Python爬取百度贴吧图片
一、获取URL
Urllib 模块提供了读取web页面数据的接口,我们可以像读取本地文件一样读取www和ftp上的数据。首先,我们定义了一个getHtml()函数:
urllib.urlopen()方法用于打开一个URL地址。
read()方法用于读取URL上的数据,向getHtml()函数传递一个网址,并把整个页面下载下来。执行程序就会把整个网页打印输出。
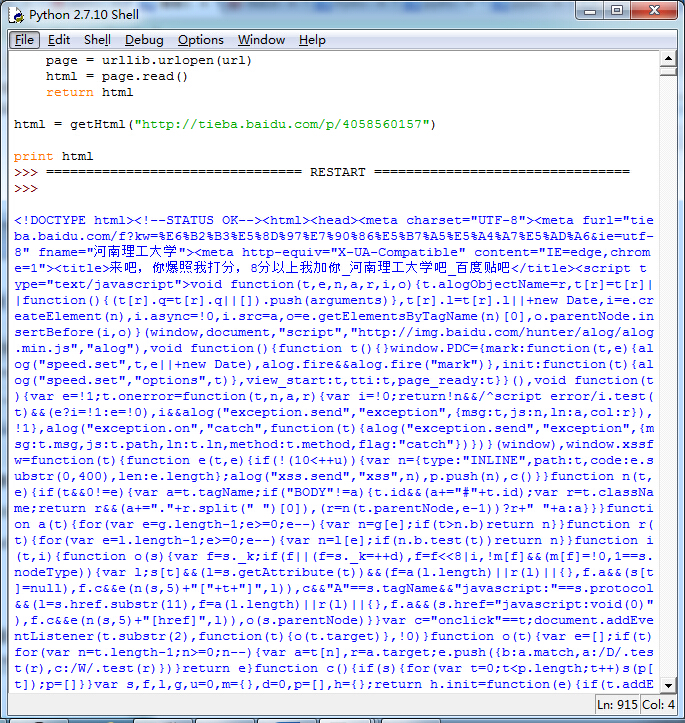
二、查看图片地址
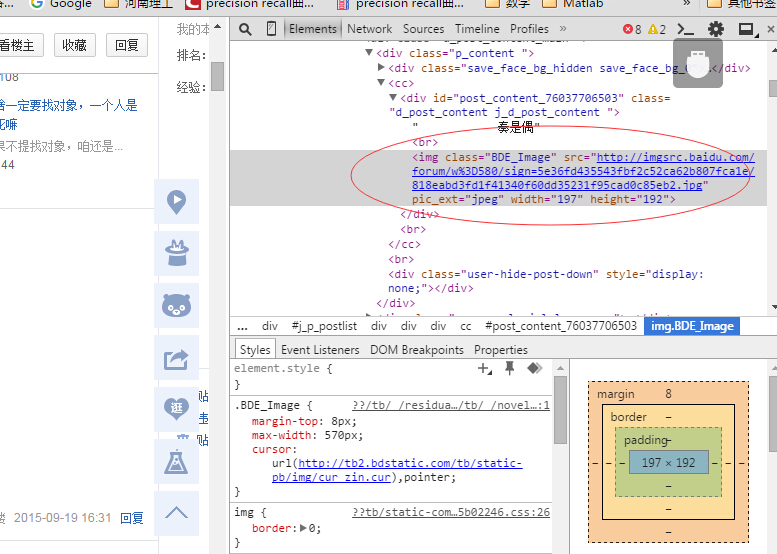
我们又创建了getImg()函数,用于在获取的整个页面中筛选需要的图片连接。re模块主要包含了正则表达式:
re.compile() 可以把正则表达式编译成一个正则表达式对象.
re.findall() 方法读取html 中包含 imgre(正则表达式)的数据。
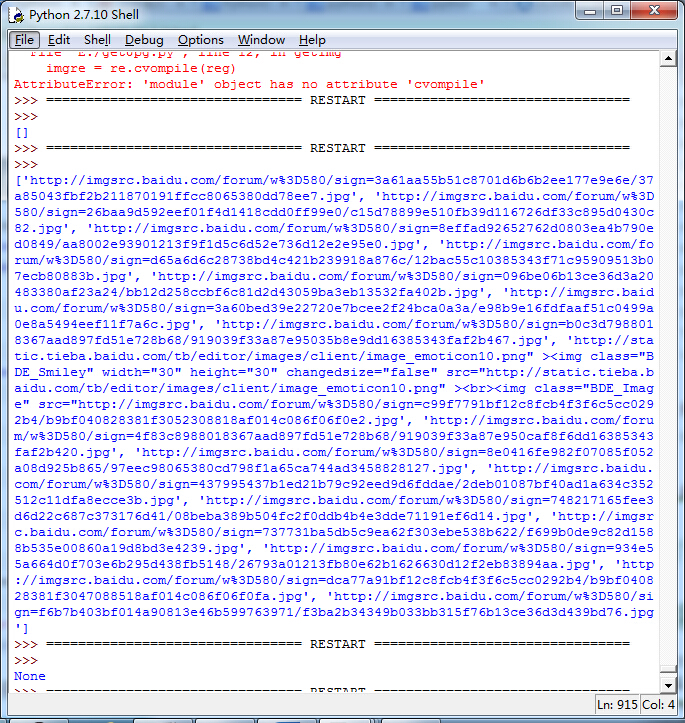
运行脚本将得到整个页面中包含图片的URL地址。
下面是图片url。
三、保存数据到本地
import urllib
import re
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html def getImg(html):
# 原来 pic-ext前面少了个空格打印出来 []
reg = r'src="(.+?\.jpg)" pic_ext'
imgre = re.compile(reg)
imglist = re.findall(imgre,html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%d.jpg' %x)
x+=1 html = getHtml("http://tieba.baidu.com/p/4058560157") print getImg(html)
保存的图片在该py文件的桶一目录,如何设置其他保存路径呢,在urlretrieve的最后%x那设置,然后,我不知道怎么设置。
Python爬取百度贴吧图片的更多相关文章
- Python: 爬取百度贴吧图片
练习之代码片段,以做备忘: # encoding=utf8 from __future__ import unicode_literals import urllib, urllib2 import ...
