mapreduce编程--(准备篇)
mapreduce编程准备
学习mapreduce编程之前需要做一些概念性的了解,这是做的一些课程学习笔记,以便以后时不时的翻出来学习下,之前看过一篇文章大神们都是时不时的翻出基础知识复习下,我也做点笔记吧。
1.mapreduce定义
- 源于Google的MapReduce论文(如果想更深入的学习,可以搜一下)
√ 发表于2004年12月
√ Hadoop Mapreduce是Google MapReduce克隆版。
- MapReduce特点
√ 易于编程
√ 良好的扩展性
√ 高容错性
√ 适合PB级以上海量数据的离线处理
2.应用场景和不擅长之处
- 常见mapreduce应用场景
简单的数据统计,比如网站的pv,uv统计
搜索引擎建索引
海量数据查找
复杂数据分析算法实现
聚类算法
分类算法
推荐算法
图算法
- 不擅长的地方
实时计算:
像mysql一样,在毫秒级或者秒级返回结果。
流式计算:
MapReduce的输入数据集是静态的,不能动态变化。
mapreduce自身的设计特点决定了数据源必须是静态的。
DAG计算:
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。
3.mapreduce编程模型基本过程
实例还是用最常见的入门级WordCount:
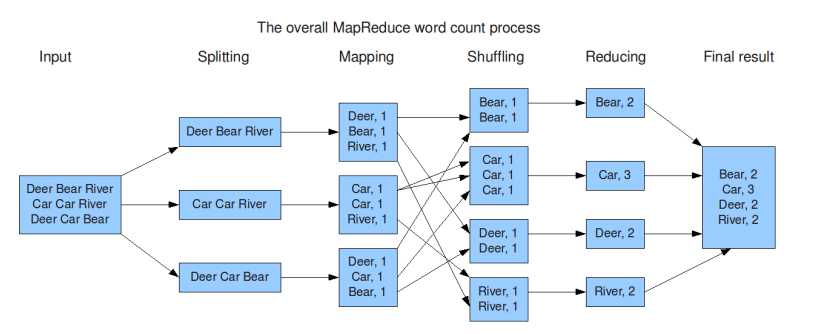
整体过程:
- 先将数据切分成一个个小的分片,每个分片叫一个splitting 交个map去执行。
- 进行简单的拆分 统计相关词的个数 比如(Deer 1 Bear 1)。
- shuffling并sort 就是进行排序后将相同的k发送到同一个节点上,统计分析。
- reduce 就是进行最后的累加输出结果。
MapReduce编程模型:
- input:一系列的key/value。
这个是mapreduce框架解析的,是通过inputformat模块进行处理转换发送给map函数的,inputformat可以自己开发。
- 用户提供两个函数实现:
map(k,v) -> k1,v1
就是将输入的k 和v进行计算输出为新的k1和v1 比如常见的wordcount实例,就是将输入的(k行号)和值(v单词) 统计分析后输出为k1(单词) ,v1(出现的次数)
reduce(k1,list[v1])->k2,v2
这个地方需要详细理解一下,因为在输入到reduce之前 mapreduce框架已经帮我们做了一些工作,就是上面提到的shuffling和sort已经将相同的值做了汇总 所以输入的k1和v1变成了k1(单词) v1(一组单词的数量[1,2,3,4]) 经过reduce计算后输出为k2(单词)和v2(单词总数)。
- (k1,v1)是中间key/value结果对。
- output:一系列(k2,v2)对。
示例图:

4.mapreduce编程模型
Mapreuce将作业的整个运行过程分为两个阶段:map阶段和reduce阶段
- Map阶段由一定数量的map task组成
√ 输入数据格式解析:inputFormat :去负责取分片并解析成map的输入格式k,v
√ 输入数据处理:Mapper :根据业务逻辑处理k和v
√ 数据分组:Partitioner :就是把相同的k分配给相同的reduce 一般用hash算法处理路由策略 (这个地方可以自己定义)需要学习。
