想学AI开发很简单:只要你会复制粘贴
摘要:本次实践基于 mobilenetV2 实现猫狗图像分类,贯穿了数据集获取及处理、预训练模型微调及迁移、端侧部署及推理等环节和知识点,体会到了 MindSpore 简单的开发体验和全场景快速部署的魅力。
- startTime: 2021年1月23日00:43:22
- endTime: 2021年1月23日11:34:44
(包含学习、睡觉、吃饭、爬坑、水文……的时间)
了解MindSpore开源生态
发现一个小秘密。 github 上多三个仓库,是什么呢?
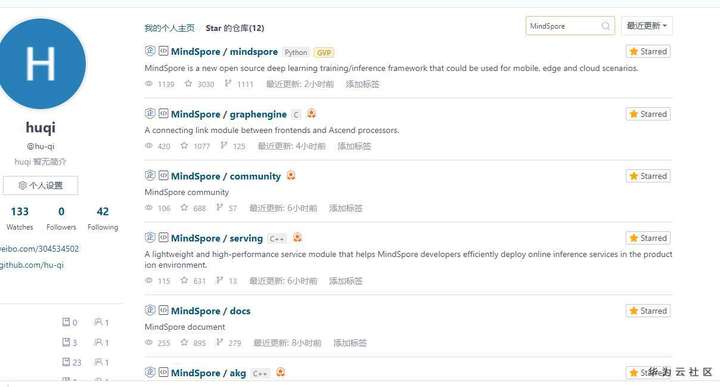
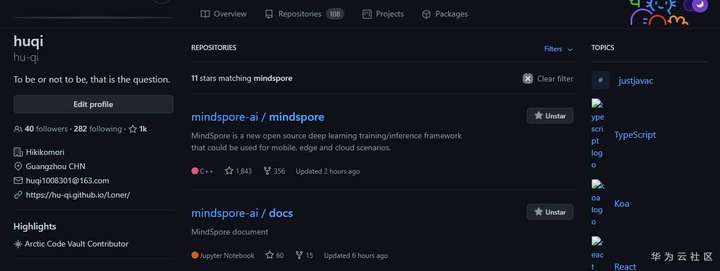
此处应是 github 过滤的 bug ,实际上mindspore-ai 有 15 个仓库, 比 gitee 多出来的三个是:mindspore-21-days-tutorials、 mail_templates、 infrastructure
别看这 3 个不起眼的仓库,在社区建设方面却大有作为。比如,mindspore-21-days-tutorials是我们之前参加 21 天实战营的参考代码和指导文档,多么宝贵的学习资料;另外两个是 MindSpore 的开源基础建设,其中 infrastructure包含了用于配置 Mindspore 社区的所有必需 Dockerfile 和 YAML 文件,并借助 Github 的 Action 定时自动同步 Gitee 的代码到 Github 。
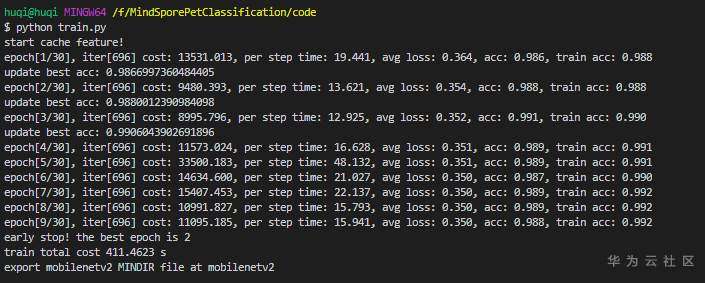
训练时长截图
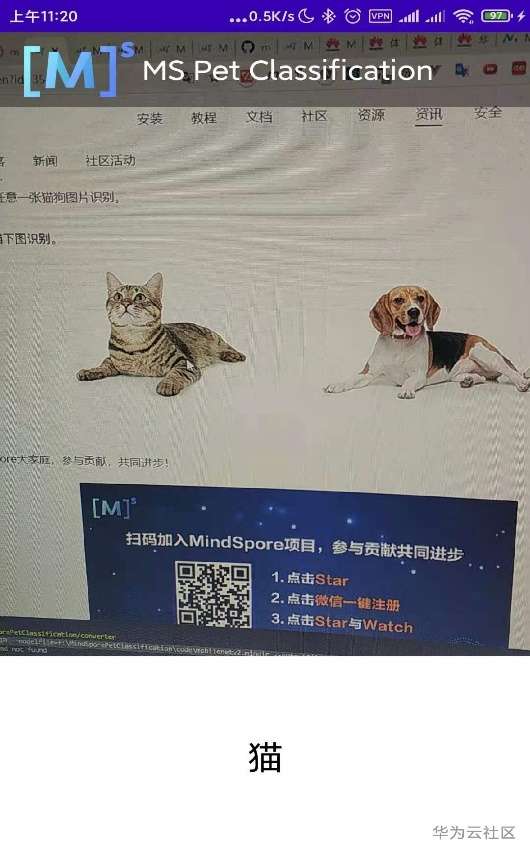
手机识别截图
学习总结
在学习之前我以为我会了,但真正实践起来还是磕磕碰碰,所有的代码似曾相识,都是 26 个字母加一些符号组成,但真正去理解还是发现基本功不够:一是不知道怎么写,二是不知道为什么要这么写。尽管如此,我大概理顺了整个实践流程:训练猫狗图像分类模型(云端) --> 手机端推理及应用 --> 从 “1” 开始 Fine Tune 模型(本地) --> 手机端验证 ,当然作为学渣,整个操作过程肯定不止一个小时, 深刻体会到“眼睛:学会了,脑子:学废了!”,因此必须借此帖记录一下“学废了”的过程:
