学好Python不加班系列之SCRAPY爬虫框架的使用
scrapy是一个爬虫中封装好的一个明星框架。具有高性能的持久化存储,异步的数据下载,高性能的数据解析,分布式。
对于初学者来说还是需要有一定的基础作为铺垫的学习。我将从下方的思维导图中进行逐步的解析讲述。
实验工具即环境:
笔记本:Y9000X 2020
系统:win10
Python版本:python3.8.6
pycharm版本:pycharm 2021.1.2(Professional Edition)
一、安装
下载tiwisted,此处位下载地址:http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
下载好后打开终端进行安装scrapy的必要模块
安装tiwisted,pip install tiwisted-xxxx
安装pywin32:pip install pywin32
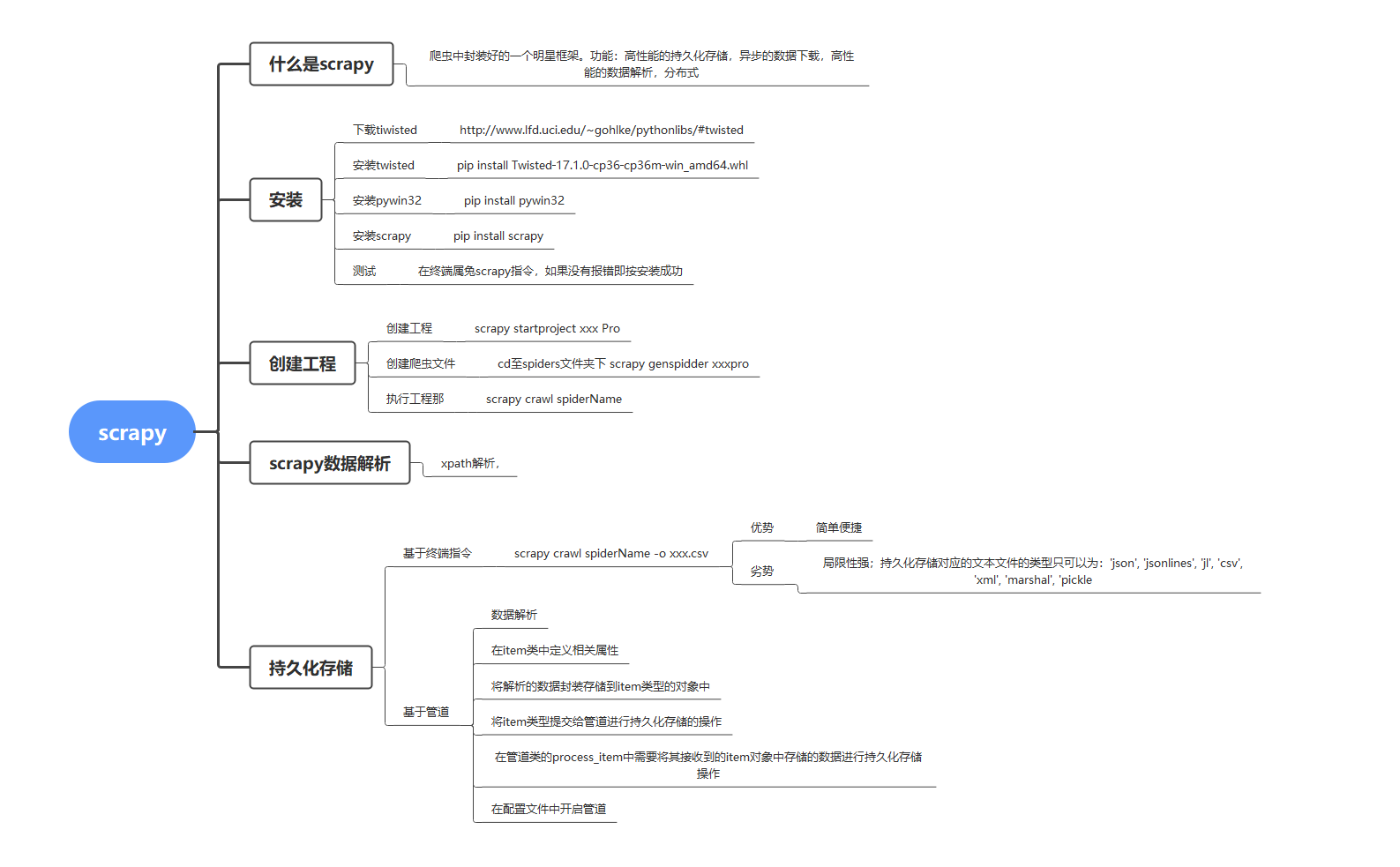
安装scrapy:pip install scrapy
安装完成后在终端输入scrapy如果没有报错即安装成功。
二、创建scrapy的工程
在pycharm中创建好的项目中的中终端输入
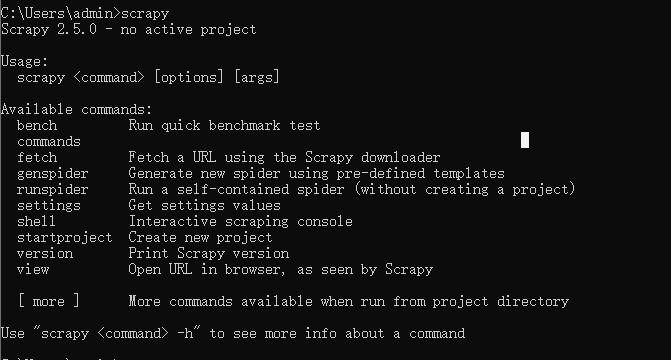
scrapy startproject SDFDQPRO

检查下项目目录即可发现多出了如下的工程目录
三、创建一个爬虫目录
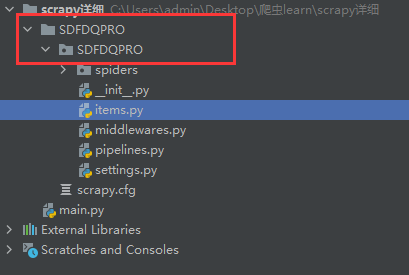
在终端找到之前所创建的工程目录,在此目录下输入scrapy genspider sdfdq_cj http://www.csrc.gov.cn/pub/shandong/
后方网站为中国证券监督管理委员会山东监管局。

运行后可发现工程目录中多出一个名为sdfdq_cj.py的爬虫文件。
进入到爬虫文件中可以看到如下代码
import scrapy
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/'] # 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response):
