bp算法中为什么会产生梯度消失?
链接:https://www.zhihu.com/question/49812013/answer/148825073
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
简单地说,根据链式法则,如果每一层神经元对上一层的输出的偏导乘上权重结果都小于1的话( ),那么即使这个结果是0.99,在经过足够多层传播之后,误差对输入层的偏导会趋于0(
)。下面是数学推导推导。
假设网络输出层中的第 个神经元输出为
,而要学习的目标为
。这里的
表示时序,与输入无关,可以理解为网络的第
层。
<img src="https://pic2.zhimg.com/50/v2-2fae1a385c8dcada16e17799fa175711_hd.png" data-rawwidth="560" data-rawheight="397" class="origin_image zh-lightbox-thumb" width="560" data-original="https://pic2.zhimg.com/v2-2fae1a385c8dcada16e17799fa175711_r.png">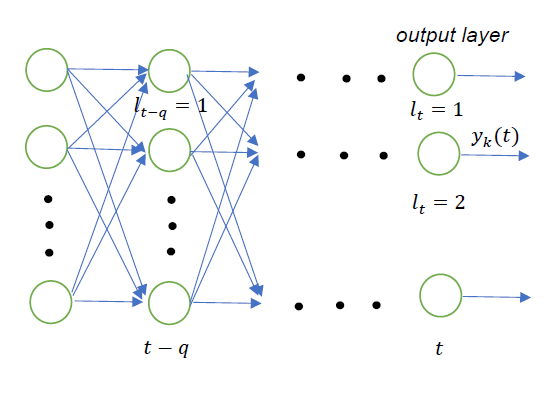
若采用平方误差作为损失函数,第 个输出神经元对应的损失为
将损失 对输出
求偏导
根据链式法则,我们知道,第 层的梯度可以根据第
层的梯度求出来
这里用 表示第
层的第
个神经元,
表示第
层的第
个神经元。
进一步,第 层的梯度可以由第
层的梯度计算出来
这实际上是一个递归嵌套的式子,如果我们对 做进一步展开,可以得到式子
最终,可以一直展开到第 层。
把所有的加法都移到最外层,可以得到
表示的是第
层中神经元的下标(即第
层第
个神经元),
表示第
层的下标。
对应输出层,
对应第
层。实际上展开式就是从网络的第
层到
层,每一层都取出一个神经元来进行排列组合的结果。这个式子并不准确,因为
时实际是损失
对输出层的偏导,即
,
并没有应用权重,把它修正一下
这样,我们就得到了第 层和第
层的梯度之间的关系
在上面的式子中,由于加法项正负号之间可能互相抵消。因此,比值的量级主要受最后的乘法项影响。如果对于所有的 有
则梯度会随着反向传播层数的增加而呈指数增长,导致梯度爆炸。
如果对于所有的 有
则在经过多层的传播后,梯度会趋向于0,导致梯度消失。
LSTM就是为了解决以上两个问题提出的方法之一,它强制令 。 LSTM如何来避免梯度弥撒和梯度爆炸? - 知乎
有兴趣可以参考Long Short Term Memory 一文 。上面的推导过程大体上也参考自这篇论文。
Reference:
Graves, Alex. Long Short-Term Memory. Supervised Sequence Labelling with Recurrent Neural Networks. Springer Berlin Heidelberg, 2012:1735-1780.
bp算法中为什么会产生梯度消失?的更多相关文章
- 关于BP算法在DNN中本质问题的几点随笔 [原创 by 白明] 微信号matthew-bai
随着deep learning的火爆,神经网络(NN)被大家广泛研究使用.但是大部分RD对BP在NN中本质不甚清楚,对于为什这么使用以及国外大牛们是什么原因会想到用dropout/sigmoid ...
- 今天开始学Pattern Recognition and Machine Learning (PRML),章节5.2-5.3,Neural Networks神经网络训练(BP算法)
转载请注明出处:http://www.cnblogs.com/xbinworld/p/4265530.html 这一篇是整个第五章的精华了,会重点介绍一下Neural Networks的训练方法——反 ...
- 梯度消失&&梯度爆炸
转载自: https://blog.csdn.net/qq_25737169/article/details/78847691 前言 本文主要深入介绍深度学习中的梯度消失和梯度爆炸的问题以及解决方案. ...