目的
本次实践基于 mobilenetV2 实现猫狗图像分类,贯穿了数据集获取及处理、预训练模型微调及迁移、端侧部署及推理等环节和知识点,体会到了 MindSpore 简单的开发体验和全场景快速部署的魅力。
项目目录
MindSporePetClassification
├─ ADB // 支持手机与电脑传递文件工具
│ ├─ adb.exe
│ ├─ AdbWinApi.dll
│ ├─ AdbWinUsbApi.dll
│ └─ fastboot.exe
├─ code // Fine tune训练代码及数据集
│ ├─ dataset
│ │ ├─ PetImages
│ │ │ ├─ eval
│ │ │ │ ├─ Cat
│ │ │ │ └─ Dog
│ │ │ ├─ train
│ │ │ │ ├─ Cat
│ │ │ │ └─ Dog
│ │ ├─ MSR-LA - 3467.docx
│ │ └─ readme[1].txt
│ ├─ src
│ │ ├─ __pycache__
│ │ │ ├─ args.cpython-37.pyc
│ │ │ ├─ config.cpython-37.pyc
│ │ │ ├─ dataset.cpython-37.pyc
│ │ │ ├─ lr_generator.cpython-37.pyc
│ │ │ ├─ mobilenetV2.cpython-37.pyc
│ │ │ ├─ models.cpython-37.pyc
│ │ │ └─ utils.cpython-37.pyc
│ │ ├─ args.py
│ │ ├─ config.py
│ │ ├─ dataset.py
│ │ ├─ lr_generator.py
│ │ ├─ mobilenetV2.py
│ │ ├─ models.py
│ │ └─ utils.py
│ ├─ mobilenetV2.ckpt // 预训练模型文件
│ ├─ preprocessing_dataset.py // 预先处理数据集脚本
