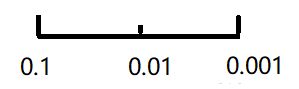
β 的可选取值 0.9~0.999:在 1-β 的对数轴上随机均匀取值
2、Batch归一化:
(1)问题背景:
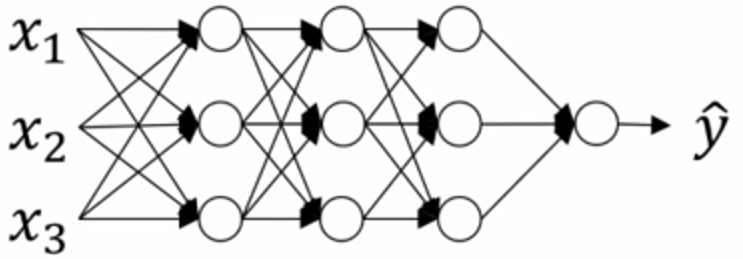
a[1] a[2] a[3]
之前介绍的正则化输入是对 X 进行正则化,那么能否对 a[2] 进行正则化(本质是对 z[2] 正则化),以更快地训练 w[3] 和 b[3] ?
(2)Batch归一化流程:
给出参数:Z(1) ... Z(m)
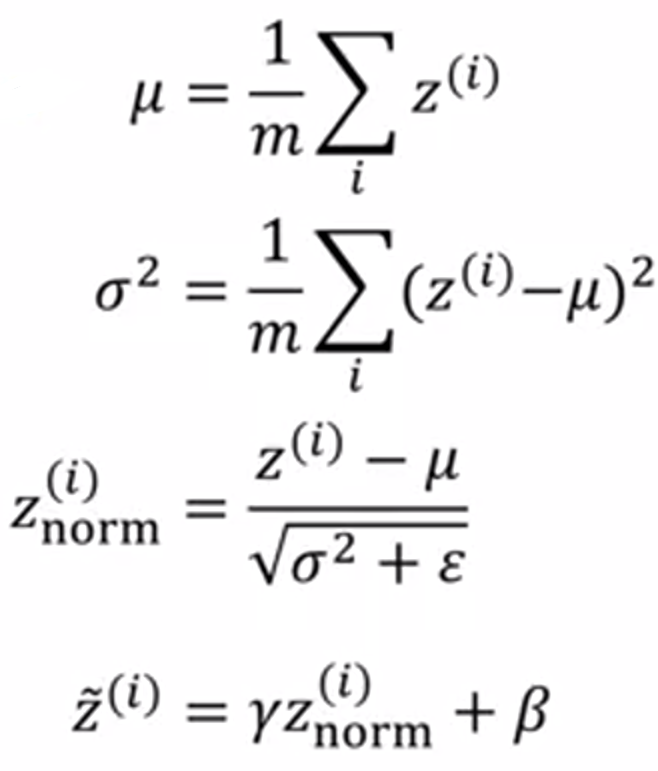
其中 γ 和 β 为学习参数,作用是:可以随意设置 Z~(i) 的平均值和方差.
传播过程:
X — w[1],b[1] —> Z[1] — γ[1], β[1] —> Z~[1] —g(Z~[1]) —> A[1] — w[2],b[2] —> Z[2] — ... —> Y^
需要优化的参数:
W[1], b[1], ..., W[L], b[L]
γ[1], β[1], ..., γ[L], β[L]
一个小的简化:
由于在计算 Z~(i) 前会通过正则化把均值设成0,那么参数 b 可以不用加上.
(3)应用:
for t = 1 ... num_MiniBatches:
Compute forward prop on X{t}
In each hidden layer,use Batch Norm to replace Z[l] with Z~[l]
Use backprop to compute dW[l], dβ[l], dγ[l]
Update parameters W[l], β[l], γ[l]
(Work with momentum、RMSprop、Adam)
3、Softmax回归:
(1)举例说明:
Softmax回归适用于多类别分类,以4分类为例:
神经网络模型:
假设 Z[L] = [5, 2, -1, 3]T
t = [e5, e2, e-1, e3]T ≈ [148.4, 7.4, 0.4, 20.1]T
∑ t = 176.3
a[L] = t / ∑ t = [0.842, 0.042, 0.002, 0.114]T
即是分类0的概率是0.842,分类1的概率是0.042,分类2的概率是0.002,分类3的概率是0.114.
(2)Softmax分类器损失函数:
训练结果集:Y = [y(1), y(2), ..., y(m)],每一个 y(i) 都是一个列向量.
预测结果集:Y^ = [y^(1), y^(2), ..., y^(m)]
单个训练样本的损失函数: L(y^, y) = - ∑ yj * log(y^j)
整个训练集的损失函数:J(w[1], b[1], ...) = 1 / m * ∑ L(y^(i), y(i))
4、TensorFlow使用举例:
最小化 J = (w - 5)² = w² - 10w + 25:
(1)写法①:
w = tf.Variable(0, dtype = tf.float32)
cost = tf.add(tf.add(w**2, tf.multiply(-10, w)), 25)
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w))
#输出0.0
for i in range(1000):
session.run(train)
print(session.run(w))
#输出4.99999
(2)写法②:
coefficients = np.array([[1.], [-10.], [25.]])
w = tf.Variable(0, dtype = tf.float32)
x = tf.placeholder(tf.float32, [3,1])
cost = x[0][0]*w**2 + x[1][0]*w + x[2][0]
train = tf.train.GradientDescentOptimizer(0.01).minimize(cost)
init = tf.global_variables_initializer()
session = tf.Session()
session.run(init)
print(session.run(w))
#输出0.0
for i in range(1000):
session.run(train, feed_dicts(x:coefficients))
print(session.run(w))
#输出4.99999
改善深层神经网络(三)超参数调试、Batch正则化和程序框架的更多相关文章
- Deep Learning.ai学习笔记_第二门课_改善深层神经网络:超参数调试、正则化以及优化
目录 第一周(深度学习的实践层面) 第二周(优化算法) 第三周(超参数调试.Batch正则化和程序框架) 目标: 如何有效运作神经网络,内容涉及超参数调优,如何构建数据,以及如何确保优化算法快速运行, ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 Batch归一化 Softmax
摘抄:https://xienaoban.github.io/posts/2106.html 1. 调试(Tuning) 超参数 取值 #学习速率:\(\alpha\) Momentum:\(\bet ...
