Machine Learning分类:监督/无监督学习
从宏观方面,机器学习可以从不同角度来分类
- 是否在人类的干预/监督下训练。(supervised,unsupervised,semisupervised 以及 Reinforcement Learning)
- 是否可以增量学习 (在线学习,批量学习)
- 是否是用新数据和已知数据比较,还是在训练数据中发现一些规律build出一个预测模型(instance-based ,model-based learning).
以上分类并非互相排斥。这一节我们介绍监督/无监督学习。
Supervised/Unsupervised学习
如同父母监督孩子学习一样,不同的父母有不同的监督手段,有的是形影不离,有的则是放养。这里分为四类 supervised , unsupervised , semisupervised和Reinforcement Learning.
Supervised 学习
在supervised学习中,你提供给算法的数据集(Trainng data)中已经包含了预期的结果(Labels)。
一个典型的supervised学习任务是分类(classfication)。比如垃圾邮件过滤,训练集中包含了邮件本身以及他们的标签(分类,是否为垃圾邮件),训练出来的模型会对新邮件进行分类,然后采取过滤策略。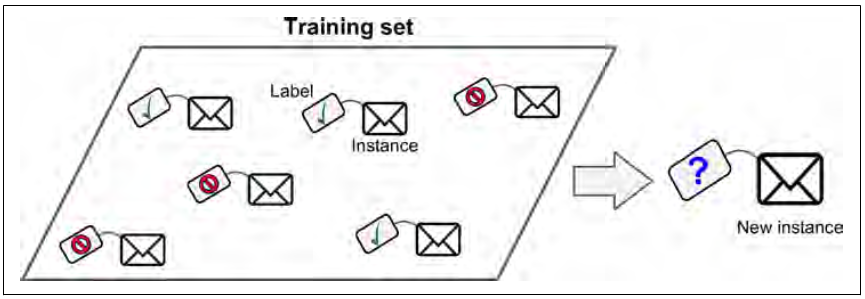
另一典型的任务是预测一个目标数值,比如通过提供相关的feature/attribute集合(比如公里数,品牌,出厂日期)来预测轿车的价格。 这些feature被称作predictors(预测因子)。这种任务被称作regression。为了训练系统,我们需要提供大量数据包含这些预测因子和标签(车价格) 。
某些regression的算法也可以用来做classfication,反之亦然。比如我们可以使用逻辑回归算法来给出一个代表属于某种类别的可能性的值(如20%的概率是垃圾邮件)
下面是一些常用的监督学习算法:
- k-Nearest Neighbors
- Linear Regression
- Logistic Regression
- Support Vector Machines(SVMs)
- Decision Trees and Random Forests
- Neural networks
Unsupervised 学习
很容易猜到,无监督学习并不需要给数据打标签(labels),可以实现不需要父母监督下自主学习。下面是常用的无监督学习算法。
- Clustering
- k-Means
- Hierarchical Cluster Analysis(HCA)
- Expectation Maximization
- Visualization and dimensionality reduction
- Principal Component Analysis(PCA)
- Kernel PCA
- Locally-Linear Embedding(LLE)
- t-distributed Stochastic Neighbor Embedding(t-SNE)
- Association rule learning
- Apriori
- Eclat
比如,你有大量关于博客访问者的数据,你可以使用聚类算法去探测相似行为的访问者。你并不需要告诉算法如何分组,算法会自动找到一些关联。比如,它会发现40%的访问者是男性,他们喜欢漫画书并且大致是晚上阅读你的博客,而20%的是年轻的科幻小说爱好者,他们经常在周末访问博客,等等。 如果你使用Hierachical Clustering算法,它会继续把每个组再次分为更详细的组。这有助于你的博客定位不同的用户群体。
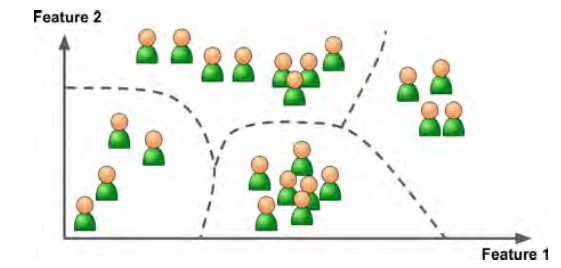
对于Visualization 算法,虽然输入的看似复杂没有标签的数据,但它能根据数据绘制出相应的2D或者3D图形。这些算法会尝试保留更多的类型结构,避免独立的聚类互相重叠,我们则可以了解数据是如何组织,也许可以发现潜在的未知规律。

