Hadoop-2.7.2集群的搭建——集群学习日记
前言
因为比赛的限制是使用Hadoop2.7.2,估在此文章下面的也是使用Hadoop2.7.2,具体下载地址为Hadoop2.7.2
开始的准备
目前在我的实验室上有三台Linux主机,因为需要参加一个关于spark数据分析的比赛,所以眼见那几台服务器没有人用,我们团队就拿来配置成集群。具体打算配置如下的集群
| 主机名 | IP地址(内网) |
|---|---|
| SparkMaster | 10.21.32.106 |
| SparkWorker1 | 10.21.32.109 |
| SparkWorker2 | 10.21.32.112 |
首先进行的是ssh免密码登录的操作
具体操作在上一篇学习日记当中已经写到了,在此不再详细说。
配置Java环境
因为我那三台电脑也是配置好了JDK了,所以在此也不详细说。
配置好Java的机子可以使用
java -version
来查看Java的版本
下载Hadoop2.7.2
因为我最后的文件是放在/usr/local下面的,所以我也直接打开/usr/local文件夹下。直接
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-2.7.2/hadoop-2.7.2.tar.gz
安装Hadoop以及配置Hadoop环境
解压
tar -zxvf hadoop-2.7.2.tar.gz
删除
rm -rf hadoop-2.7.2.tar.gz
解压删除之后打开hadoop-2.7.2文件夹,在etc/hadoop/hadoop-env.sh中配置JDK的信息
先查看本机的jdk目录地址在哪里
echo $JAVA_HOME

vi etc/hadoop/hadoop-env.sh
将
export JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/usr/java/jdk1.8.0_131

为了方便我们以后开机之后可以立刻使用到Hadoop的bin目录下的相关命令,可以把hadoop文件夹下的bin和sbin目录配置到/etc/profile文件中。
vi /etc/profile
添加
export PATH=$PATH:/usr/local/hadoop-2.7.2/bin:/usr/local/hadoop-2.7.7/sbin
按一下esc,按着shift+两次z键保存
使用
source /etc/profile

使得命令配置信息生效,是否生效可以通过
hadoop version
查看
配置Hadoop分布式集群
前言
考虑是为了建立
spark集群,所以主机命名为SparkMasterSparkWorker1SparkWorker2
修改主机名
vi /etc/hostname
修改里面的名字为SprakMaster,按一下esc,按着shift+两次z键保存。

设置hosts文件使得主机名和IP地址对应关系
vi /etc/hosts

配置主机名和IP地址的对应关系。

Ps:其他两台slave的主机也修改对应的SparkWorker1 SparkWorker2,如果修改完主机名字之后户籍的名字没有生效,那么重启系统便可以。三台机子的hostname与hosts均要修改

