时间复杂度O(n^2)和O(nlog n)差距有多大?
0. 时间复杂度
接触到算法的小伙伴们都会知道时间复杂度(Time Complexity)的概念,这里先放出(渐进)时间复杂度的定义:
假设问题规模是\(n\),算法中基本操作重复执行的次数是\(n\)的某个函数,用\(T(n)\)表示,若有某个辅助函数\(f(n)\),使得
\]
其中\(c\)为不等于零的常数,则称\(f(n)\)是\(T(n)\)的同数量级函数。记作\(T(n)=O(f(n))\),称\(O(f(n))\) 为算法的渐进时间复杂度,简称时间复杂度。
常见的时间复杂度有(表格越靠后表示越不理想):
| 复杂度 | 名称 |
|---|---|
| \(O(1)\) | 常数阶 |
| \(O(\log n)\) | 对数阶 |
| \(O(n)\) | 线性阶 |
| \(O(n\log n)\) | 线性对数阶 |
| \(O(n^2)\) | 平方阶 |
| \(O(n^3)\) | 立方阶 |
| \(O(n^k)\) | \(k\)次方阶(\(k>3\)且\(k\in Z\)) |
| \(O(2^n)\) | 指数阶 |
例如,我们熟悉的插入排序(Insertion Sort)算法的时间复杂度是\(O(n^2)\),而合并排序(Merge Sort)算法的时间复杂度是\(O(n\log n)\)
那么这些复杂度之间的差距是怎么样的呢?有些小伙伴会疑问,自己写的算法虽然是高复杂度但是也用的好好的,为什么要纠结于这个概念呢?
我们不妨来探索一下今天的问题:\(O(n^2)\)和\(O(n\log n)\)差距有多大?
1. \(O(n^2)\)和\(O(n\log n)\)差距有多大?
我们知道,插入排序(Insertion Sort)算法的时间复杂度是\(O(n^2)\),而合并排序(Merge Sort)算法的时间复杂度是\(O(n\log n)\),即当排序\(n\)个对象时,插入排序算法需要用时大约\(c_1n^2\),而合并排序算法需要用时大约\(c_2n\log{n}\),其中\(c_1\)和\(c_2\)都是正常数且与\(n\)无关,且往往\(c_1<c_2\)。
稍微利用初等数学的知识,可以知道,对于任何\(n>=2\),比较约\(c_1n^2\)和\(c_2n\log{n}\)即比较\(c_1n\)和\(c_2\log{n}\)。由于我们已知
\]
以及
\]
想要比较这两个值的大小,直观的看法就是比较两个不等式谁的差别“更多”。可以证明,当无论\(c_1\)和\(c_2\)差别多么显著,总存在充分大的\(N\)使得当\(n>N\)时,\(c_1n>c_2\log{n}\)。
在Introduction to Algorithms中,作者举了一个很有趣的例子:
假设针对同一排序问题,用一台很快的电脑A运行插入排序,用一台很慢的电脑B运行合并排序,问题规模\(n=10^7\):
两台电脑的差别如下,为了使A比B优势显著,作者假设电脑A性能比B强1000倍,并且B运行的代码更低效、且编译器更差(导致需要运行更多的指令):
| 电脑A | 电脑B | |
|---|---|---|
| 每秒运行指令数 | \(10^{10}\) | \(10^7\) |
| 需要运行的指令总数 | \(2n^2\) | \(50n\log n\) |
这样,A完成任务需要:
\]
而B完成任务需要:
\]
可以看到,在这样的大规模的问题下,即便B计算机与A差距巨大,最终也只用了20分钟左右就完成排序,而A却需要5.5小时来完成。时间复杂度的差距可见一斑。
3. 总结
算法时间复杂度的量级差异,也许在小规模的问题下,表现差别不大。但是时间复杂度高的算法,对问题规模的变化更加敏感,因而当问题的规模变得很大的时候,靠拥有高阶时间复杂度的算法来求解并不可靠!