- python爬取某个网页的图片-如百度贴吧
python爬取某个网页的图片-如百度贴吧 作者:vpoet mail:vpoet_sir@163.com 注:随意copy,不用告诉我 #coding:utf-8 import urllib imp ...
- python爬取某个网站的图片并保存到本地
python爬取某个网站的图片并保存到本地 #coding:utf- import urllib import re import sys reload(sys) sys.setdefaultenco ...
- Python爬取 | 唯美女生图片
这里只是代码展示,且复制后不能直接运行,需要配置一些设置才行,具体请查看下方链接介绍: Python爬取 | 唯美女生图片 from selenium import webdriver from fa ...
- 使用python爬取百度贴吧内的图片
1. 首先通过urllib获取网页的源码 # 定义一个getHtml()函数 def getHtml(url): try: page = urllib.urlopen(url) # urllib.ur ...
- Python——爬取百度百科关键词1000个相关网页
Python简单爬虫——爬取百度百科关键词1000个相关网页——标题和简介 网站爬虫由浅入深:慢慢来 分析: 链接的URL分析: 数据格式: 爬虫基本架构模型: 本爬虫架构: 源代码: # codin ...
- python 爬取百度url
#!/usr/bin/env python # -*- coding: utf-8 -*- # @Date : 2017-08-29 18:38:23 # @Author : EnderZhou (z ...
- python爬取百度贴吧帖子
最近偶尔学下爬虫,放上第二个demo吧 #-*- coding: utf-8 -*- import urllib import urllib2 import re #处理页面标签类 class Too ...
- 爬虫实战(一) 用Python爬取百度百科
最近博主遇到这样一个需求:当用户输入一个词语时,返回这个词语的解释 我的第一个想法是做一个数据库,把常用的词语和词语的解释放到数据库里面,当用户查询时直接读取数据库结果 但是自己又没有心思做这样一个数 ...
随机推荐
- getComputedStyle(and currentStyle)
1.getComputedStyle 1.1 用法: currentStyle获取计算后的样式,也叫当前样式.最终样式.优点:可以获取元素的最终样式,包括浏览器的默认值,而不像style只能获取行间样 ...
- redis 入门
1.命令行工具 在windows上巧命令行指令,实在是令人痛苦,本人实在是受不了windows下cmd的笨,powershell的蠢,只能换一个了. 介绍一款cmd工具cmder(github上开源) ...
- mysql事件调度器定时删除binlog
MySQL5.1.6起Mysql增加了事件调度器(Event Scheduler),可以用做定时执行某些特定任务,来取代原先只能由Linux操作系统的计划任务来执行的工作MySQL的事件调度器可以精确 ...
- SQLite数据库管理的相关命令
1.创建数据库 启动命令行,通过输入如下命令打开Shell模式的CLP: sqlite3 test.db 虽然我们提供了数据库名称,但如果该数据库不存在,SQLite实际上就未创建该数据库,直到在数据 ...
- C 网页压力测试器
引言 <<独白>> 席慕蓉 节选一 把向你借来的笔还给你吧. 一切都发生在回首的刹那. 我的彻悟如果是缘自一种迷乱,那么,我的种种迷乱不也就只是因为一种彻悟? 在一回首间,才忽 ...
- Datastage数据装载报错:Consumed more than 1000000 bytes looking for record delimiter
使用Datastage装载数据时报错如下图: 使用ds进行数据传输时,出现上述问题,最终找到了问题的原因: 我所使用的数据文件比较大,上传到服务器的时候传了80%就出现服务器存储空间不够,我删除以前的 ...
- DB2缓冲池、表空间
在DB2中建立表空间得指向该表空间所属缓冲池,否则表空间指向默认缓冲池 1.缓冲池 1.1 创建缓冲池 语法:CREATE BUFFERPOOL <bp_name> SIZE <nu ...
- Android--将字节数转化为B,KB,MB,GB的方法
//将字节数转化为MB private String byteToMB(long size){ long kb = 1024; long mb = kb*1024; long gb = mb*1024 ...
- Android 实现子View的状态跟随父容器的状态
最近自学着做东西,需要做一个效果,就是我ListView的Item点击下或者选中的时候,我Item里面的各个组件的状态要和我Item的状态保持一直,这样我就可以用XML,去根据组件的不同状态去实现不同 ...
- zoj 2112 Dynamic Rankings
原题链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemId=1112 #include<cstdio> #include ...