在三台机子的总的hadoop-2.7.2文件夹下建立如下四个文件夹
- 目录/tmp,用来存储临时生成的文件
- 目录/hdfs,用来存储集群数据
- 目录hdfs/data,用来存储真正的数据
- 目录hdfs/name,用来存储文件系统元数据
mkdir tmp hdfs hdfs/data hdfs/name
配置hadoop文件
在此先修改SparkMaster的配置文件,然后修改完毕后通过
rsync命令复制到其他节点电脑上。
修改core-site.xml
vi etc/hadoop/core-site.xml
具体修改如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://SparkMaster:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop-2.7.2/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
</configuration>
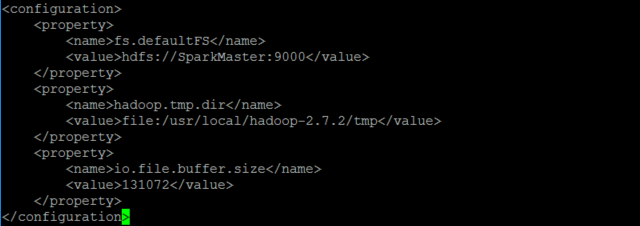
变量fs.defaultFS保存了NameNode的位置,HDFS和MapReduce组件都需要它。这就是它出现在core-site.xml文件中而不是hdfs-site.xml文件中的原因。
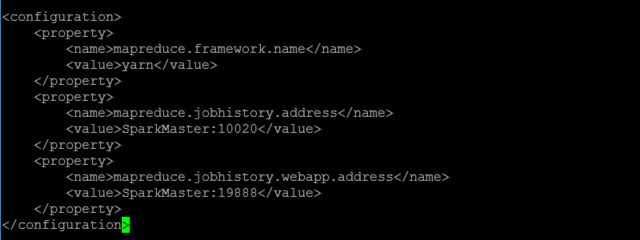
修改marpred-site.xml
具体修改如下
首先我们需要的是将marpred-site.xml复制一份:
cp etc/hadoop/marpred-site.xml.template etc/hadoop/marpred-site.xml
vi etc/hadoop/marpred-site.xml.template
此处修改的是
marpred-site.xml,不是marpred-site.xml.template。
具体修改如下
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>SparkMaster:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>SparkMaster:19888</value>
</property>
</configuration>
修改hdfs-site.xml
vi etc/hadoop/hdfs-site.xml
具体修改如下
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop-2.7.2/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop-2.7.2/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>SparkMaster:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
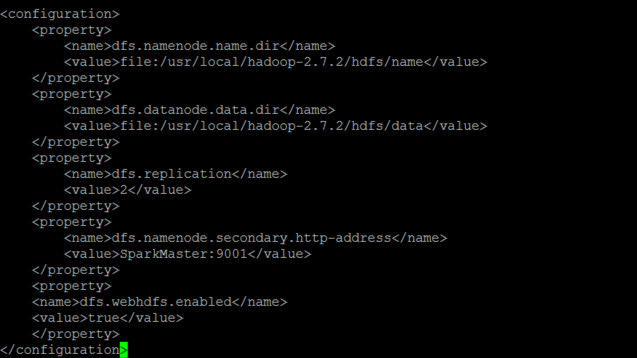
PS:变量dfs.replication指定了每个HDFS数据块的复制次数,即HDFS存储文件的副本个数.我的实验环境只有一台Master和两台Worker(DataNode),所以修改为2。
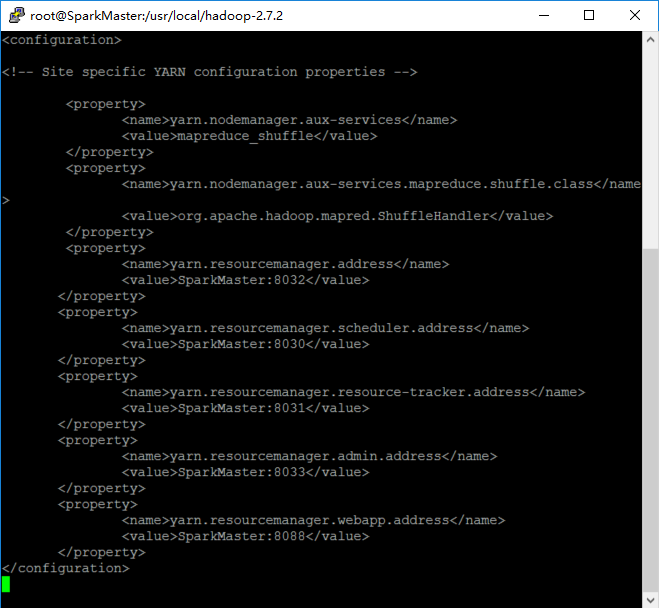
配置yarn-site.xml
vi etc/hadoop/yarn-site.xml
具体配置如下:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>SparkMaster:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>SparkMaster:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>SparkMaster:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>SparkMaster:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>SparkMaster:8088</value>
</property>
</configuration>
修改slaves的内容
将localhost修改成为SparkWorker1、SparkWorker2

将SparkMaster节点的`hadoop-2.7.2/etc/下面的文件通过以下方式放去其他节点
rsync -av /usr/local/hadoop-2.7.2/etc/ SparkWorker1:/usr/local/hadoop-2.7.2/etc/
rsync -av /usr/local/hadoop-2.7.2/etc/ SparkWorker1:/usr/local/hadoop-2.7.2/etc/
完成之后可以查看SparkWorker1、SparkWorker2下面的文件是否变了
启动hadoop分布式集群
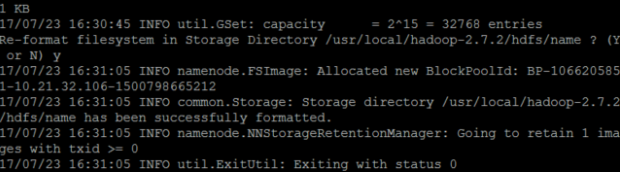
在SparkMaster节点格式化集群的文件系统
输入
hadoop namenode -format
启动Hadoop集群
start-all.sh