(更新)我从网络上找到了一个直观的各个阶的复杂度的对比,大家不妨参考一下:
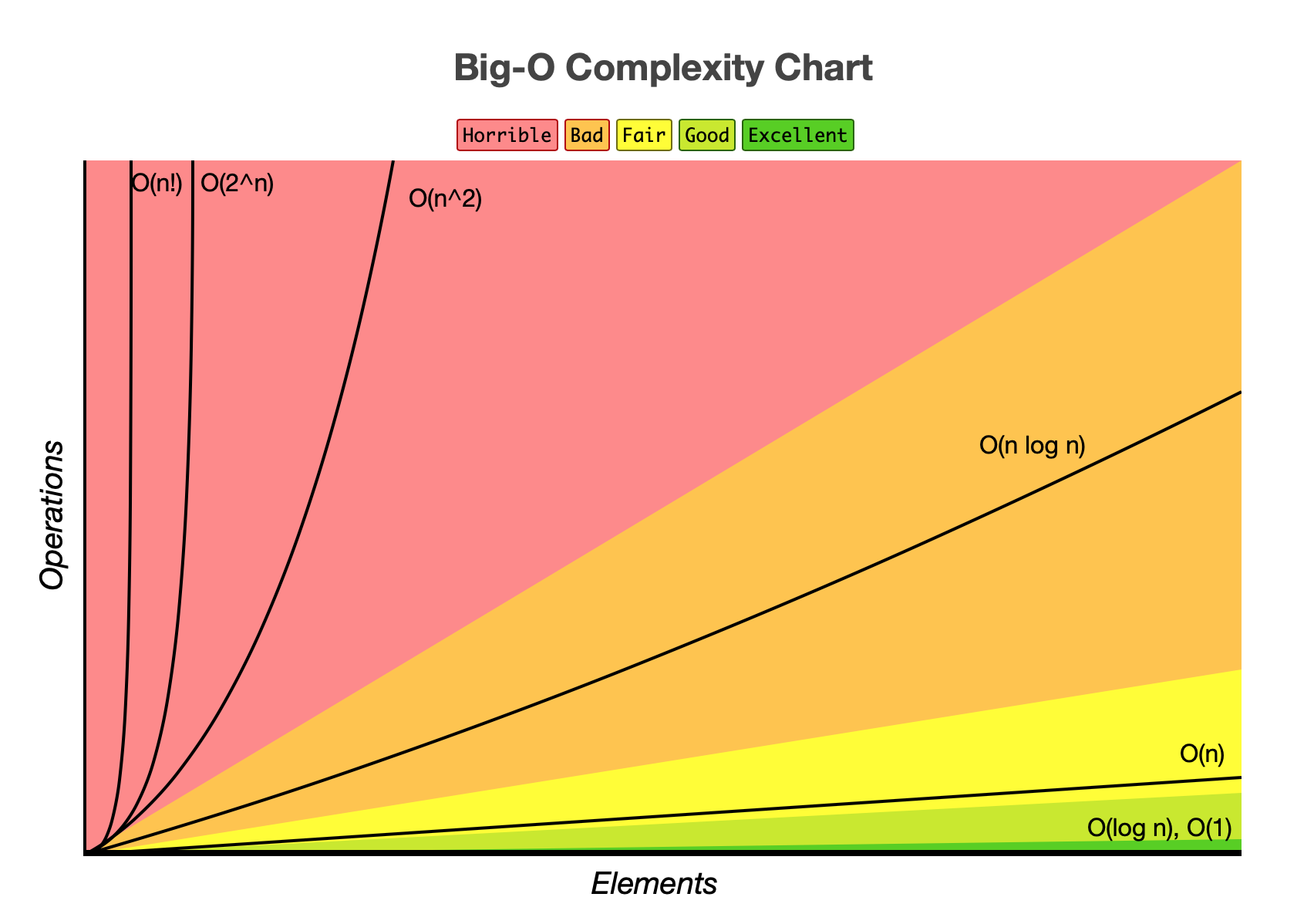
# 喜欢就点个赞、关注支持一下吧!
参考:
Thomas H. Cormen, et al., Introduction to Algorithms Part I 1.2
http://www.bigocheatsheet.com
时间复杂度O(n^2)和O(nlog n)差距有多大?的更多相关文章
- 如何快速求解第一类斯特林数--nlog^2n + nlogn
目录 参考资料 前言 暴力 nlog^2n的做法 nlogn的做法 代码 参考资料 百度百科 斯特林数 学习笔记-by zhouzhendong 前言 首先是因为这道题,才去研究了这个玩意:[2019 ...
- 【转】Java学习—什么是时间复杂度
[原文]https://www.toutiao.com/i6593144782992704007/ 转载:程序员小灰 时间复杂度的意义 究竟什么是时间复杂度呢?让我们来想象一个场景: 某一天,小灰和大 ...