pass
接下来对网站解析选取需要获取的内容
四、数据解析
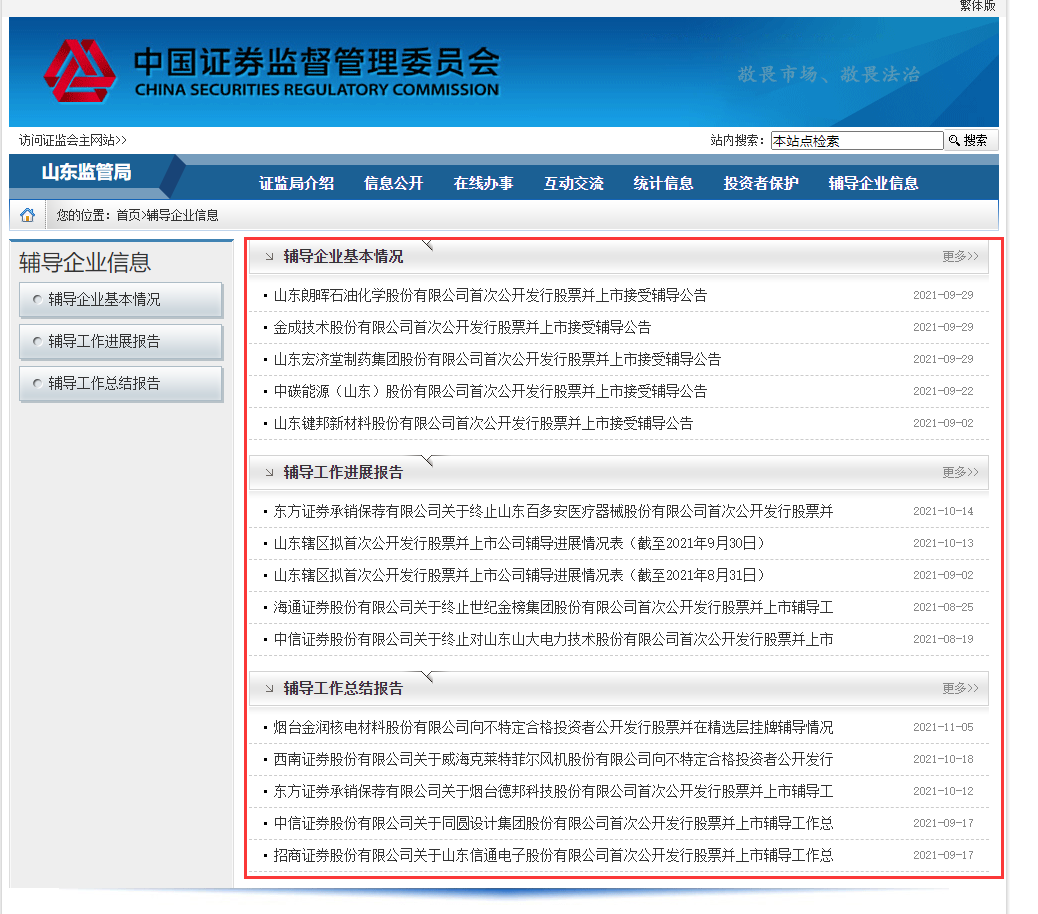
通过对网站的查看可以看出我们需要的是辅导期中的企业基本情况、工作进展报告、工作总结总的标题,日期以及链接。
scrapy对网站的解析沿用了xpath的解析方式。
import scrapy
class SdfdqCjSpider(scrapy.Spider):
name = 'sdfdq_cj'
# 表示被允许的url
# allowed_domains = ['http://www.csrc.gov.cn/pub/shandong/']
# 起始url列表:该列表中存放的url会被scrapy自动进行请求的发送
start_urls = ['http://www.csrc.gov.cn/pub/shandong/sdfdqyxx/'] # 用作于数据解析:response参数表示的就是请求成功后对应的响应对象
def parse(self, response): li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
print('title',title)
print('url',url)
print('date',date)
对网站的内容解析后运行scrapy 终端输入 scrapy crawl sdfdq_cj 注意:此语句的运行目录

可以看到我们想获取的内容:
内容获取到我们必须要将其持久化存储才有意义:
五、scrapy的持久化存储
1)基于指令的持久化存储:
要求:只可以将parse的方法返回值存储到本地的文本文件中
def parse(self, response):
# 创建一个列表接收获取的数据
all_data = []
li_list = response.xpath('//div[@class="zi_er_right"]//div[@class="fl_list"]//li')
for li in li_list:
# xpath返回的是列表,但是列元素一定是Selector类型的对象
# extract可以将Selector对象中的data参数存储的字符串提取出来
# 列表调用了extract之后则表示将列表中每一个data参数存储的字符串提取出来
title = li.xpath('./a//text()')[0].extract()
date = li.xpath('./span/text()')[0].extract()
url = 'http://www.csrc.gov.cn/pub/shandong/sdfdqyxx'+li.xpath('./a/@href').extract_first()
# 基于终端指令的持久化存储操作
dic = {
'title':title,
'url':url,
'date':date
}
all_data.append(dic)
return all_data
接下来在终端中输入 scrapy crawl sdfdq_cj -o ./sdfdq.csv
将获取的文本内容存储到对应路径下的sdfdq.csv文本文件中

2)基于管道的持久化存储
明天更。。。。。。。。。
学好Python不加班系列之SCRAPY爬虫框架的使用的更多相关文章
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python爬虫教程-31-创建 Scrapy 爬虫框架项目
本篇是介绍在 Anaconda 环境下,创建 Scrapy 爬虫框架项目的步骤,且介绍比较详细 Python爬虫教程-31-创建 Scrapy 爬虫框架项目 首先说一下,本篇是在 Anaconda 环 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy爬虫框架(实战篇)【Scrapy框架对接Splash抓取javaScript动态渲染页面】
(1).前言 动态页面:HTML文档中的部分是由客户端运行JS脚本生成的,即服务器生成部分HTML文档内容,其余的再由客户端生成 静态页面:整个HTML文档是在服务器端生成的,即服务器生成好了,再发送 ...
