MySQL中IN子查询会导致无法使用索引
今天看到一个博客园的一篇关于MySQL的IN子查询优化的案例,
一开始感觉有点半信半疑(如果是换做在SQL Server中,这种情况是绝对不可能的,后面会做一个简单的测试。)
随后动手按照他说的做了一个表来测试验证,发现MySQL的IN子查询做的不好,确实会导致无法使用索引的情况(IN子查询无法使用所以,场景是MySQL,截止的版本是5.7.18)
MySQL的测试环境
测试表如下
create table test_table2
(
id int auto_increment primary key,
pay_id int,
pay_time datetime,
other_col varchar(100)
)
建一个存储过程插入测试数据,测试数据的特点是pay_id可重复,这里在存储过程处理成,循环插入300W条数据的过程中,每隔100条数据插入一条重复的pay_id,时间字段在一定范围内随机
CREATE DEFINER=`root`@`%` PROCEDURE `test_insert`(IN `loopcount` INT)
LANGUAGE SQL
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT ''
BEGIN declare cnt int;
set cnt = 0;
while cnt< loopcount do
insert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());
if (cnt mod 100 = 0) then
insert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());
end if;
set cnt = cnt + 1;
end while;
END
执行 call test_insert(3000000); 插入303000行数据

两种子查询的写法
