CSDN文章抓取
在抓取网页的时候只想抓取主要的文本框,例如 csdn 中的主要文本框为下图红色框:
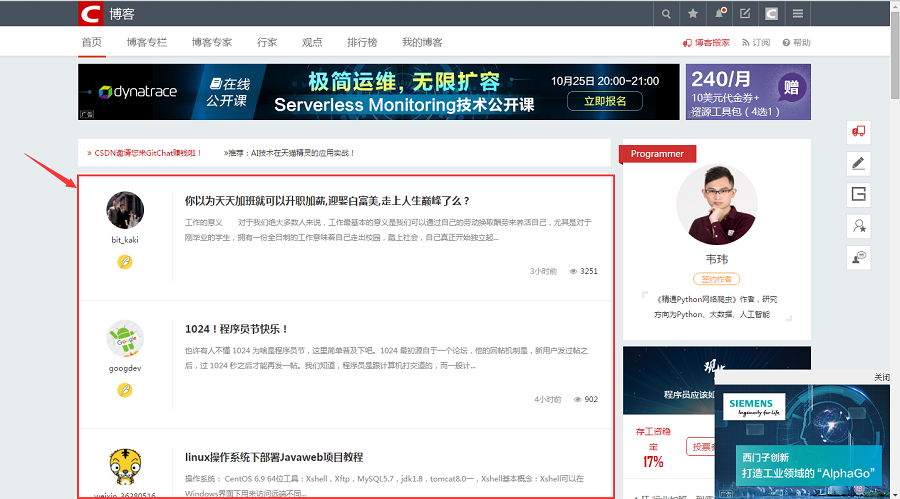
抓取的思想是,利用 bs4 查找所有的 div,用正则筛选出每个 div 里面的中文,找到中文字数最多的 div 就是属于正文的 div 了。定义一个抓取的头部抓取网页内容:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Host': 'blog.csdn.net'}
session = requests.session()
def getHtmlByRequests(url):
headers.update(
dict(Referer=url, Accept="*/*", Connection="keep-alive"))
htmlContent = session.get(url=url, headers=headers).content
return htmlContent.decode("utf-8", "ignore")
识别每个 div 中文字的正则:
import re
# 统计中文字数
def countContent(string):
pattern = re.compile(u'[\u1100-\uFFFD]+?')
content = pattern.findall(string)
return content
遍历每一个 div ,利用正则判断里面中文的字数长度,找到长度最长的 div :
# 分析页面信息
def analyzeHtml(html):
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
part = soup.select('div')
match = ""
for paragraph in part:
content = countContent(str(paragraph))
if len(content) > len(match):
match = str(paragraph)
return match
得到主要的 div 后,提取里面的文字出来:
def main():
url = "http://blog.csdn.net/"
html = getHtmlByRequests(url)
mainContent = analyzeHtml(html)
soup = BeautifulSoup(mainContent, "html.parser")
print(soup.select('div')[0].text)
完整的代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Host': 'blog.csdn.net'}
session = requests.session()
def getHtmlByRequests(url):
headers.update(
dict(Referer=url, Accept="*/*", Connection="keep-alive"))
htmlContent = session.get(url=url, headers=headers).content
return htmlContent.decode("utf-8", "ignore")
# 统计中文字数
def countContent(string):
pattern = re.compile(u'[\u1100-\uFFFD]+?')
content = pattern.findall(string)
return content
# 分析页面信息
def analyzeHtml(html):
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
part = soup.select('div')
match = ""
for paragraph in part:
content = countContent(str(paragraph))
if len(content) > len(match):
match = str(paragraph)
return match
def main():
url = "http://blog.csdn.net/"
html = getHtmlByRequests(url)
mainContent = analyzeHtml(html)
soup = BeautifulSoup(mainContent, "html.parser")
print(soup.select('div')[0].text)
if __name__ == '__main__':
main()
CSDN文章抓取的更多相关文章
- python爬虫CSDN文章抓取
版权声明:本文为博主原创文章.未经博主同意不得转载. https://blog.csdn.net/nealgavin/article/details/27230679 CSDN原则上不让非人浏览訪问. ...
- 抓取csdn上的各类别的文章 (制作csdn app 二)
转载请表明出处:http://blog.csdn.net/lmj623565791/article/details/23532797 这篇博客接着上一篇(Android 使用Fragment,View ...
