Python爬取百度贴吧图片
一、获取URL
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据。首先,我们定义了一个getHtml()函数:
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
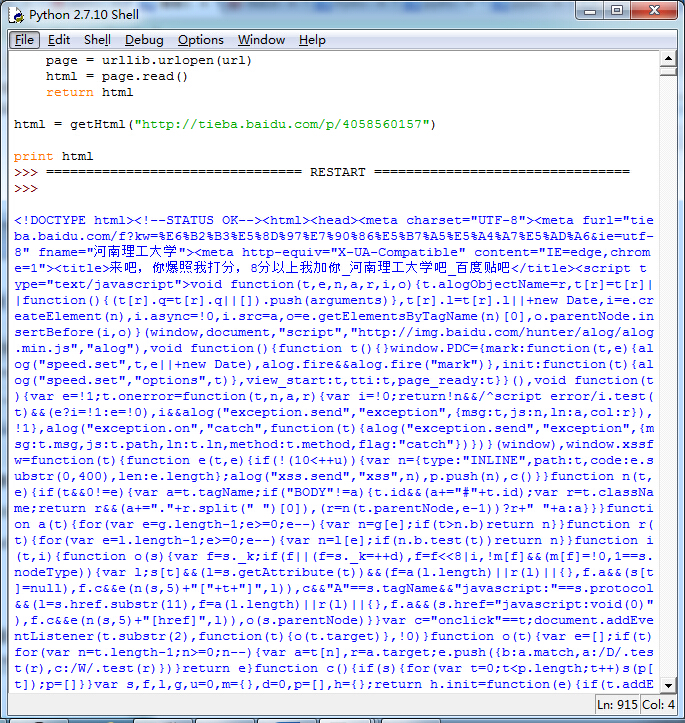
二、查看图片地址
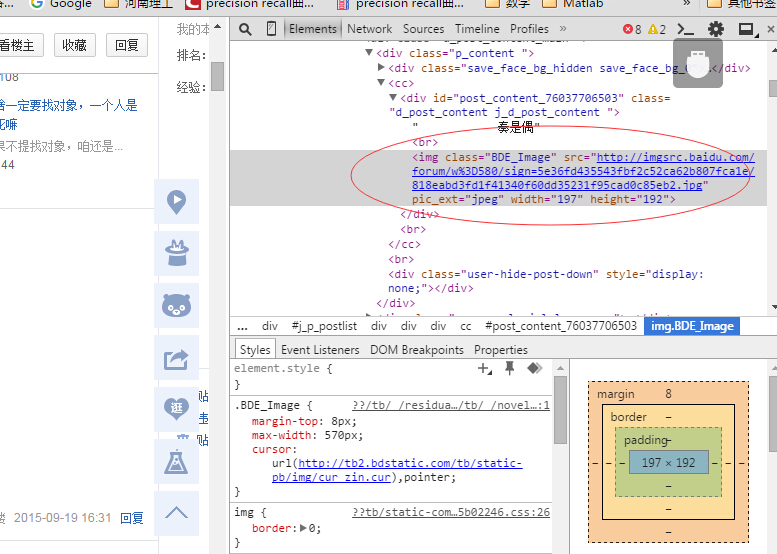
我们又创建了getImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
运行脚本将得到整个页面中包含图片的URL地址。
下面是图片url。
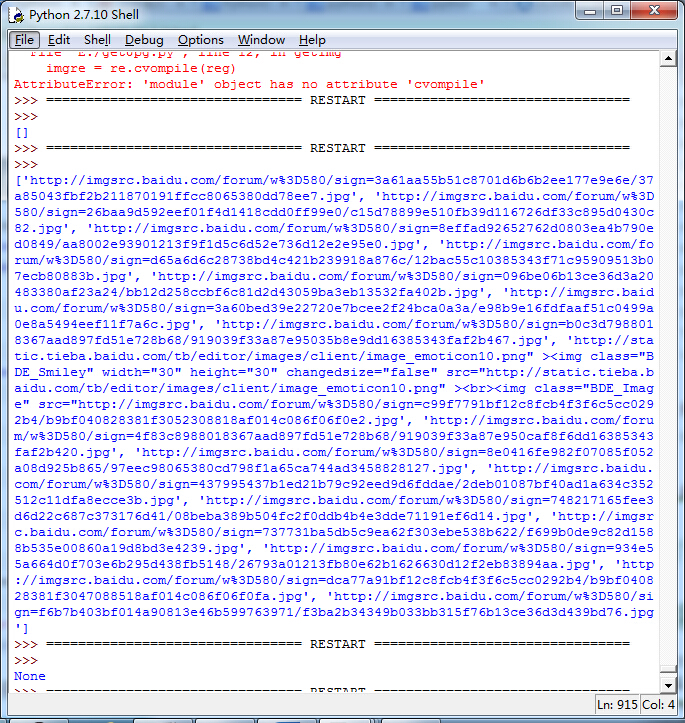
三、保存数据到本地
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
# 原来 pic-ext前面少了个空格打印出来 []
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%d.jpg' %x)
x+=1 html = getHtml("http://tieba.baidu.com/p/4058560157") print getImg(html)
保存的图片在该py文件的桶一目录,如何设置其他保存路径呢,在urlretrieve的最后%x那设置,然后,我不知道怎么设置。
Python爬取百度贴吧图片的更多相关文章
- Python: 爬取百度贴吧图片
练习之代码片段,以做备忘: # encoding=utf8 from __future__ import unicode_literals import urllib, urllib2 import ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- Python爬取 | 唯美女生图片
这里只是代码展示,且复制后不能直接运行,需要配置一些设置才行,具体请查看下方链接介绍: Python爬取 | 唯美女生图片 from selenium import webdriver from fa ...
- 使用python爬取百度贴吧内的图片
1. 首先通过urllib获取网页的源码 # 定义一个getHtml()函数 def getHtml(url): try: page = urllib.urlopen(url) # urllib.ur ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- python 爬取百度url
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-29 18:38:23 # @Author : EnderZhou (z ...
- python爬取百度贴吧帖子