查询大概的意思是查询某个时间段之内的业务Id大于1的数据,于是就出现两种写法。
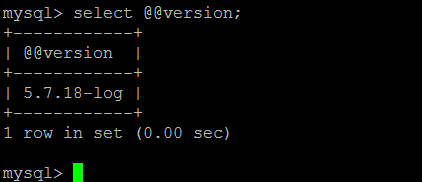
第一种写法如下:IN子查询中是某段时间内业务统计行数大于1的业务Id,外层按照IN子查询的结果进行查询,业务Id的列pay_id上有索引,逻辑也比较简单,
这种写法,在数据量大的时候确实效率比较低,用不到索引
select * from test_table2 force index(idx_pay_id)
where pay_id in (
select pay_id from test_table2
where pay_time>="2016-06-01 00:00:00"
AND pay_time<="2017-07-03 12:59:59"
group by pay_id
having count(pay_id) > 1
);
执行结果:2.23秒
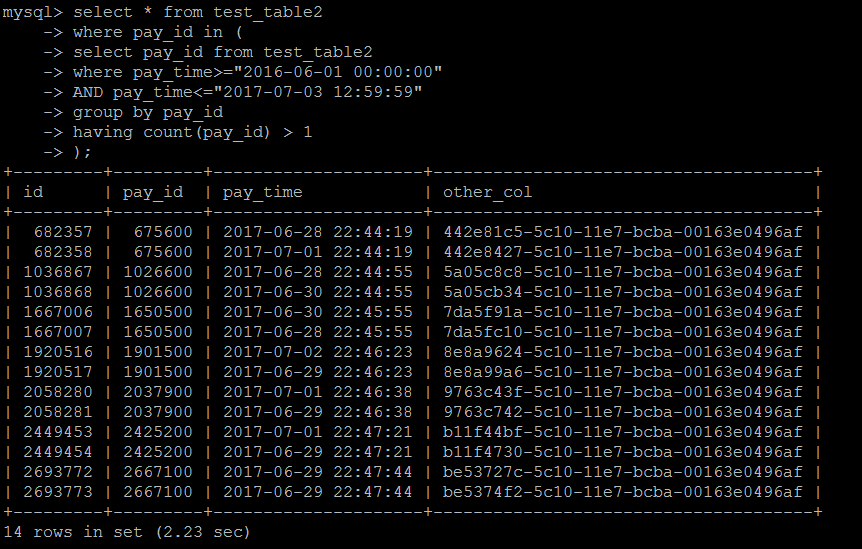
第二种写法,与子查询进行join关联,这种写法相当于上面的IN子查询写法,下面测试发现,效率确实有不少的提高
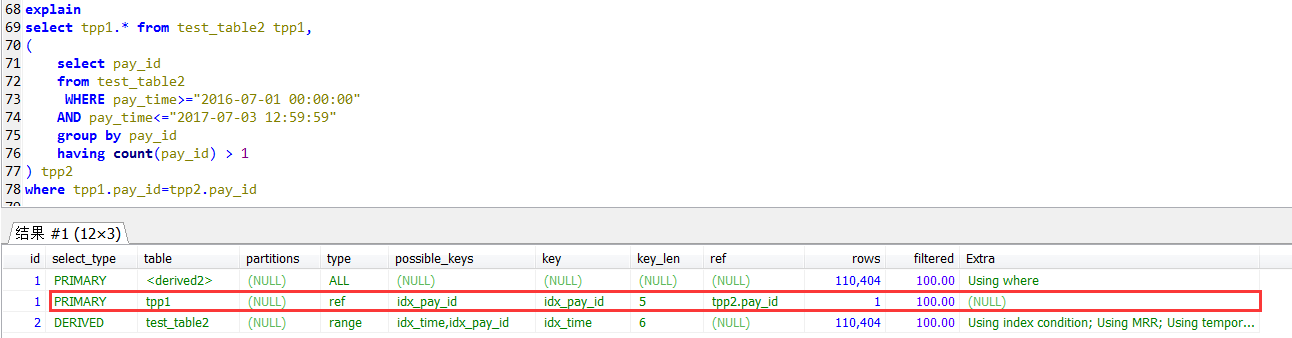
select tpp1.* from test_table2 tpp1,
(
select pay_id
from test_table2
WHERE pay_time>="2016-07-01 00:00:00"
AND pay_time<="2017-07-03 12:59:59"
group by pay_id
having count(pay_id) > 1
) tpp2
where tpp1.pay_id=tpp2.pay_id
执行结果:0.48秒
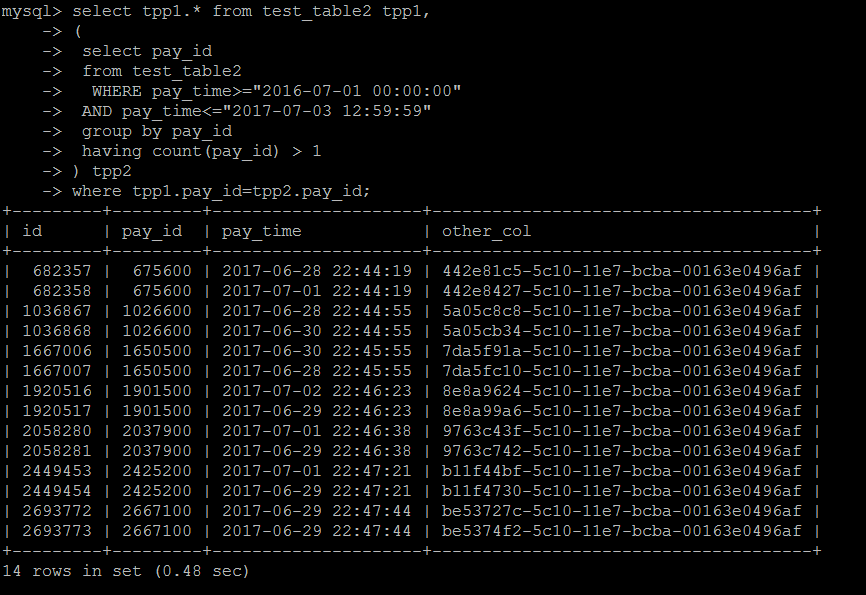
In子查询的执行计划,发现外层查询是一个全表扫描的方式,没有用到pay_id上的索引