- 日常分享:关于时间复杂度和空间复杂度的一些优化心得分享(C#)
前言 今天分享一下日常工作中遇到的性能问题和解决方案,比较零碎,后续会持续更新(运行环境为.net core 3.1) 本次分享的案例都是由实际生产而来,经过简化后作为举例 Part 1(作为简单数据 ...
- careercup-高等难度 18.6
18.6 设计一个算法,给定10亿个数字,找出最小的100万个数字.假定计算机内存足以容纳全部10亿个数字. 解法: 方法1:排序 按升序排序所有的元素,然后取出前100万个数,时间复杂度为O(nlo ...
- [学习笔记] 多项式与快速傅里叶变换(FFT)基础
引入 可能有不少OIer都知道FFT这个神奇的算法, 通过一系列玄学的变化就可以在 $O(nlog(n))$ 的总时间复杂度内计算出两个向量的卷积, 而代码量却非常小. 博主一年半前曾经因COGS的一 ...
- 最小k个数
题目 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,. 思考 方法0: 直接排序然后返回前k个,最好的时间复杂度为 O(nlo ...
- 排序算法——(2)Python实现十大常用排序算法
上期为大家讲解了排序算法常见的几个概念: 相关性:排序时是否需要比较元素 稳定性:相同元素排序后是否可能打乱 时间空间复杂度:随着元素增加时间和空间随之变化的函数 如果有遗忘的同学可以看排序算法——( ...
- 20172328 2018-2019《Java软件结构与数据结构》第五周学习总结
20172328 2018-2019<Java软件结构与数据结构>第五周学习总结 概述 Generalization 本周学习了第九章:排序与查找,主要包括线性查找和二分查找算法和几种排序 ...
- 超详细的HashMap解析(jdk1.8)
目录 一.预备知识 时间复杂度 基本数据结构 基本位运算 二.HashMap实现原理 结构 速度 三.源码分析 基本常量 基本成员变量 构造方法 put方法 remove 四.日常使用注意事项 五.总 ...
随机推荐
- ASP.NET Boilerplate 学习
1.在http://www.aspnetboilerplate.com/Templates 网站下载ABP模版 2.解压后打开解决方案,解决方案目录: 3.在AbpTest.Web.Host项目的ap ...
- C#检测U盘是否插入
public partial class Form1 : Form { #region u盘属性 public const int WM_DEVICECHANGE = 0x219;//U盘插入后,OS ...
- mysql 临时数据突然变大
晚上收到紧报警,一台数据库服务器磁盘空间使用快速从50%使用率到80%.我们生产的数据库都磁盘是>2T 登录机器发现*.myd文件异常大 登入数据库查询进程 mysql>showproce ...
- [SequenceFile_3] MapFile
0. 说明 MapFile 介绍 && 测试 1. 介绍 对 MapFile 的介绍如下: MapFile 是带有索引的 SequenceFile MapFile 是排序的 Seque ...
- 30个最常用的Linux系统命令行
1.cd命令这是一个非常基本,也是大家经常需要使用的命令,它用于切换当前目录,它的参数是要切换到的目录的路径,可以是绝对路径,也可以是相对路径.如:cd /root/Docements # 切换到目录 ...
- Beta冲刺! Day4 - 砍柴
Beta冲刺! Day4 - 砍柴 今日已完成 晨瑶:追进度 昭锡:改主页UI(还在 永盛:完成大部分接口和接口文档,上线代码 立强:文章去广告,适配手机屏幕.第三方编辑器整合到记录模块. 炜鸿:完成 ...
- asp.net core 如何集成kindeditor并实现图片上传功能
准备工作 1.visual studio 2015 update3开发环境 2.net core 1.0.1 及以上版本 目录 新建asp.net core web项目 下载kindeditor ...
- 780. Reaching Points
idea: 1.从后向前找 2.while (tx > ty) tx -= ty; 替为 % 操作 3.经过循环后,必定只有两种情况才true sx == tx && sy &l ...
- 【WebLogic】weblogic调优
版权声明:本文为博主原创文章(原文:blog.csdn.net/clark_xu 徐长亮的专栏),未经博主同意不得转载. https://blog.csdn.net/u011538954/articl ...
- 在阿里云Centos下LNMP环境搭建
首先,需要安装C语言的编译环境,因为Nginx是C语言编写的.通常大多数Linux都会默认安装GCC,如果没有的话,可以如下安装. 安装make: yum -y install gcc automak ...