- DeepLearning.ai学习笔记(二)改善深层神经网络:超参数调试、正则化以及优化--Week2优化算法
1. Mini-batch梯度下降法 介绍 假设我们的数据量非常多,达到了500万以上,那么此时如果按照传统的梯度下降算法,那么训练模型所花费的时间将非常巨大,所以我们对数据做如下处理: 如图所示,我 ...
- Andrew Ng - 深度学习工程师 - Part 2. 改善深层神经网络:超参数调试、正则化以及优化(Week 2. 优化算法)
===========第2周 优化算法================ ===2.1 Mini-batch 梯度下降=== epoch: 完整地遍历了一遍整个训练集 ===2.2 理解Mini-bat ...
- deeplearning.ai 改善深层神经网络 week3 超参数调试、Batch正则化和程序框架 听课笔记
这一周的主体是调参. 1. 超参数:No. 1最重要,No. 2其次,No. 3其次次. No. 1学习率α:最重要的参数.在log取值空间随机采样.例如取值范围是[0.001, 1],r = -4* ...
- deeplearning.ai 改善深层神经网络 week3 超参数调试、Batch Normalization和程序框架
这一周的主体是调参. 1. 超参数:No. 1最重要,No. 2其次,No. 3其次次. No. 1学习率α:最重要的参数.在log取值空间随机采样.例如取值范围是[0.001, 1],r = -4* ...
- Coursera Deep Learning笔记 改善深层神经网络:超参数调试 正则化以及梯度相关
笔记:Andrew Ng's Deeping Learning视频 参考:https://xienaoban.github.io/posts/41302.html 参考:https://blog.cs ...
- 吴恩达《深度学习》第二门课(3)超参数调试、Batch正则化和程序框架
3.1调试处理 (1)不同超参数调试的优先级是不一样的,如下图中的一些超参数,首先最重要的应该是学习率α(红色圈出),然后是Momentum算法的β.隐藏层单元数.mini-batch size(黄色 ...
- 跟我学算法-吴恩达老师(超参数调试, batch归一化, softmax使用,tensorflow框架举例)
1. 在我们学习中,调试超参数是非常重要的. 超参数的调试可以是a学习率,(β1和β2,ε)在Adam梯度下降中使用, layers层数, hidden units 隐藏层的数目, learning_ ...
随机推荐
- ES6 - 基础学习(5): 数值扩展
二进制和八进制数值表示法 ES6提供了二进制和八进制数值的新写法,分别前缀 0b(或0B). 0o(或0O)然后跟上二进制.八进制值即可. 二进制(Binary)表示法新写法:前缀 0b 或 0B. ...
- Blazor初体验之寻找存储client-side jwt token的方法
https://www.cnblogs.com/chen8854/p/securing-your-blazor-apps-authentication-with-clientside-blazor-u ...
- vue中允许你继续使用swiper的组件 vue-awesome-swiper---切图网
swiper是一个在切图中好用到不行的图片轮播插件,包括3d轮播.h5滑屏等复杂应用都不在话下,到了vue项目一切逻辑完全颠覆了,没有获取dom的概念,还好有 vue-awesome-swiper组件 ...
- IDEA 优化使用配置
IDEA设置鼠标滑轮改变字体大小 点击 File - settings,找到 Editor - General,如图所示,勾上 Change font size(Zoom) with Ctrl+Mou ...
- Centos7下安装包方式安装MySQL
安装包下载地址:https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.27-1.el7.x86_64.rpm-bundle.tar 第一步:在 /h ...
- python数据类型(第二弹)
针对上一篇博文提出的若干种python数据类型,笔者将在本文和后续几篇博文中详细介绍. 本文着重介绍python数据类型中的整数型.浮点型.复数型.布尔型以及空值. 对于整数型.浮点型和复数型数据,它 ...
- Sublime Text 3 最新可用注册码(免破解)(转载)
转载地址:https://sjolzy.cn/Sublime-Text-3-crack-registration-code.html 12年的时候分享过Sublime Text 2的注册码和破解方法. ...
- SPFA的优化一览
目录 序 内容 嵬 序 spfa,是一个早已没人用的算法,就像那些麻木的人, 可谁有知道,他何时槃涅 一个已死的算法 ,重生 内容 关于\(NOI2018D1T1\)的惨案,为了以防spfa被卡. 关 ...
- 打印机打印pdf文件特别慢怎么解决
PDF等文件中都包含了一些或者很多光栅化数据(图片.嵌入的字体等).这些文件在打印时,打印机驱动程序都会在系统中生成大量EMF文件(增强型变换文件),小到1MB,大到500MB,过大的EMF临时文件会 ...
- 用记事本编辑HTML文件后保存代码全堆在一起了,记事本打开html文件格式乱了
经常会遇到这么一个现象,记事本打开编辑html代码,保存后格式就乱了,代码全部堆在一行了.遇到这种情况有时候也很无语 因为平常工作中也经常遇到这样的情况,后来通过研究,大概找到问题的所在. 我是这么一 ...