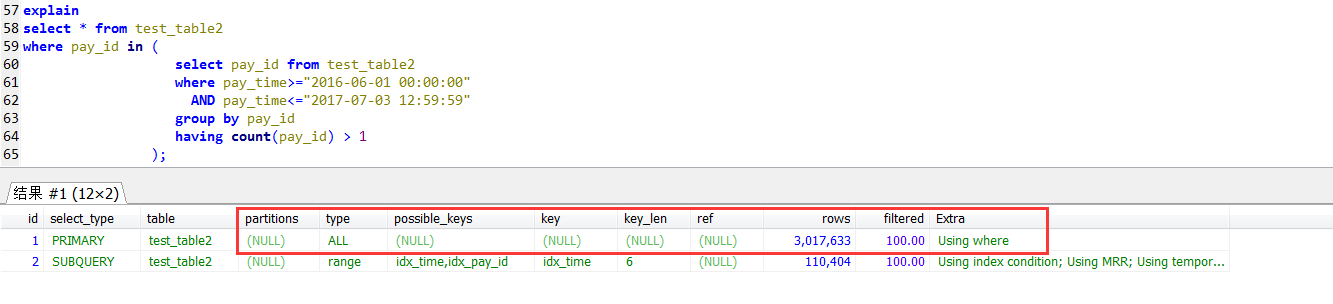
join自查的执行计划,外层(tpp1别名的查询)是用到pay_id上的索引的。
后面想对第一种查询方式使用强制索引,虽然是不报错的,但是发现根本没用

如果子查询是直接的值,则是可以正常使用索引的。

可见MySQL对IN子查询的支持,做的确实不怎么样。
另外:加一个使用临时表的情况,虽然比不少join方式查询的,但是也比直接使用IN子查询效率要高,这种情况下,也是可以使用到索引的,不过这种简单的情况,是没有必要使用临时表的。

下面是类似案例在sqlserver 2014中的测试,几乎完全一样的测试表结构和数量,可见这种情况下,两种写法,在SQL Server中可以认为是完全一样的(执行计划+效率),这一点SQL Server要比MySQL强不少
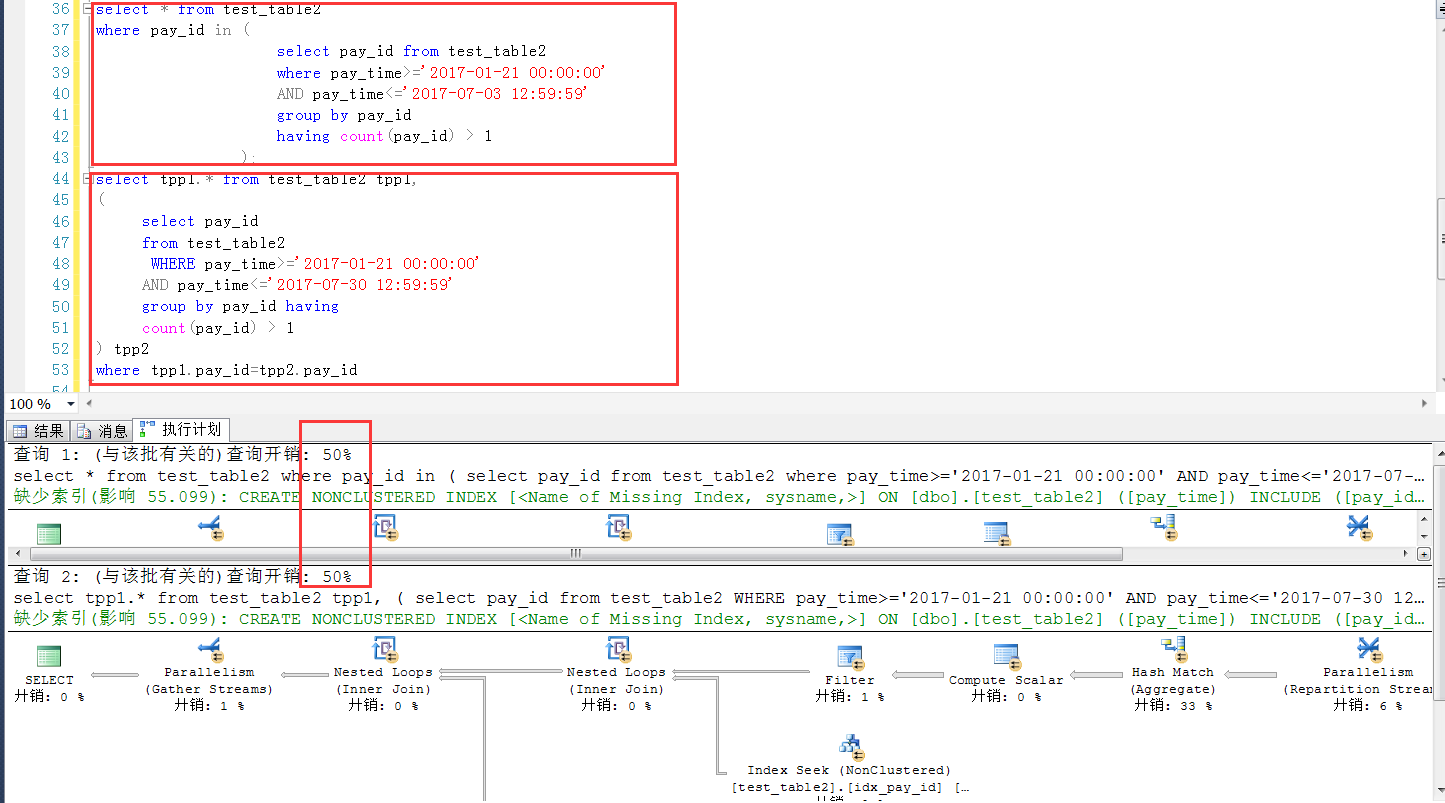
下面是sqlserver中的测试环境脚本。
create table test_table2
(
id int identity(1,1) primary key,
pay_id int,
pay_time datetime,
other_col varchar(100)
) begin tran
declare @i int = 0
while @i<300000
begin
insert into test_table2 values (@i,getdate()-rand()*300,newid());
if(@i%1000=0)
begin
insert into test_table2 values (@i,getdate()-rand()*300,newid());
end
set @i = @i + 1
end
COMMIT
GO create index idx_pay_id on test_table2(pay_id);
create index idx_time on test_table2(pay_time);
