Hadoop源码解析 1 --- Hadoop工程包架构解析
1 Hadoop中各工程包依赖简述 Google的核心竞争技术是它的计算平台。Google的大牛们用了下面5篇文章,介绍了它们的计算设施。 GoogleCluster: http://research.google.com/archive/googlecluster.html Chubby:http://labs.google.com/papers/chubby.html GFS:http://labs.google.com/papers/gfs.html BigTable:http://labs.google.com/papers/bigtable.html MapReduce:http://labs.google.com/papers/mapreduce.html 很快,Apache上就出现了一个类似的解决方案,目前它们都属于Apache的Hadoop项目,对应的分别是: Chubby-->ZooKeeper GFS-->HDFS BigTable-->HBase MapReduce-->Hadoop 目前,基于类似思想的Open Source项目还很多,如Facebook用于用户分析的Hive。 HDFS作为一个分布式文件系统,是所有这些项目的基础。分析好HDFS,有利于了解其他系统。由于Hadoop的HDFS和MapReduce是同一个项目,我们就把他们放在一块,进行分析。 Hadoop包之间的依赖关系比较复杂,原因是HDFS提供了一个分布式文件系统, 该系统提供API,可以屏蔽本地文件系统和分布式文件系统,甚至象Amazon S3这样的在线存储系统。这就造成了分布式文件系统的实现,或者是分布式 文件系统的底层的实现,依赖于某些貌似高层的功能。功能的相互引用,造成了蜘蛛网型的依赖关系。一个典型的例子就是包conf,conf用于读取系统配 置,它依赖于fs,主要是读取配置文件的时候,需要使用文件系统,而部分的文件系统的功能,在包fs中被抽象了。
2 Hadoop和Google分布式系统对应产品

3 Hadoop工程中各工程包依赖图示
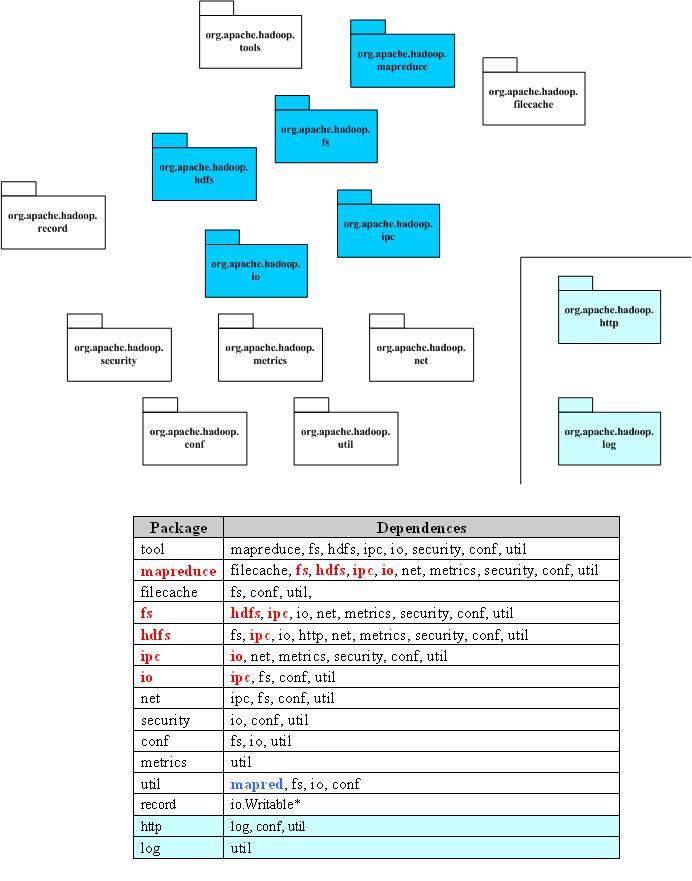
4 Hdoop工程中各工程包文件夹图示

5 各包功能
|
Package |
Dependences |
|
tool |
提供一些命令行工具,如DistCp,archive |
|
mapreduce |
Hadoop的Map/Reduce实现 |
|
filecache |
提供HDFS文件的本地缓存,用于加快Map/Reduce的数据访问速度 |
|
fs |
文件系统的抽象,可以理解为支持多种文件系统实现的统一文件访问接口 |
|
hdfs |
HDFS,Hadoop的分布式文件系统实现 |
|
ipc |
一个简单的IPC的实现,依赖于io提供的编解码功能 参考:http://zhangyu8374.iteye.com/blog/86306 |
|
io |
表示层。将各种数据编码/解码,方便于在网络上传输 |
|
net |
封装部分网络功能,如DNS,socket |
|
security |
用户和用户组信息 |
|
conf |
系统的配置参数 |
|
metrics |
系统统计数据的收集,属于网管范畴 |
|
util |
工具类 |
|
record |
根据DDL(数据描述语言)自动生成他们的编解码函数,目前可以提供C++和Java |
|
http |
基于Jetty的HTTP Servlet,用户通过浏览器可以观察文件系统的一些状态信息和日志 |
|
log |
提供HTTP访问日志的HTTP Servlet |
原创文章欢迎转载,转载时请注明出处。
作者推荐文章:
》如何获取系统信息(包括操作系统、jvm、cpu、内存、硬盘、网络等)
Hadoop源码解析 1 --- Hadoop工程包架构解析的更多相关文章
- Hadoop工程包架构解析
Hadoop源码解析 1 --- Hadoop工程包架构解析 1 Hadoop中各工程包依赖简述 Google的核心竞争技术是它的计算平台.Google的大牛们用了下面5篇文章,介绍了它们的计算 ...