最近偶尔学下爬虫,放上第二个demo吧 #-*- coding: utf-8 -*- import urllib import urllib2 import re #处理页面标签类 class Too ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
随机推荐
- Java编程性能优化
1尽量在合适的场合使用单例 使用单例可以减轻加载的负担,缩短加载的时间,提高加载的效率,但并不是所有地方都适用于单例,简单来说,单例主要适用于以下三个方面: 第一,控制资源的使用,通过线程同步来控制资 ...
- JS中cookie的基本使用
cookie是本身是HTML中ducument中的一个属性,可以用来保存一些简单的数据信息,比如用户名.密码等,提高一些网站的用户体验度.下面就来简单的说说cookie,它有下面几个特性: 1.有过期 ...
- win32 汇编打造 wget 体积3kb
Demo Code .386 .MODEL flat, stdcall OPTION CASEMAP:NONE Include windows.inc include kernel32.inc inc ...
- 05-树8 File Transfer
并查集 简单并查集:输入N,代表有编号为1.2.3……N电脑.下标从1开始.初始化为-1.合并后根为负数,负数代表根,其绝对值代表个数. We have a network of computers ...
- 7.css盒模型
所谓的盒模型,其实就是把元素当成盒子,元素里的文本就是盒子里的东西. 而根据元素的特效,其盒模型的特效也不同,下面是一些总结: 1.块级元素(区块) 所谓块级元素,就是能够设置元素尺寸.有隔离其他元素 ...
- python使用简单http协议来传送文件
python使用简单http协议来传送文件!在ubuntu环境下,局域网内可以使用nc来传送文件,也可以使用基于Http协议的方式来下载文件我们可以使用python -m SimpleHTTPServ ...
- shelll函数求两个输入数字之和
#!/bin/bash #This is a test of the addition of the program! function AddFun { read -p "Enter a ...
- [INS-41112] Specified network interface doesnt maintain connectivi
OS: Oracle Linux Server release 6.3 DB: Oracle 11.2.0.3 安装11.2.0.3.0的RAC,在安装GRID时报错: [INS-41112] Spe ...
- 基于socket的客户端和服务端聊天机器人
服务端代码如下: using System;using System.Net;using System.Net.Sockets;using System.Text;using System.Threa ...
- [原创]EnterpriseDB测试key申请方法
各位有对EnterpriseDB感兴趣的朋友,可以通过邮件方式申请测试key: 发送邮件至:zws@focus-soft.com,官方收到邮件后会有专人与您联系,一般情况都会很快得到一个测试key. ...