Bitcask 存储模型
Bitcask 存储模型
Bitcask 是一个日志型、基于hash表结构的key-value存储模型,以Bitcask为存储模型的K-V系统有 Riak和 beansdb新版本。
日志型数据存储
何谓日志型?就是append only,所有写操作只追加而不修改老的数据,就像我们的各种服务器日志一样。在Bitcask模型中,数据文件以日志型只增不减的写入文件,而文件有一定的大小限制,当文件大小增加到相应的限制时,就会产生一个新的文件,老的文件将只读不写。在任意时间点,只有一个文件是可写的,在Bitcask模型中称其为active data file,而其他的已经达到限制大小的文件,称为older data file,如下图:

文件中的数据结构非常简单,是一条一条的数据写入操作,每一条数据的结构如下:
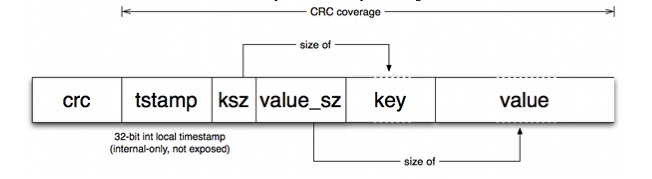
上面数据项分别为key,value,key的大小,value的大小,时间戳(应该是),以及对前面几项做的crc校验值。(数据删除操作也不会删除旧的条目,而是将value设定为一个特殊的值以作标示)
数据文件中就是连续一条条上面格式的数据,如下图:
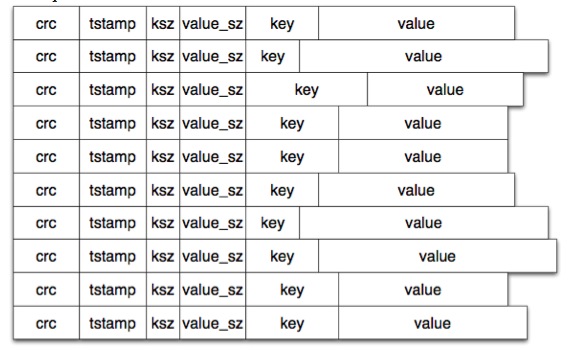
上面就是日志型的数据文件,但文件这样持续的存下去,肯定是会无限膨胀的,为了解决个问题,和其他日志型存储系统一样Bitcask也有一个定期的merge操作。
merge操作,即定期将所有older data file中的数据扫描一遍并生成新的data file(没有包括active data file 是因为它还在不停写入),这里的merge其实就是将对同一个key的多个操作以只保留最新一个的原则进行删除。每次merge后,新生成的数据文件就不再有冗余数据了。
事实上,Bitcask 中有两类文件:
- xxx.w:即上面说的数据文件,xxx 是一个数值,写满1G后将新建文件,数值自增,程序往数值最大的一个文件 Append 数据;
- write.pos:记录当前数值最大的 xxx.w 文件(FileNo),以及该文件的写位移(Offset),方便在写数据的时候快速定位;
定义了数据文件和记录写位移的文件后,我们通过以下方式实现数据写:
- 检查当前 xxx.w 文件写位移 + 当前要写入的数据长度是否大于MAX_FILE_SIZE(即一个数据文件的最大size,这里我们定义为1G);如果大于则创建一个序号增 1 的 .w 文件;
- 调用 open、write 函数将数据追加到当前 .w 文件结尾;
- 更新 write.pos 中 FileNo、Offset 的值;
基于hash表的索引数据
写操作有 write.pos 文件指明要写入的 FileNo 和 Offset;但对于读操作,如何快速地从浩瀚的数据中,找到某个 key 对应数据所在的文件和文件位移呢?这要依赖于内存中的hash表数据索引,如下图

hash表对应的这个结构中包括了三个用于定位数据value的信息,分别是文件id号(file_id),value值在文件中的位置(value_pos),value值的大小(value_sz),于是我们通过读取file_id对应文件的value_pos开始的value_sz个字节,就得到了我们需要的value值。整个过程如下图所示:

由于多了一个hash表的存在,我们的写操作就需要多更新一块内容,即这个hash表的对应关系。于是一个写操作就需要进行一次顺序的磁盘写入和一次内存操作。
另外,由于索引hash表是存放在内存中的,每次进程重启时需要重建hash表,这需要整个扫描一遍所有的数据文件,如果数据文件很大,这将是一个非常耗时的过程。因此Bitcask模型中包含了一个称作hint file的部分,目的在于提高重建hash表的速度。
上面讲到在old data file进行merge操作时,会产生新的data file,而Bitcask模型实际还鼓励生成一个hint file,这个hint file中每一项的数据结构,与data file中的数据结构非常相似,不同的是他并不存储具体的value值,而是存储value的位置,这样,在重建hash表时,就不需要再扫描所有data file文件,而仅仅需要将hint file中的数据一行行读取并重建即可。大大提高了利用数据文件重启数据库的速度。
Bitcask 存储模型的更多相关文章
- Bitcask存储模型
----<大规模分布式存储系统:原理解析与架构实战>读书笔记 近期一直在分析OceanBase的源代码,恰巧碰到了OceanBase的核心开发人员的新作<大规模分布式存储系统:原理解 ...
- LSM树存储模型
----<大规模分布式存储系统:原理解析与架构实战>读书笔记 之前研究了Bitcask存储模型,今天来看看LSM存储模型,两者尽管同属于基于键值的日志型存储模型.可是Bitcask使用哈希 ...
- Entity Framework 6 Recipes 2nd Edition(10-5)译 -> 在存储模型中使用自定义函数
10-5. 在存储模型中使用自定义函数 问题 想在模型中使用自定义函数,而不是存储过程. 解决方案 假设我们数据库里有成员(members)和他们已经发送的信息(messages) 关系数据表,如Fi ...
- SQLite剖析之存储模型
前言 SQLite作为嵌入式数据库,通常针对的应用的数据量相对于DBMS的数据量小.所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树的形式来组织这 ...
- LSM存储模型
LSM存储模型 数据库有3种基本的存储引擎: 哈希表,支持增.删.改以及随机读取操作,但不支持顺序扫描,对应的存储系统为key-value存储系统.对于key-value的插入以及查询,哈希表的复杂度 ...
- SQLite入门与分析(八)---存储模型(1)
写在前面:SQLite作为嵌入式数据库,通常针对的应用的数据量相对于通常DBMS的数据量是较小的.所以它的存储模型设计得非常简单,总的来说,SQLite把一个数据文件分成若干大小相等的页面,然后以B树 ...
- 剖析Elasticsearch集群系列第一篇 Elasticsearch的存储模型和读写操作
剖析Elasticsearch集群系列涵盖了当今最流行的分布式搜索引擎Elasticsearch的底层架构和原型实例. 本文是这个系列的第一篇,在本文中,我们将讨论的Elasticsearch的底层存 ...
- 剖析Elasticsearch集群系列之一:Elasticsearch的存储模型和读写操作
转载:http://www.infoq.com/cn/articles/analysis-of-elasticsearch-cluster-part01 1.辨析Elasticsearch的索引与Lu ...
- 并发编程学习笔记之Java存储模型(十三)
概述 Java存储模型(JMM),安全发布.规约,同步策略等等的安全性得益于JMM,在你理解了为什么这些机制会如此工作后,可以更容易有效地使用它们. 1. 什么是存储模型,要它何用. 如果缺少同步,就 ...
随机推荐
- Oracle-函数Decode进行多值判断
decode函数比较表达式和搜索字,如果匹配,返回结果:如果不匹配,返回default值:如果未定义default值,则返回空值 Decode函数的语法结构如下: decode (expression ...
- lucene-一篇分词器介绍很好理解的文章
本文来自这里在前面的概念介绍中我们已经知道了分析器的作用,就是把句子按照语义切分成一个个词语.英文切分已经有了很成熟的分析器: StandardAnalyzer,很多情况下StandardAnalyz ...
- Hadoop设置环境变量注意事项
路径是/etc/profile. 这个东西不能再普通下设置,打开是彩色的,即便是“:wq!”也不能保存,必须去root下,黑白的. 然后root下source /etc/profile,然后exit, ...
- webapi获取IP的方式
using System.Net.Http; public static class HttpRequestMessageExtensions { private const string HttpC ...
- Bzoj1189 [HNOI2007]紧急疏散evacuate
1189: [HNOI2007]紧急疏散evacuate Time Limit: 10 Sec Memory Limit: 128 MBSubmit: 2293 Solved: 715 Descr ...
- [NOIP2012] 提高组 洛谷P1080 国王游戏
题目描述 恰逢 H 国国庆,国王邀请 n 位大臣来玩一个有奖游戏.首先,他让每个大臣在左.右 手上面分别写下一个整数,国王自己也在左.右手上各写一个整数.然后,让这 n 位大臣排 成一排,国王站在队伍 ...
- PCRE Perl Compatible Regular Expressions Learning
catalog . PCRE Introduction . pcre2api . pcre2jit . PCRE Programing 1. PCRE Introduction The PCRE li ...
- 向列布局动态添加F7
function initBuildingEntryF7(sellId){ var comId = "buildingEntry"; var filter = "&quo ...
- PriorityQueue
基本概念 顾名思义,PriorityQueue是优先级队列,它首先实现了队列接口(Queue),与LinkedList类似,它的队列长度也没有限制,与一般队列的区别是,它有优先级的概念,每个元素都有优 ...
- 屠蛟之路_你的名字_FirstDay
君の名は. "号外,号外!屠龙天团众志成城,惊天技杀alpha龙!号外,号外--" 苦战十日,屠龙少年们依仗最后的惊天技终于将邪恶的alpha怪龙斩杀.但是对屠龙少年而言,这是一场 ...