查看各个节点的进程信息
使用
jps
查看各节点的进程信息
可以看到



此时分布式的hadoop集群已经搭好了
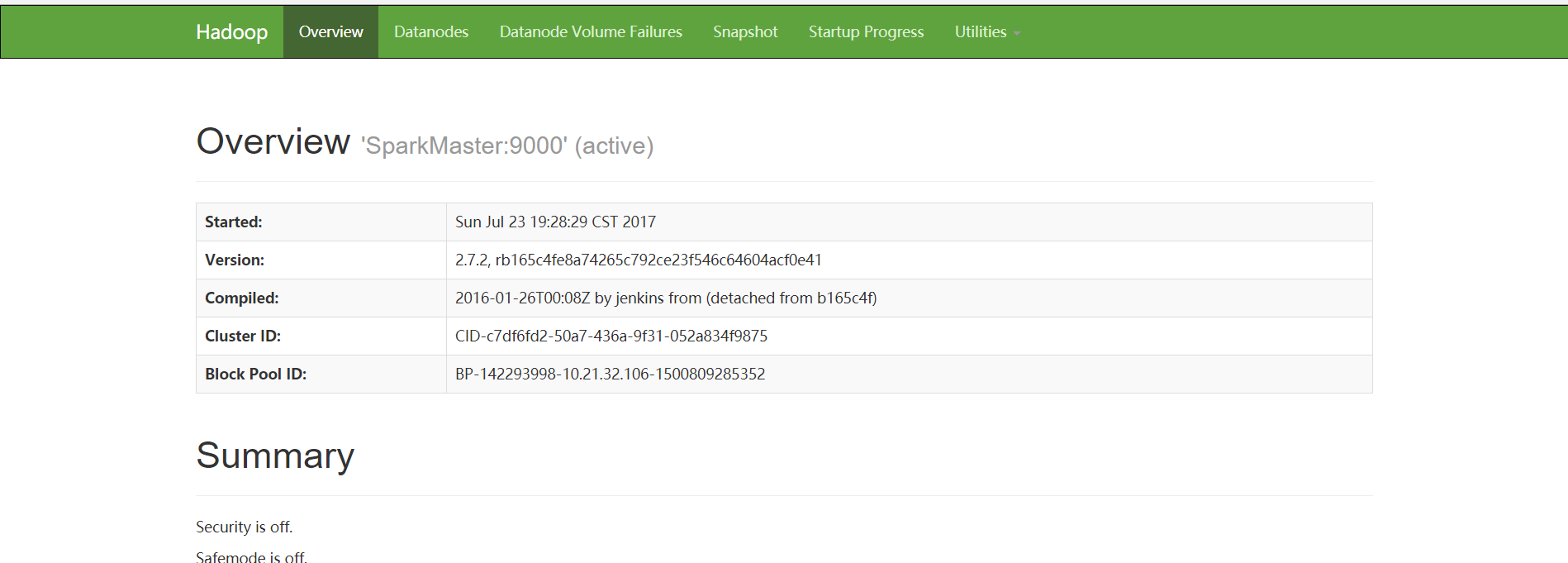
在浏览器输入
SparkMaster_IP:50070
SparkMaster_IP:8088
看到以下界面代表Hadoop集群已经开启了