│ └─ train.py // 主训练脚本
├─ converter // 转换工具MindSpore Lite Converter
│ ├─ converter_lite.exe
│ ├─ libgcc_s_seh-1.dll
│ ├─ libglog.dll
│ ├─ libmindspore_gvar.dll
│ ├─ libssp-0.dll
│ ├─ libstdc++-6.dll
│ └─ libwinpthread-1.dll
└─ kagglecatsanddogs_3367a.zip
依赖安装
本次实践依赖opencv-python 和 matplotlib,一个用来处理图形比如打印图片和嵌入文字,一个用来将数据集以可视化图片的形式展现出来。
pip install opencv-python -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install matplotlib -i https://pypi.tuna.tsinghua.edu.cn/simple
数据预处理
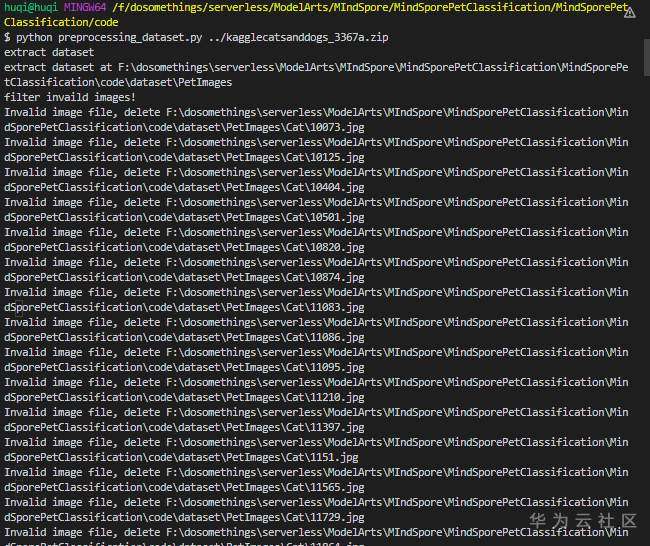
主要删除一些不符合要求(如非JPEG格式)的图片并分割 train 和 eval 数据集,默认9:1:
python preprocessing_dataset.py 您的路径\kagglecatsaData to Dragnddogs_3367a.zip
Fine tune
执行Fine tune脚本train.py,并生成模型文件:
python train.py
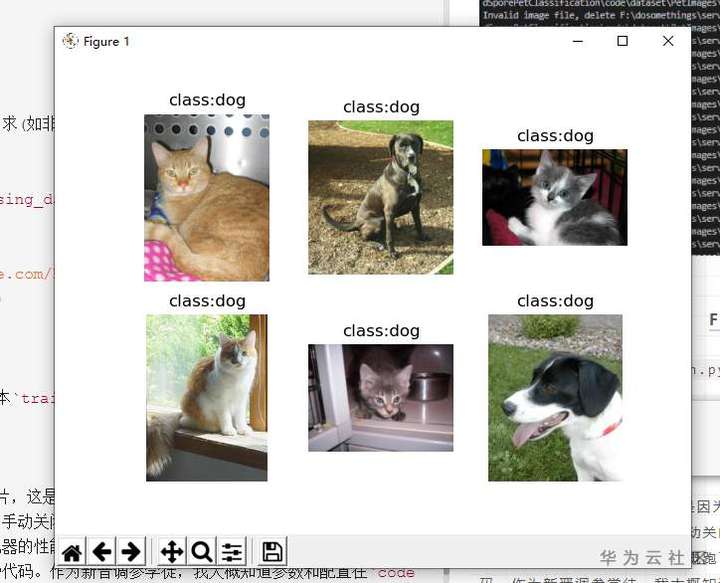
此时会弹窗提示6张图片,这是因为脚本会在正式训练前从数据集中抽取6张图片载入当前模型文件,需要手动关闭才能继续,这是 AI 很傻,全都识别成了 Dog 。
当然,我这边由于机器的原因,没少踩坑,这不“出师未捷身先死”,突然的报错把我整蒙了,将所有num_parallel_workers参数设置为4之后,继续训练!
$ python train.py
start cache feature!