GO select * from test_table2
where pay_id in (
select pay_id from test_table2
where pay_time>='2017-01-21 00:00:00'
AND pay_time<='2017-07-03 12:59:59'
group by pay_id
having count(pay_id) > 1
); select tpp1.* from test_table2 tpp1,
(
select pay_id
from test_table2
WHERE pay_time>='2017-01-21 00:00:00'
AND pay_time<='2017-07-30 12:59:59'
group by pay_id having
count(pay_id) > 1
) tpp2
where tpp1.pay_id=tpp2.pay_id
总结:在MySQL数据中,截止5.7.18版本,对IN子查询,仍要慎用
MySQL中IN子查询会导致无法使用索引的更多相关文章
- MySQL中in子查询会导致无法使用索引问题(转)
MySQL的测试环境 测试表如下 create table test_table2 ( id int auto_increment primary key, pay_id int, pay_time ...
- 详细讲述MySQL中的子查询操作 (来自脚本之家)
继续做以下的前期准备工作: 新建一个测试数据库TestDB: ? 1 create database TestDB; 创建测试表table1和table2: ? 1 2 3 4 5 6 7 8 9 1 ...
- 在MySQL中使用子查询和标量子查询的基本用法
一.MySQL 子查询 子查询是将一个 SELECT 语句的查询结果作为中间结果,供另一个 SQL 语句调用.MySQL 支持 SQL 标准要求的所有子查询格式和操作,也扩展了特有的几种特性.子查询没 ...