- Scrapy爬虫框架与常用命令
07.08自我总结 一.Scrapy爬虫框架 大体框架 2个桥梁 二.常用命令 全局命令 startproject 语法:scrapy startproject <project_name> ...
- python3.7.1安装Scrapy爬虫框架
python3.7.1安装Scrapy爬虫框架 环境:win7(64位), Python3.7.1(64位) 一.安装pyhthon 详见Python环境搭建:http://www.runoob.co ...
- 安装scrapy 爬虫框架
安装scrapy 爬虫框架 个人根据学习需要,在Windows搭建scrapy爬虫框架,搭建过程种遇到个别问题,共享出来作为记录. 1.安装python 2.7 1.1下载 下载地址 1.2配置环境变 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影
前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大家讲解一个完整爬虫的流程. 工具和环境 语言:python 2 ...
- Scrapy 爬虫框架学习笔记(未完,持续更新)
Scrapy 爬虫框架 Scrapy 是一个用 Python 写的 Crawler Framework .它使用 Twisted 这个异步网络库来处理网络通信. Scrapy 框架的主要架构 根据它官 ...
随机推荐
- centos7.5 SVN 搭建
第一步:通过yum命令安装svnserve,命令如下: >yum -y install subversion 此命令会全自动安装svn服务器相关服务和依赖,安装完成会自动停止命令运行 若需查看s ...
- python学习笔记(五)-文件操作2
一.文件修改 现有文件file.txt,内容如下:二十四节气歌春雨惊春清谷天,夏满芒夏暑相连.秋处露秋寒霜降,冬雪雪冬小大寒.上半年逢六廿一,下半年逢八廿三.每月两节日期定,最多相差一二天.要求:将文 ...
- Maven项目创建与配置(二)
项目配置 1:添加Source Folder 右击项目>NEW>Source Folder maven规定必须创建一下几个Source Folder src/main/resources ...
- Fiddler修改抓包请求
hi,说到fiddler的用途,第一时间想到抓包,不过还有一个功能是:支持修改请求. 那么问题来了,怎么做呢?很简单,先定下我们需要修改哪个请求. 这里用F12跟fiddler做演示. 首先我们在F1 ...
- Docker小白到实战之Docker网络简单了解一下
前言 现在对于Docker容器的隔离性都有所了解了,但对容器IP地址的分配.容器间的访问等还是有点小疑问,如果容器的IP由于新启动导致变动,那又怎么才能保证原有业务不会被影响,这就和网络有挂钩了,接下 ...
- UE4蓝图AI角色制作(三)
接上一节 6. 寻路网格体代理 通过允许配置多个"代理",虚幻引擎使得用户能够轻松为大小各异的AI创建寻路网格体.首先,选中世界大纲视图中的"RecastNavMesh& ...
- MacOS下Java与JDK关系与相关路径
MacOS下Java与JDK关系与相关路径 macOS下的Java与JDK的路径曾经困扰过我一段时间,今天稍有些忘记,故记下笔记,整理一下.Java与JDK的关系不在本文笔记之内,Javaer常识. ...
- Azure Devops实践(5)- 构建springboot项目打包docker镜像及容器化部署
使用Azure Devops构建java springboot项目,创建镜像并容器化部署 1.创建一个springboot项目,我用现有的项目 目录结构如下,使用provider项目 在根目录下添加D ...
- Schematics Tools(Schematics 工具)
Schematics工具 # Process: 创建逻辑示意图 arcpy.CreateDiagram_schematics("", "", "&qu ...
- v72.01 鸿蒙内核源码分析(Shell解析) | 应用窥伺内核的窗口 | 百篇博客分析OpenHarmony源码
子曰:"苟正其身矣,于从政乎何有?不能正其身,如正人何?" <论语>:子路篇 百篇博客系列篇.本篇为: v72.xx 鸿蒙内核源码分析(Shell解析篇) | 应用窥视 ...