Traceback (most recent call last):
File "train.py", line 52, in <module>
data, step_size = extract_features(backbone_net, args_opt.dataset_path, config)
File "F:\dosomethings\serverless\ModelArts\MIndSpore\MindSporePetClassification\MindSporePetClassification\code\src\dataset.py",
line 84, in extract_features
train_dataset = create_dataset(dataset_path=os.path.join(dataset_path, "train"), do_train=True, config=config)
File "F:\dosomethings\serverless\ModelArts\MIndSpore\MindSporePetClassification\MindSporePetClassification\code\src\dataset.py",
line 41, in create_dataset
ds = de.ImageFolderDataset(dataset_path, num_parallel_workers=8, shuffle=True)
File "C:\Users\huqi\AppData\Local\Programs\Python\Python37\lib\site-packages\mindspore\dataset\engine\validators.py", line 51, in new_method
validate_dataset_param_value(nreq_param_int, param_dict, int)
File "C:\Users\huqi\AppData\Local\Programs\Python\Python37\lib\site-packages\mindspore\dataset\core\validator_helpers.py", line 352, in validate_dataset_param_value
check_num_parallel_workers(param_dict.get(param_name))
File "C:\Users\huqi\AppData\Local\Programs\Python\Python37\lib\site-packages\mindspore\dataset\core\validator_helpers.py", line 340, in check_num_parallel_workers
raise ValueError("num_parallel_workers exceeds the boundary between 1 and {}!".format(cpu_count()))
ValueError: num_parallel_workers exceeds the boundary between 1 and 4!
这一步耗时就和本地机器的性能有关了,我的粗粮渣渣机大概跑废了。趁着训练的空档,学习了一些代码。作为新晋调参学徒,我大概知道参数和配置在code\src\args.py和code\src\config.py这两个文件,而数据的加载在code\src\dataset.py这个文件处理,code\src\mobilenetV2.py定义了模型,code\src\models.py这个文件读取和保存模型并打印输出训练日志。
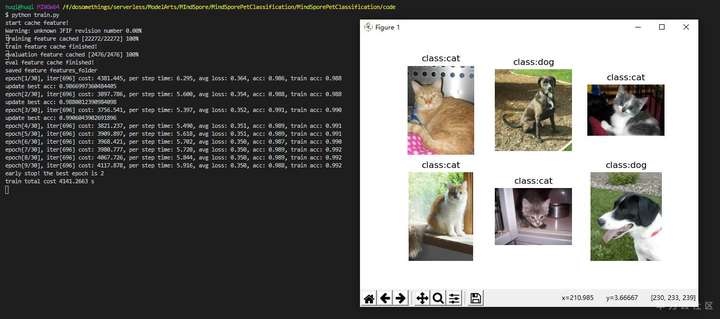
训练完成会,又会调用predict_from_net方法来显示预测的图片和标签,这回我们发现 AI 挺棒的,全部识别正确! 当我满怀信心点击关闭的时候,以为程序立马会给我一个mobilenetv2.mindir,结果我又蒙了,返回了一串错误日志!!!
early stop! the best epoch is 2
train total cost 4141.2663 s
Traceback (most recent call last):
File "train.py", line 81, in <module>
export_mindir(net, "mobilenetv2")
File "F:\dosomethings\serverless\ModelArts\MIndSpore\MindSporePetClassification\MindSporePetClassification\code\src\utils.py", line 93, in export_mindir
export(net, Tensor(input_np), file_name=path, file_format='MINDIR')
File "C:\Users\huqi\AppData\Local\Programs\Python\Python37\lib\site-packages\mindspore\train\serialization.py", line 535, in export
Validator.check_file_name_by_regular(file_name)
File "C:\Users\huqi\AppData\Local\Programs\Python\Python37\lib\site-packages\mindspore\_checkparam.py", line 438, in check_file_name_by_regular
target, prim_name, reg, flag))
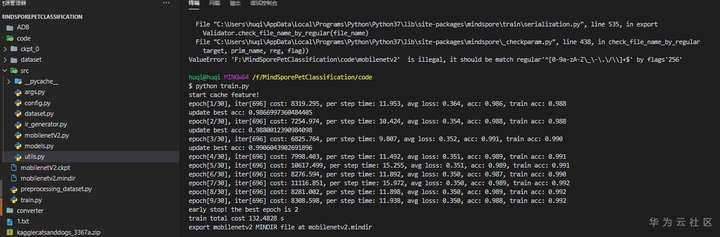
ValueError: 'F:\dosomethings\serverless\ModelArts\MIndSpore\MindSporePetClassification\MindSporePetClassification\code\mobilenetv2.mindir' is illegal, it should be match regular'^[0-9a-zA-Z\_\-\.\/\\]+$' by flags'256'
一开始我以为是文件层级太深了,将文件目录迁移到盘的根目录,重来重来!好在不需要再次加载数据集了,不然又得漫长的等待。 满怀信心结果又被“啪啪啪”打脸,之后群里请教一遍之后,王辉老师建议我把路径改成文件名再试试,果然立马奏效~
- path = os.path.abspath(f"{name}.mindir")
+ path = name
终于如愿以偿,code\mobilenetv2.mindir她来了!