- LSTM及其变种及其克服梯度消失
本宝宝又转了一篇博文,但是真的很好懂啊: 写在前面:知乎上关于lstm能够解决梯度消失的问题的原因: 上面说到,LSTM 是为了解决 RNN 的 Gradient Vanish 的问题所提出的.关于 ...
- DNN的BP算法Python简单实现
BP算法是神经网络的基础,也是最重要的部分.由于误差反向传播的过程中,可能会出现梯度消失或者爆炸,所以需要调整损失函数.在LSTM中,通过sigmoid来实现三个门来解决记忆问题,用tensorflo ...
- 神经网络 误差逆传播算法推导 BP算法
误差逆传播算法是迄今最成功的神经网络学习算法,现实任务中使用神经网络时,大多使用BP算法进行训练. 给定训练集\(D={(x_1,y_1),(x_2,y_2),......(x_m,y_m)} ...
- 机器学习 —— 基础整理(八)循环神经网络的BPTT算法步骤整理;梯度消失与梯度爆炸
网上有很多Simple RNN的BPTT(Backpropagation through time,随时间反向传播)算法推导.下面用自己的记号整理一下. 我之前有个习惯是用下标表示样本序号,这里不能再 ...
- 神经网络中 BP 算法的原理与 Python 实现源码解析
最近这段时间系统性的学习了 BP 算法后写下了这篇学习笔记,因为能力有限,若有明显错误,还请指正. 什么是梯度下降和链式求导法则 假设我们有一个函数 J(w),如下图所示. 梯度下降示意图 现在,我们 ...
- Recurrent Neural Network系列3--理解RNN的BPTT算法和梯度消失
作者:zhbzz2007 出处:http://www.cnblogs.com/zhbzz2007 欢迎转载,也请保留这段声明.谢谢! 这是RNN教程的第三部分. 在前面的教程中,我们从头实现了一个循环 ...
随机推荐
- AtomicReference,AtomicStampedReference与AtomicMarkableReference的区别
AtomicReference 通过volatile和Unsafe提供的CAS函数实现原子操作. 自旋+CAS的无锁操作保证共享变量的线程安全 value是volatile类型,这保证了:当某线程修改 ...
- [Go] 正则表达式 示例
package main import "bytes" import "fmt" import "regexp" func main() { ...
- spanner-becoming-a-sql-system 2017
https://blog.acolyer.org/2017/07/03/spanner-becoming-a-sql-system/?utm_source=tuicool&utm_medium ...
- SpringMVC介绍之视图解析器ViewResolver
在前一篇博客中讲了SpringMVC的Controller控制器,在这篇博客中将接着介绍一下SpringMVC视图解析器.当我们对SpringMVC控制的资源发起请求时,这些请求都会被SpringMV ...
- delphi teechrt中TChart 一些属性设置
把图片设置成黑白 2.设置颜色
- git 自动转换行符的坑爹案例
本人写的脚本都是在unix上运行的,但是编写有时候喜欢使用Git拉去到windows的ide进行编写,毕竟我的unix只有命令行的没有ide, 殊不知有一天我的sh执行时出现错误 -bash: ./d ...
- 微软收购跨平台移动开发公司Xamarin
摘要:北京时间2月25日早间消息,微软周三宣布收购创业公司Xamarin,这也是该公司为了吸引更多软件工程师为其云计算服务编写程序而采取的最新举措.古斯里表示,总部位于旧金山的Xamarin创立于20 ...
- Maven 使用了一个标准的目录结构和一个默认的构建生命周期。
Maven 使用了一个标准的目录结构和一个默认的构建生命周期. 约定优于配置 当创建 Maven 工程时,Maven 会创建默认的工程结构.开发者只需要合理的放置文件,而在 pom.xml 中不再需要 ...
- JAVA BigDecimal的相加
之前很少使用这样的一个对象BigDecimal,今天在改需求的时候遇到了,结果坑爹的怎么相加最后都为零. 代码如下: BigDecimal totalAmount = new BigDecimal(0 ...
- arcmap搜索脚本错误
C盘/windows/temp,将temp文件夹右键单击,选择属性>选择安全>编辑>AlL APPLICATION PACKAGES>确定>关闭,如是操作即可解决 在cu ...