Dimensionality reduction被用来简化数据(在不丢失很多信息的情况下)。一种用途是通过将多个相关联的feature合并为一个。比如,轿车的里程数和其年龄联系比较紧密,所以,Dimensionality reduction算法将合并二者为一个feature来反应车辆的损耗。 这被称作feature extraction(特征抽取).Feature extraction是一个很有用的技术,它使后续的机器学习算法运行更快(因为数据占用更少磁盘和内存),某些情况下,更准确。
还有一种无监督学习是anomaly detection,比如监测不正常的信用卡交易防止欺诈,捕获制造中的缺陷,自动从数据集中移除outliers(异常值,极端值,离群值)。通过正常数据训练模型,然后应用于新数据,它可以告诉我们新的数据是否正常。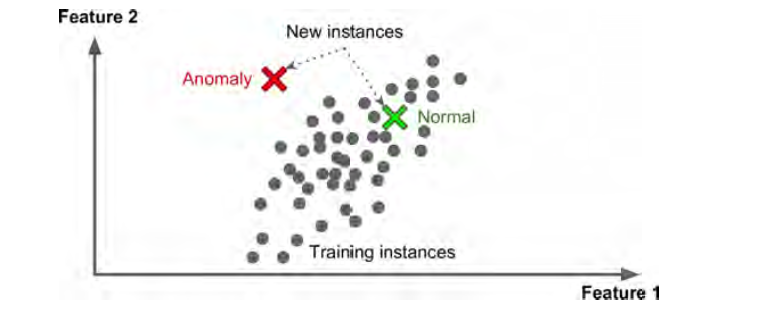
我们要说的最后一种无监督学习是 association rule learning ,其目标是挖掘大量数据从中发现隐藏在属性之间的关系。比如,把关联规则应用在大型超市的销售日志数据中,也许可以发掘某种购买习惯: 购买烤肉酱和炸土豆片的人也趋向购买牛排。因此,商户可以将这些商品放在距离彼此近的地方。
Semisupervised Learning
一些算法可以处理部分打了label的训练数据,经常是大量没有label和少量具有label的数据,这种学习称作semisupervised learning.
一个很好的例子是photo service. 当我们上传大量照片后,系统能自动识别某个人出现在1,2,5图片内,而另一个人出现在3,7,9照片中,这属于无监督学习的部分(Clustering)。而我们要做的是,指出这些人是谁,同一个人只需要打一个label即可(对于长得像的人,也许需要多打一些提高准确性),系统会自动设别每张照片都有谁,从而利于照片搜索。
Most semisupervised learning algorithms are combinations of unsupervised and
supervised algorithms. For example, deep belief networks (DBNs) are based on unsupervised
components called restricted Boltzmann machines (RBMs) stacked on top of
one another. RBMs are trained sequentially in an unsupervised manner, and then the
whole system is fine-tuned using supervised learning techniques.
Reinforcement Learning(强化学习)
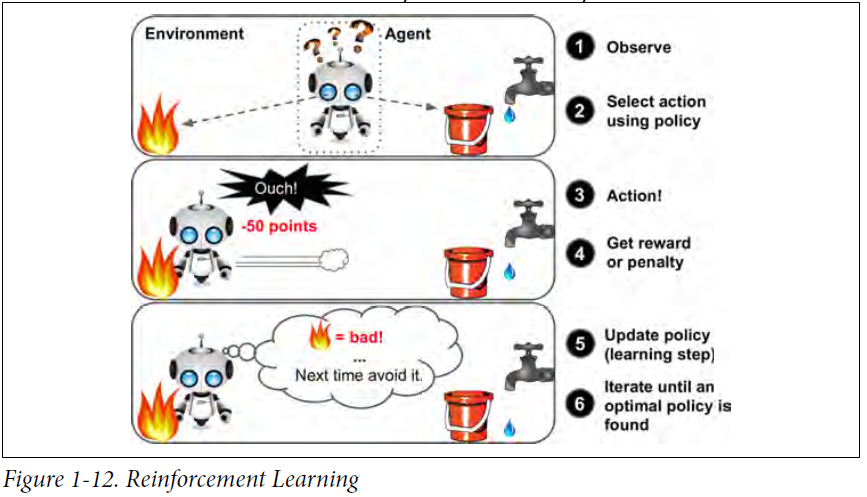
强化学习中,学习系统被称作Agent,它会通过观察环境,选择并执行相应的动作(Action),然后得到奖励(rewards)或者惩罚(penalty)。系统必须自己学习找到最好的策略,也叫作policy,从而持续获得最多的奖励。Policy定义了在特定的情形下agent该选择哪种动作。机器人实现了强化学习算法学习如何walk. DeepMind的阿尔法狗也是一个很好的例子,通过分析百万次的比赛然后和自己较量,来学习取胜的policy。和李世石比赛的时候,阿尔法狗是关掉学习功能的,它只是应用之前学到的策略罢了。
Machine Learning分类:监督/无监督学习的更多相关文章
- Machine Learning 学习笔记1 - 基本概念以及各分类
What is machine learning? 并没有广泛认可的定义来准确定义机器学习.以下定义均为译文,若以后有时间,将补充原英文...... 定义1.来自Arthur Samuel(上世纪50 ...