手机端推理及应用
- 训练模型转换
将.mindir模型文件转换成.ms文件,.ms文件可以导入端侧设备并基于MindSpore端侧框架训练。
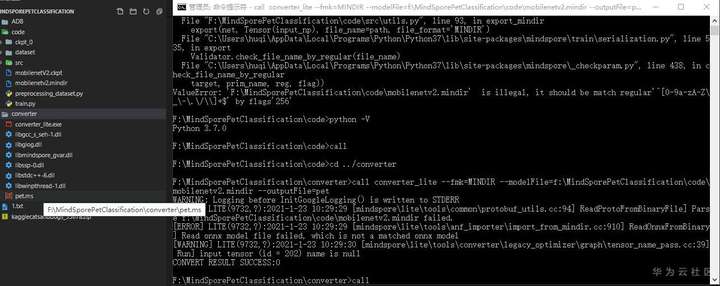
F:\MindSporePetClassification\converter>call converter_lite --fmk=MINDIR --modelFile=f:\MindSporePetClassification\code\mobilenetv2.mindir --outputFile=pet
我们可以下载 MindSpore 官方提供的 Android APP 源码: https://gitee.com/mindspore/mindspore/tree/master/model_zoo/official/lite/pet_classification
或者直接下载打包好的 APP 安装到手机: https://download.mindspore.cn/model_zoo/official/lite/apk/pet/petclassification.apk
先体验下预训练模型的识别效果:
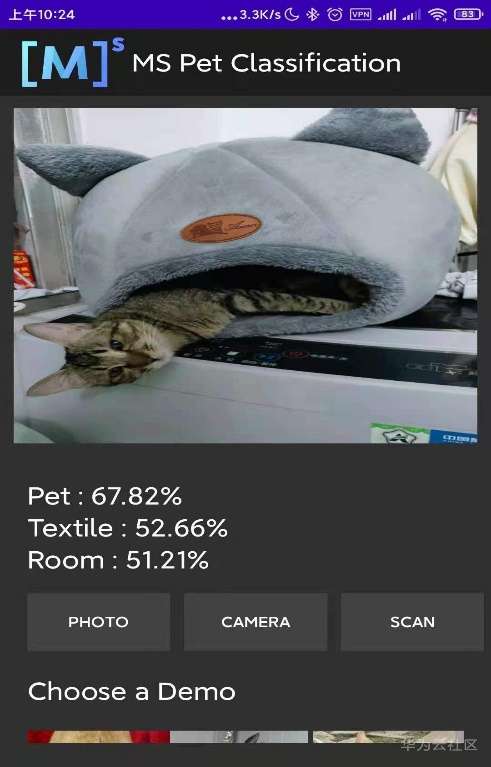
接着我们把转换好的模型移动到手机端的/sdcard/PetClassification,这里用到的是 ADB 工具:需要确保手机已开启开发者模式并打开文件传输
F:\MindSporePetClassification\converter>adb push f:\MindSporePetClassification\converter\pet.ms /sdcard/PetClassification
* daemon not running; starting now at tcp:5037
* daemon started successfully
f:\MindSporePetClassification\converter\pet.ms: 1 file pushed, 0 skipped. 43.4 MB/s (8900552 bytes in 0.196s)
再试试识别效果:
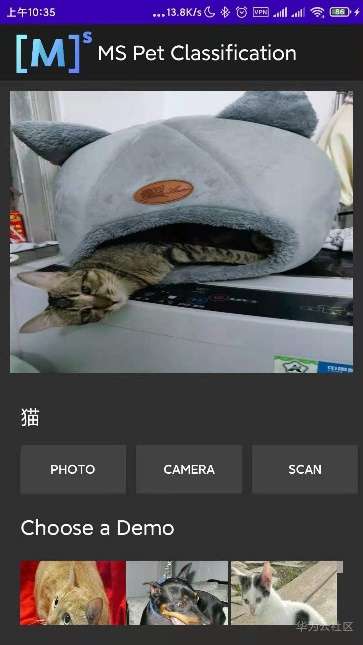
对本次实践 APP 端代码感兴趣的小伙伴可以直接去阅读源码: https://gitee.com/mindspore/mindspore/blob/master/model_zoo/official/lite/pet_classification/app/src/main/java/com/mindspore/classificationforpet/widget/MainActivity.java