- 在MySQL中使用子查询
子查询作为数据源 子查询生成的结果集包含行.列数据,因而非常适合将它与表一起包含在from子句的子查询里.例: SELECT d.dept_id, d.name, e_cnt.how_many num ...
- mysql 中 delete 子查询的限制
1 DELETE FROM tablename 中的 tablename 不能起别名 delete ; [Err] - You have an error in your SQL syntax; 2 ...
- mysql 在update中实现子查询的方式
当使用mysql条件更新时--最先让人想到的写法 UPDATE buyer SET is_seller=1 WHERE uid IN (SELECT uid FROM seller) 此语句是错误的, ...
- MySQL里面的子查询
一.子查询定义 定义: 子查询允许把一个查询嵌套在另一个查询当中. 子查询,又叫内部查询,相对于内部查询,包含内部查询的就称为外部查询. 子查询可以包含普通select可以包括的任何子句,比如:dis ...
- mysql中的模糊查询
转载自:http://www.letuknowit.com/archives/90/ MySQL中实现模糊查询有2种方式:一是用LIKE/NOT LIKE,二是用REGEXP/NOT REGEXP(或 ...
- SQL Fundamentals: 子查询 || WHERE,HAVING,FROM,SELECT子句中使用子查询,WITH子句
SQL Fundamentals || Oracle SQL语言 子查询(基础) 1.认识子查询 2.WHERE子句中使用子查询 3.在HAVING子句中使用子查询 4.在FROM子句中使用子查询 5 ...
随机推荐
- React-Native新列表组件FlatList和SectionList学习 | | 联动列表实现
React-Native在0.43推出了两款新的列表组件:FlatList(高性能的简单列表组件)和SectionList(高性能的分组列表组件). 从官方上它们都支持常用的以下功能: 完全跨平台. ...
- Windows 应用商店无法下载---启动更新
今天想在应用商店下载东西,但是以直没成功,查看原因结果是因为我的Windows自动更新关了. 百度,如何打开自动更新,要打开本地组策略编辑器,但是我是Windows家庭版,,,没有这个东西,, 最后, ...
- 桥接模式-pattern系列
git链接 桥接模式 桥梁模式的用意是"将抽象化(Abstraction)与实现化(Implementation)脱耦,使得二者可以独立地变化".这句话有三个关键词,也就是抽象化. ...
- cocos2dx开发之util类&方法——取当前系统时间
返回time_t,即从1970年1月1日至今的秒数 time_t getSysTime(){ time_t currentTime = time(NULL); return currentTime; ...
- XXS level10
(1)进入第十关发现无突破口,尝试从url中的keyword入手,也行不通,但可以从页面源代码看到有三个参数是隐藏的 (2)查看PHP源代码 <?php ini_set("displa ...
- RESTful Loads
RESTful 一种软件架构风格.设计风格,而不是标准,只是提供了一组设计原则和约束条件.它主要用于客户端和服务器交互类的软件.基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制. 概述 ...
- 19/03/17Python笔记
一.判断元素是否为数字 ".isdigit() #判断123是不是数字,是的话输出True,不是输出False 二.标志位 需要死循环时,不一定用 while True 还可以用 while ...
- PythonStudy——内存管理机制 Memory management mechanism
一.变量与对象 关系图如下: 1.变量:通过变量指针引用对象 变量指针指向具体对象的内存空间,取对象的值. 2.对象:类型已知,每个对象都包含一个头部信息(头部信息:类型标识符和引用计数器) 注意: ...
- 查看linux系统CPU及内存配置
总核数 = 物理CPU个数 X 每颗物理CPU的核数 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 查看物理CPU个数 cat /proc/cpuinfo| grep & ...
- Redis使用规范
突出强调部分 [强制]key名不要包含特殊字符,如空格.换行.单双引号以及其他转义字符 [强制]拒绝bigkey(防止网卡流量.慢查询) [强制]控制key的生命周期,redis不是垃圾桶 [强制]技 ...