- Reduce阶段由一定数量的reduceTask组成
√ 数据远程拷贝: 就是将map处理后的结果远程拷贝到相关的处理集群上。 ----需要理解下
√ 数据按照key排序 :就是shuffling和sort阶段。
√ 数据处理:reducer :根据业务逻辑处理k和v。
√ 数据输出格式:outputFormat :结果输出可以输出到hbase 或者hdfs (这个也可以自定义)。
内部逻辑:
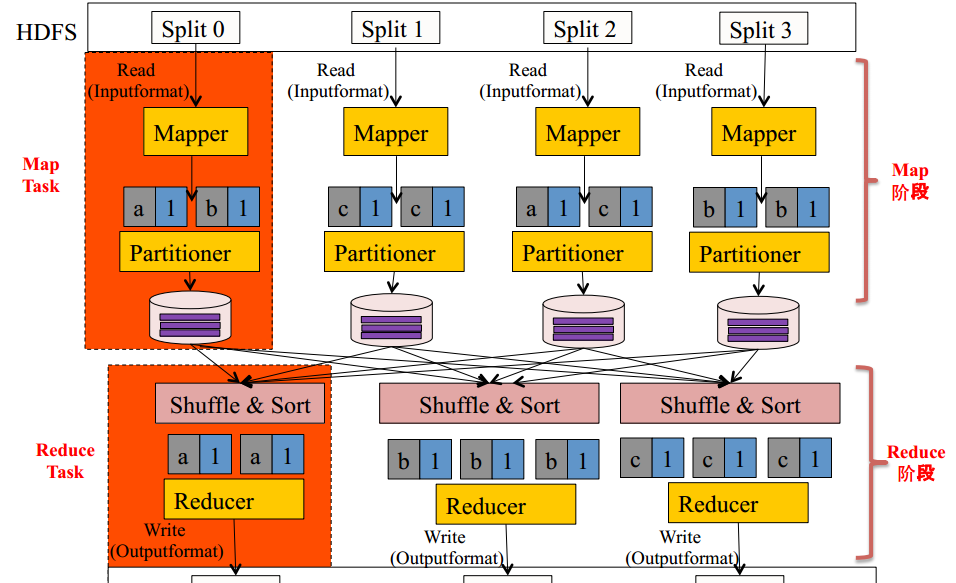
MapReduce编程模型-InputFormat
- 文件分片(inputSplit)方法
√ 处理跨行问题。
- 将分片数据解析成key/value对
√ 默认实现是TextInputFormat。
- TextInputFormat
√ key是行在文件中的偏移量,value是行内容。
√ 若行被截断,则读取下一个block的前几个字符。
MapReduce编程模型-Split与block
- Block
√ HDFS中最小的数据存储单元。
√ 默认是128MB。
- spilt
√ MapReduce中最小的计算单元。
√ 默认与block一一对应
- block与split
√ split与block的对应关系是任意的,可以自己控制---需要注意的是不要看到默认一一对应就觉得是都是这样,有可能一个split对应好结果block。
MapReduce编程模型-combiner
- combiner可以看成是一个local reducer
√ 合并相同key对应的value值。
√ 通常与reduce逻辑一样。
- 好处:
√ 可以减少map task输出的数据量(减小磁盘io)。
√ 可以reduce-map网络传输的数据量(减小网络io)。
- 如何正确使用:
√ 结果叠加的可以使用。
√ sum可以使用 但是求平局值的时候不能使用。
MapReduce编程模型-patitioner
- patitioner决定了MapTask 输出的每条数据交给哪个Reduce Task处理 ----这个需要查询一下 不是自己远程拷贝么,怎么能制定了
- 默认实现时hash(key) mod R
√ R是reduce Task数目。
√ 允许用户自定义。
- 很多情况下需要自定义Partitioner
√ 比如:hash(hostname(URL)) mod R 确保相同域名的网页交给同一个Reduce Task处理。
mapreduce编程--(准备篇)的更多相关文章
- hadoop2.2编程:使用MapReduce编程实例(转)
原文链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 从网上搜到的一篇hadoop的编程实例,对于初学者真是帮助太大 ...
- [转]Hadoop集群_WordCount运行详解--MapReduce编程模型
Hadoop集群_WordCount运行详解--MapReduce编程模型 下面这篇文章写得非常好,有利于初学mapreduce的入门 http://www.nosqldb.cn/1369099810 ...
- MapReduce编程模型及其在Hadoop上的实现
转自:https://www.zybuluo.com/frank-shaw/note/206604 MapReduce基本过程 关于MapReduce中数据流的传输过程,下图是一个经典演示: 关于上 ...