本文分享自华为云社区《Copy攻城狮1小时入门AI开发工程师》,原文作者:胡琦。
想学AI开发很简单:只要你会复制粘贴的更多相关文章
- 想学 iOS 开发高阶一点的东西,从何开始?
前言 如果你正在学习 iOS, 或者正在从事IOS开发? 还是一个一个迷茫的待就业大学生,或是公司的到一个半老员工? 现在到了开发的一个阶段了,基本的东西很熟了,想着提高技术? 学习难一点的东西,不知 ...
- 华为全栈AI技术干货深度解析,解锁企业AI开发“秘籍”
摘要:针对企业AI开发应用中面临的痛点和难点,为大家带来从实践出发帮助企业构建成熟高效的AI开发流程解决方案. 在数字化转型浪潮席卷全球的今天,AI技术已经成为行业公认的升级重点,正在越来越多的领域为 ...
- 我在阿里这仨月 前端开发流程 前端进阶的思考 延伸学习的方式很简单:google 一个关键词你能看到十几篇优秀的博文,再这些博文中寻找新的关键字,直到整个大知识点得到突破
我在阿里这仨月 Alibaba 试用期是三个月,转眼三个月过去了,也到了转正述职的时间.回想这三个月做过的事情,很多很杂,但还是有重点. 本文谈一谈工作中遇到的各种场景,需要用到的一些前端知识,以及我 ...
- 女神说拍了一套写真集想弄成素描画?很简单,用Python就行了!
素描作为一种近乎完美的表现手法有其独特的魅力,随着数字技术的发展,素描早已不再是专业绘画师的专利,今天这篇文章就来讲一讲如何使用python批量获取小姐姐素描画像.文章共分两部分: 第一部分介绍两种使 ...
- 手把手教你开发chrome扩展一:开发Chrome Extenstion其实很简单
手把手教你开发chrome扩展一:开发Chrome Extenstion其实很简单 手把手教你开发chrome扩展一:开发Chrome Extenstion其实很简单 手把手教你开发Chrome扩 ...
- electron开发客户端注意事项(兼开源个人知识管理工具“想学吗”)
窗口间通信的问题 electron窗口通信比nwjs要麻烦的多 electron分主进程和渲染进程,渲染进程又分主窗口的渲染进程和子窗口的渲染进程 主窗口的渲染进程给子窗口的渲染进程发消息 subWi ...
- 黄聪:360浏览器、chrome开发扩展插件教程(1)开发Chrome Extenstion其实很简单
转载:http://www.cnblogs.com/walkingp/archive/2011/03/31/2001628.html Chrome的更新速度可以说前无古人,现在我每天开机的第一件事就是 ...