- (转)把hadoop源码关联到eclipse工程
把hadoop源码关联到eclipse工程 转:http://www.superwu.cn/2013/08/04/355 在eclipse中阅读源码非常方便,利于我们平时的学习,下面讲述如何把 ...
- hadoop源码import到eclipse工程
1.解压hadoop-1.1.2.tar.gz,重点在src文件夹 2.在eclipse中通过菜单栏创建一个java工程,工程名随便 3.在创建的工程上,点击右键,在弹出菜单中选择最后一项,在弹出窗口 ...
- 使用其他Java工程导入hadoop源码用于在hadoop工程中查看源码
疑问:在开发hadoop程序的时候,有时候需要查看hadoop的源码,但是开发环境看不到,甚是烦恼,经过网上搜索和琢磨,终于实现了,虽然有点绕,但是目的达到了. 第一步:下载hadoop的源码包:ha ...
- hadoop源码分析(2):Map-Reduce的过程解析
一.客户端 Map-Reduce的过程首先是由客户端提交一个任务开始的. 提交任务主要是通过JobClient.runJob(JobConf)静态函数实现的: public static Runnin ...
- Hadoop源码分析(1):HDFS读写过程解析
一.文件的打开 1.1.客户端 HDFS打开一个文件,需要在客户端调用DistributedFileSystem.open(Path f, int bufferSize),其实现为: public F ...
- Hadoop源码分析:Hadoop编程思想
60页的ppt讲述Hadoop的编程思想 下载地址 http://download.csdn.net/detail/popsuper1982/9544904
- Hadoop源码分析(3): Hadoop的运行痕迹
在使用hadoop的时候,可能遇到各种各样的问题,然而由于hadoop的运行机制比较复杂,因而出现了问题的时候比较难于发现问题. 本文欲通过某种方式跟踪Hadoop的运行痕迹,方便出现问题的时候可以通 ...
- Hadoop源码编译过程
一. 为什么要编译Hadoop源码 Hadoop是使用Java语言开发的,但是有一些需求和操作并不适合使用java,所以就引入了本地库(Native Libraries)的概念,通 ...
随机推荐
- git 对文件大小写修改无反应 不敏感解决办法
git config core.ignorecase false 执行之后就能自动检测到了 2019-01-18
- PHPStorm等编辑器debug调试(包括使用postman、soapUI)
很多人在开发的时候,需要进行断点调试,但是很多人配置了很多,还是调试不了,其实是不需要这么麻烦的. 注意:PHPStorm等编辑器debug的配置不用进行任何配置,默认配置就好 实质上,断点调试的时候 ...
- 关于Quartz 2D绘图的简单使用
Quartz 2D是一个二维图形绘制引擎,支持iOS环境和Mac OS X环境,Quartz 2D的API可以实现许多功能,如:基于路径的绘图.透明度.阴影.颜色管理.反锯齿.PDF文档生成和PDF元 ...
- 一台ECS服务器,部署多(两)应用,且应用配置不同域名
场景 产品环境服务器有两台,前后端各分配一台服务器.现在在不增加机器的情况下,需要增加部署一套服务给台北地区服务. 现有的前端部署方案. 产品环境部署方案详解 实现 配置NAT步骤 ECS配置多网卡, ...
- MongoDB 4.0.6 Manual
General mongod options: -v [ --verbose ] [=arg(=v)] be more verbose (include multiple times for more ...
- mysql索引建立原则
看了网上一些网上关于创建索引的原则,在这里做一下总结: 1.尽量创建在使用频率较高的字段上,比如主键,外键,where总用到的字段,join是相关联的字段 2.如果表过大,一定要创建索引. 3.索引应 ...
- LinkedList的源码分析(基于jdk1.8)
1.初始化 public LinkedList() { } 并未开辟任何类似于数组一样的存储空间,那么链表是如何存储元素的呢? 2.Node类型 存储到链表中的元素会被封装为一个Node类型的结点.并 ...
- HDFS的JavaAPI
配置windows平台的Hadoop环境 在 windows 上做 HDFS 客户端应用开发,需要设置 Hadoop 环境,而且要求是windows 平台编译的 Hadoop,不然会报以下的错误: F ...
- rails中使用CarrierWave实现文件上传的功能
之前在用django写blog的时候头像上传和头像预览都是使用原生的js实现的,之前也有写了一篇blog.好了开始进入正题 rails中实现头像上传十分的方便,只要通过CarrierWave这个gem ...
- MP3 编码解码 附完整c代码
近期一直不间断学习音频处理,一直也没想着要去碰音频编解码相关. 主要是觉得没什么实际的作用和意义. 不管视频编解码,图像编解码,音频编解码,都有很多组织基金在推动. 当然,在一些特定的情景下,需要用起 ...