- MapReduce编程实战之“调试”和"调优"
本篇内容 在上一篇的"初识"环节,我们已经在本地和Hadoop集群中,成功的执行了几个MapReduce程序,对MapReduce编程,已经有了最初的理解. 在本篇文章中,我们对M ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本3(九)
不多说,直接上干货! 下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 下面是版本2. Hadoop MapReduce编程 API入门系列之挖掘气象数 ...
- Hadoop MapReduce编程 API入门系列之挖掘气象数据版本2(十)
下面,是版本1. Hadoop MapReduce编程 API入门系列之挖掘气象数据版本1(一) 这篇博文,包括了,实际生产开发非常重要的,单元测试和调试代码.这里不多赘述,直接送上代码. MRUni ...
- 批处理引擎MapReduce编程模型
批处理引擎MapReduce编程模型 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. MapReduce是一个经典的分布式批处理计算引擎,被广泛应用于搜索引擎索引构建,大规模数据处理 ...
- Hadoop MapReduce编程 API入门系列之压缩和计数器(三十)
不多说,直接上代码. Hadoop MapReduce编程 API入门系列之小文件合并(二十九) 生成的结果,作为输入源. 代码 package zhouls.bigdata.myMapReduce. ...
- [Hadoop入门] - 1 Ubuntu系统 Hadoop介绍 MapReduce编程思想
Ubuntu系统 (我用到版本号是140.4) ubuntu系统是一个以桌面应用为主的Linux操作系统,Ubuntu基于Debian发行版和GNOME桌面环境.Ubuntu的目标在于为一般用户提供一 ...
随机推荐
- jqgrid的排序问题
今天是本人解决的一个小bug 所以写的粗略些. 问题是这样的ORDER BY a.$sidx $sord 当时本人排序时候没用jqgrid的默认排序(可能今天这个大家看不懂,很抱歉啊各位,今天主要 ...
- Android中的Manifest.permission(应用权限)整理
ACCESS_CHECKIN_PROPERTIES 允许读/写登记数据库(checkin database),中的“properties”表,用来改变他的值来上传东西. 这个权限第三方应用无法使用. ...
- ubuntu16.04主题美化和软件推荐(转载)
从这里转载!转载!转载! http://blog.csdn.net/terence1212/article/details/52270210
- 标C编程笔记day05 函数声明、文件读写、联合类型、枚举类型
函数声明: 1.隐式声明:在没有声明的情况下,系统可依据參数类型推断去调用函数(有可能出错) 2.显式声明:声明在被调用之前.如:double add(double,double); ...
- Django - admin后台、auth权限
admin后台 一.创建一个管理员用户 (1).设置时区.语言(可选步骤) 打开settings.py,改成下面那样 LANGUAGE_CODE = 'zh-Hans' TIME_ZONE = 'As ...
- 【BZOJ3261】最大异或和 Trie树+贪心
[BZOJ3261]最大异或和 Description 给定一个非负整数序列 {a},初始长度为 N. 有 M个操作,有以下两种操作类型:1 .A x:添加操作,表示在序列末尾添加一个 ...
- location.assign 与 location.replace的区别
window.location.assign(url) : 加载 URL 指定的新的 HTML 文档. 就相当于一个链接,跳转到指定的url,当前页面会转为新页面内容,可以点击后退返回上一个页面. w ...
- Java——BeanUtils基本用法
为了操作JavaBean的属性,sun公司自己写了一套内省的api(在Java.beans.*)中,但是我们发现操作起来还是比较复杂的,所以apache公司就自己写了一套api替代了它,大大方便了开发 ...
- HTTP协议包分析(小马上传大马)
最近工作内容是分析防火墙日志,看日志是正确,本地实验小马上传大马 抓取http包如下.可以在分析过程中进行借鉴. 该http请求的行为是通过小马,在小马的当前目录创建一个dama.php的文件,文件 ...
- 将Android studio的工程导入到eclipse中
自从Android Studio(后面称AS)推出后,越来越多的项目都使用AS开发. AS往eclipse迁移的方法: 其实很简单,代码都是一样的,从AS工程中找到与Eclipse工程对应的文件,放到 ...