- 对想进入Unity开发新人的一些建议
提前声明:本文只是写给那些非职业游戏开发人士,只面向那些在校本科生,或已就业但无unity背景的同学们,当然是面对程序员方向的.本人刚工作也没多久,资历尚浅,之前在网上有一位同学让我谈谈一些想法,所以 ...
- 推荐一款基于 AI 开发的 IDE 插件,帮助提升编码效率
最近在浏览技术社区的时候,发现了一款神奇 IDE 插件,官网称可以利用 AI 帮助程序员写代码,一下子吸引了我的好奇心.赶紧下载下来使用一番,感觉确实蛮神奇,可以火速提升编程效率. 这款插件叫做 ai ...
- 《花雕学AI》13:早出对策,积极应对ChatGPT带来的一系列风险和挑战
ChatGPT是一款能和人类聊天的机器人,它可以学习和理解人类语言,也可以帮人们做一些工作,比如翻译.写文章.写代码等.ChatGPT很强大,让很多人感兴趣,也让很多人担心. 使用ChatGPT有一些 ...
随机推荐
- 秋招过半零Offer怎么办?
参加今年秋招的同学都知道,尤其是双非本科更是体验深刻.9 月份至今,面试寥寥无几.笔试也不是很多,大中小公司 Offer 没拿下一个.作为应届生的我们,该怎么办呢? 1.调整好心态 这个世界上有两种事 ...
- 二进制枚举&爆搜DFS
给定一个如下图所示的全圆量角器. 初始时,量角器上的指针指向刻度 0. 现在,请你对指针进行 n 次拨动操作,每次操作给定一个拨动角度 ai,由你将指针拨动 ai 度,每次的拨动方向(顺时针或逆时针) ...
- OceanBase金融SQL、亿万级别据量优化案例(Row_number 开窗 + 分页SQL)
最近优化了不少SQL,简单的SQL顺手搞了不好意思发出来了忽悠人,复杂很考验逻辑思维的,但是又不想分享出来(自己收藏的案例),怕被人抄袭思路. 今天遇到一条很有意思的SQL案例: 性能SQL(金融行 ...
- 聊聊如何在Java应用中发送短信
很多业务场景里,我们都需要发送短信,比如登陆验证码.告警.营销通知.节日祝福等等. 这篇文章,我们聊聊 Java 应用中如何优雅的发送短信. 1 客户端/服务端两种模式 Java 应用中发送短信通常需 ...
- Grafana新手教程-实现仪表盘创建和告警推送
前言 最近在使用Grafana的时候,发现Grafana功能比想象中要强大,除了配合Prometheus使用之外,他自身都可以做很多事情,可视化和监控平台,还可以直接根据用户自定义的告警规则完成告警和 ...
- Meissel–Lehmer 算法
前言 推荐先行阅读我的blog文章----Min_25 筛 什么是Meissel–Lehmer 算法 Meissel-Lehmer 算法是一种基于 \(ϕ\) 函数的的快速计算前缀质数个数(当然也可以 ...
- python之封装及私有方法
目录 封装 简洁 私有方法 封装:提高程序的安全性 将属性和方法包装到类对象中,在方法内部对属性进行操作,在类对象外部调用方法,使得程序更加简洁 在python中,如果该属性不希望在类对象外部被访问, ...
- python内置模块——logging
内置模块-logging loging模块是python提供的内置模块,用来做日志处理. 日志等级: 等级 释义 级别数值 CRITICAL(fatal) 致命错误,程序根本跑不起来 50 ERROR ...
- Guava Preconditions类的各种用法
公众号「架构成长指南」,专注于生产实践.云原生.分布式系统.大数据技术分享. Guava Preconditions类 提供静态方法列表,用于检查是否使用有效参数值调用方法或构造函数.如果前提条件失败 ...
- [ABC274Ex] XOR Sum of Arrays
section> Problem Statement For sequences $B=(B_1,B_2,\dots,B_M)$ and $C=(C_1,C_2,\dots,C_M)$, eac ...