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 1) Introduction
最近学习了coursera上面Andrew NG的Machine learning课程,课程地址为:https://www.coursera.org/course/ml 在Introduction部分 ...
- 初识Machine Learning
What is Machine Learning 定义 Arthur Samuel:Field of study that gives computers the ability to learn w ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
- machine learning----->有监督学习和无监督学习的区别
1.有监督学习和无监督学习的区别: 1.1概述: 有监督学习是知道变量值(数据集)和结果(已知结果/函数值),但是不知道函数样式(函数表达式)的情况下通过machine learning(ML)获得正 ...
- darktrace 亮点是使用的无监督学习(贝叶斯网络、聚类、递归贝叶斯估计)发现未知威胁——使用无人监督 机器学习反而允许系统发现罕见的和以前看不见的威胁,这些威胁本身并不依赖 不完善的训练数据集。 学习正常数据,发现异常!
先说说他们的产品:企业免疫系统(基于异常发现来识别威胁) 可以看到是面向企业内部安全的! 优点整个网络拓扑的三维可视化企业威胁级别的实时全局概述智能地聚类异常泛频谱观测 - 高阶网络拓扑;特定群集,子 ...
- 【Machine Learning】监督学习、非监督学习及强化学习对比
Supervised Learning Unsupervised Learning Reinforced Learning Goal: How to apply these methods How t ...
- Unsupervised learning无监督学习
Unsupervised learning allows us to approach problems with little or no idea what our results should ...
- 【机器学习】从分类问题区别机器学习类型 与 初步介绍无监督学习算法 PAC
如果要对硬币进行分类,我们对硬币根据不同的尺寸重量来告诉机器它是多少面值的硬币 这种对应的机器学习即使监督学习,那么如果我们不告诉机器这是多少面额的硬币,只有尺寸和重量,这时候让机器进行分类,希望机器 ...
随机推荐
- XML解析方式
两种解析方式概述 dom解析 (1)是W3C组织推荐的处理XML的一种解析方式. (2)将整个XML文档使用类似树的结构保存在内存中,在对其进行操作. (3)可以方便的对XML进行增删改查的操作 (4 ...
- HTML中IMG标签总结
一.Img标签有两个重要的属性: 1.src 属性:图片的地址 2.alt 属性:图片不显示是现实的文字 二.Img标签是行级元素: img.input属于行内替换元素.height/width/ ...
- windows10上安装mysql
环境:windwos 10(1511) 64bit.mysql 5.7.14 一.下载mysql 1. 在浏览器里打开mysql的官网http://www.mysql.com/ 2. 进入页面顶部的& ...
- 初识Java——第一章 初识Java
1. 计算机程序: 为了让计算机执行某些操作或解决某个问题而编写的一系列有序指令的集合. 2. JAVA相关的技术: 1).安装和运行在本机上的桌面程序 2).通过浏览器访问的面向 ...
- TImage保存图片到Stream及从Stream中取图片
因为一个项目,不得不将图片保存到数据库中,需要的时候再从数据库中读取.初时,以为很简单,不就是一个Stream.事实上,也很简单.度娘一下,代码也很多,但,都是坑! 看一下TImage的源,Pictu ...
- 数据结构中的hash
最近接触数据结构的时候突然发现一直在使用哈希表,哈希算法.那么到底什么是哈希(hash).查找资料发现一个比较有意思的解释,在此分享一下. 人家说的很好我就直接粘过来. =============== ...
- c语言中 *p++ 和 (*p)++ 有什么区别?以及C语言运算符的优先级。整理。
*p++是指下一个地址. (*p)++是指将*p所指的数据的值加一. C编译器认为*和++是同优先级操作符,且都是从右至左结合的,所以*p++中的++只作用在p上,和*(p++)意思一样:在(*p)+ ...
- [HDU6315]Naive Operations(线段树+树状数组)
构造一个序列B[i]=-b[i],建一颗线段树,维护区间max, 每次区间加后再询问该区间最大值,如果为0就在树状数组中对应的值+1(该操作可能进行多次) 答案在树状数组中找 其实只用一颗线段树也是可 ...
- Shell环境变量与特殊变量详解
1)变量类型 1)变量可分为俩类:环境变量(全局变量),和普通变量(局部变量), 环境变量也称为全局变量,可以在创建他们的Shell及其派生出来的任意子进程Shell中使用,环境变量又可以分为自定义环 ...
- 一个java新手配置IIS服务器的血泪史
接到一个二次开发项目,听说是asp页面,带着不要怂的态度于是接下了. 好嘛按照步骤来 1.了解需求:一个公司内部积分排名类型项目,已经被多次开发,我所需要的就是新增两个页面,一个是分店赛一个是分部赛. ...