- Python实现抓取CSDN博客首页文章列表
1.使用工具: Python3.5 BeautifulSoup 2.抓取网站: csdn首页文章列表 http://blog.csdn.net/ 3.分析网站文章列表代码: 4.实现抓取代码: __a ...
- Python实现抓取CSDN热门文章列表
1.使用工具: Python3.5 BeautifulSoup 2.抓取网站: csdn热门文章列表 http://blog.csdn.net/hot.html 3.分析网站代码: 4.实现代码: _ ...
- 使用python抓取CSDN关注人的全部公布的文章
# -*- coding: utf-8 -*- """ @author: jiangfuqiang """ import re import ...
- nodejs爬虫--抓取CSDN某用户全部文章
最近正在学习node.js,就像搞一些东西来玩玩,于是这个简单的爬虫就诞生了. 准备工作 node.js爬虫肯定要先安装node.js环境 创建一个文件夹 在该文件夹打开命令行,执行npm init初 ...
- Python爬虫抓取csdn博客
昨天晚上为了下载保存某位csdn大牛的所有博文,写了一个爬虫来自己主动抓取文章并保存到txt文本,当然也能够 保存到html网页中. 这样就能够不用Ctrl+C 和Ctrl+V了,很方便.抓取别的站点 ...
- python3.6 使用newspaper库的Article包来快速抓取网页的文章或者新闻等正文
我主要是用了两个方法来抽去正文内容,第一个方法,诸如xpath,css,正则表达式,beautifulsoup来解析新闻页面的时候,总是会遇到这样那样各种奇奇怪怪的问题,让人很头疼.第二个方法是后面标 ...
- 微信朋友圈转疯了(golang写小爬虫抓取朋友圈文章)
很多人在朋友圈里转发一些文章,标题都是什么转疯啦之类,虽然大多都也是广告啦,我觉得还蛮无聊的,但是的确是有一些文章是非常值得收藏的,比如老婆经常就会收藏一些养生和美容的文章在微信里看. 今天就突发奇想 ...
随机推荐
- 在dropwizard中使用feign,使用hystrix
前言 用惯了spring全家桶之后,试试dropwizard的Hello World也别有一帆风味.为了增强对外访问API的能力,需要引入open feign.这里简单在dropwizard中使用fe ...
- 命令导入导出oracle库
目前还是新手:所以记录下来最笨的方式,留用 一.从服务器先把库导出来 exp sys/mima@orcl file = "d:\pybghs.dmp" full=y 二.从服 ...
- 微信小程序--图片相关问题合辑
图片上传相关文章 微信小程序多张图片上传功能 微信小程序开发(二)图片上传 微信小程序上传一或多张图片 微信小程序实现选择图片九宫格带预览 ETL:微信小程序之图片上传 微信小程序wx.preview ...
- BlockingQueue<> 队列的作用
BlockingQueue<> 队列的作用 BlockingQueue 实现主要用于生产者-使用者队列 BlockingQueue 实现主要用于生产者-使用者队列,BlockingQueu ...
- <c:forEach>+<c:if>
<c:forEach>:用来做循环<c:if>:相当于if语句用于判断执行,如果表达式的值为 true 则执行其主体内容. <c:forEach var="每个 ...
- 利用原生js制做数据管理平台,适合初学者学习
摘要:数据管理平台在当今社会中运用十分广泛,我们在应用过程中,要对数据进行存储,管理,以及删除查询等操作,而我们在实际设计的时候,大牛们大多用到的是JQuery,而小白对jq理解也较困难,为了让大家回 ...
- js转换字符串为数值的方法
在js读取文本框或者其他表单数据的时候获得的值是字符串类型的,比如两个文本框a和b,假设获得a的value值为11,b的value值为9 ,那么a.value要小于b.value,由于他们都是字符串形 ...
- js特效遮罩层(弹出层)
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- C++ sizeof 误区 大公司面试题
1.C++ 无成员变量和函数的类型的实例,求该实例的sizeof? 答:是1.(不是0) 2.如果在题1的基础上有1个成员变量,sizeof是(1+成员变量的大小)吗? 答:不是,是成员变量的大小. ...
- Sum It Up 广搜
Sum It Up Time Limit:1000MS Memory Limit:32768KB 64bit IO Format:%I64d & %I64u Submit St ...