结言
到此Hadoop的分布式集群就搭好了。这个Spark运行的基础。
参见:CentOS 6.7安装Hadoop 2.7.2
++王家林/王雁军/王家虎的《Spark 核心源码分析与开发实战》++
文章出自kwongtai'blog,转载请标明出处!
Hadoop-2.7.2集群的搭建——集群学习日记的更多相关文章
- Hadoop集群环境搭建步骤说明
Hadoop集群环境搭建是很多学习hadoop学习者或者是使用者都必然要面对的一个问题,网上关于hadoop集群环境搭建的博文教程也蛮多的.对于玩hadoop的高手来说肯定没有什么问题,甚至可以说事“ ...
- Nginx+Tomcat搭建集群,Spring Session+Redis实现Session共享
小伙伴们好久不见!最近略忙,博客写的有点少,嗯,要加把劲.OK,今天给大家带来一个JavaWeb中常用的架构搭建,即Nginx+Tomcat搭建服务集群,然后通过Spring Session+Redi ...
- 深入剖析Redis系列: Redis集群模式搭建与原理详解
前言 在 Redis 3.0 之前,使用 哨兵(sentinel)机制来监控各个节点之间的状态.Redis Cluster 是 Redis 的 分布式解决方案,在 3.0 版本正式推出,有效地解决了 ...
- redis集群与分片(2)-Redis Cluster集群的搭建与实践
Redis Cluster集群 一.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper等,但从redis 3.0之后版本支持redis-cluster集群,Re ...
- Redis Cluster集群的搭建与实践
Redis Cluster集群 一.redis-cluster设计 Redis集群搭建的方式有多种,例如使用zookeeper等,但从redis 3.0之后版本支持redis-cluster集群,Re ...
- 【ZooKeeper系列】1.ZooKeeper单机版、伪集群和集群环境搭建
ZooKeeper安装模式主要有3种: 单机版(Standalone模式)模式:仅有一个ZooKeeper服务 伪集群模式:单机多个ZooKeeper服务 集群模式:多机多ZooKeeper服务 1 ...
- Docker 一步搞定 ZooKeeper 集群的搭建
Docker 一步搞定 ZooKeeper 集群的搭建 背景 原来学习 ZK 时, 我是在本地搭建的伪集群, 虽然说使用起来没有什么问题, 但是总感觉部署起来有点麻烦. 刚好我发现了 ZK 已经有了 ...
- zookeeper集群的搭建以及hadoop ha的相关配置
1.环境 centos7 hadoop2.6.5 zookeeper3.4.9 jdk1.8 master作为active主机,data1作为standby备用机,三台机器均作为数据节点,yarn资源 ...
- Hadoop+Spark:集群环境搭建
环境准备: 在虚拟机下,大家三台Linux ubuntu 14.04 server x64 系统(下载地址:http://releases.ubuntu.com/14.04.2/ubuntu-14.0 ...
随机推荐
- Java IO流之转换流
一.转换流 1.在IO包中,实际上就是分为字节流和字符流,但是除了这两个流之外,还存在了一组字节流-字符流的转换流 2.转换流用于在字节流和字符流之间转换 3.转换流本身是字符流 二.两种转换流 Ou ...
- Java常用类之要点总结
Java常用类之要点总结
- iOS CAReplicatorLayer 实现脉冲动画效果
iOS CAReplicatorLayer 实现脉冲动画效果 效果图 脉冲数量.速度.半径.透明度.渐变颜色.方向等都可以设置.可以用于地图标注(Annotation).按钮长按动画效果(例如录音按钮 ...
- android设计,图标等概述
作者:郦橙 锦妖 链接:https://www.zhihu.com/question/36813390/answer/87029428 著作权归作者所有,转载请联系作者获得授权. 简单复制,用于记录, ...
- CSS3学习系列之选择器(三)
E:enabled伪类选择器和E:disabled伪类选择器 E:enabled伪类选择器用来指定元素处于可用状态的样式. E:disabled伪类选择器用来指定当元素处于不可用状态时的样式. 当一个 ...
- android6.0搜索蓝牙无法显示问题解决
1.android6.0版本搜索蓝牙需要开启位置信息 需在Manifest中添加权限: <uses-permission android:name="android.permissio ...
- 由 “无法使用从远程表选择的 lob 定位符” 错误而引导出来的一系列问题解决方案
周一上班遇到一个数据加工问题:无法使用从远程表选择的 lob 定位符,由于数据源表不是自己的,不能对源数据做修改,于是我打起了存储过程的主意 我们公司的存过是分三步走,第一层是同步源数据,第二层是对一 ...
- Bash函数
一.什么是Bash函数 Bash不支持goto语句,可以用function实现程序流程跳转.当前shell中一组组织在一起并被命名的命令.比脚本的效率高,一旦定义,就成为shell内存的一部分,可以随 ...
- Hybrid App开发之jQuery操作DOM
前言: 前面学习了JQuery的选择器,今天开始学习新的知识,JQuery操作DOM元素. 元素属性的访问与设置 attr(name) 获取元素属性 attr(name,value) 单个属性设置 a ...
- Android的UI调优
对于一个App的UI而言,在流畅性上的改进目标其实就是降低屏幕绘制的延迟,创建流畅和稳定的帧率以避免卡顿. 在理想情况下,全部的测量.布局和绘制的时间最好在16ms以内,这样才能保证屏幕运行的顺畅性. ...