论文解读丨CIKM'22 MARINA:An MLP-Attention Model for Multivariate Time-Series Analysis
摘要:华为云数据库创新Lab在论文《MARINA: An MLP-Attention Model for Multivariate Time-Series Analysis》中提出了华为自研的自回归时序神经网络模型,可用于时序数据的预测以及异常检测。
本文分享自华为云社区《CIKM'22 MARINA论文解读》,作者: 云数据库创新Lab 。
华为云数据库创新Lab在论文《MARINA: An MLP-Attention Model for Multivariate Time-Series Analysis》中提出了华为自研的自回归时序神经网络模型,可用于时序数据的预测以及异常检测。本文发表在CIKM'22上,CIKM会议是由美国计算机协会(ACM)组织的、数据挖掘领域的顶级国际学术会议,该会议与2022年10月17日到21日在美国佐治亚州亚特兰大召开。
论文链接:https://dl.acm.org/doi/pdf/10.1145/3511808.3557386
背景
近年来,随着物联网(IoT)以及智能运维(AIOps)等新兴业务的兴起,时序数据在数据分析领域逐渐成为了一种主要的数据类型。在IoT场景,一个系统的各个组件中会实时产生监控时序数据。例如工厂锅炉的压力,温度传感器都会实时上传对应的压力温度数据,飞机的高度,速度传感器也会记录相应的时序数据。同时在AIOps场景,一个云服务集群也会实时上传虚拟机的CPU, MEM, disk usage等关键指标作为系统健康度,系统负载的评价标准。
一般来说时序数据具有以下两个特点:体量巨大,信息密度低。以云系统监控为例,一台虚拟机的指标检测数量一般在几十的数量级,一个region的云监控时间线上报量可以达到上亿的级别。一星期的时序数据存储量就可以超过10TB。另一方面,绝大部分云监控数据都是稳定不变或者是小范围变化的,只有极少数据是大范围波动,甚至有异常的。因此从海量的时序数据中发掘有意义的信息是非常巨大的挑战。
鉴于时序数据的特点,人工从大量时序数据中发掘有效信息是不可行的。近年来,工业界和高校都投入了很多人力去研究自动化的时序分析算法。时序分析包含时序预测,异常检测,分类,聚类,特征提取等多个方向。本文主要关注的是预测和异常检测两个方面。
问题描述
本文主要关注的是时序预测和异常检测,下面是对这两个问题简单的数学化描述。
多维时序预测:

多维异常检测:

采用基于预测的异常检测的好处是可以统一利用预测神经网络同时解决预测和异常检测的问题。
问题思考
基于以上的问题定义后,本文专注于设计预测算法。预测算法需要考虑到以下三个要点才能做到预测准确:
时间相关性
时间相关性指多维时间序列中,同一维度的数据点前后时间的相关性,从宏观上体现在该维度的周期性和趋势性。以下图为例,下图是加州湾区的三条道路拥堵程度的时序数据。可以清楚的看到,每一个维度都存在明显的周期性,这种周期性即被归为时间相关性。
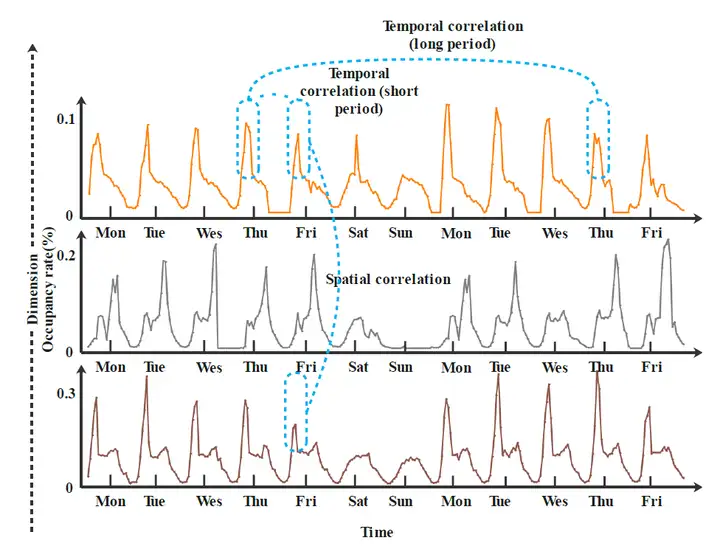
空间相关性
空间相关性指的是多维时间序列中,不同维度之间的相关性。从上图可以看到,维度1和维度3的拥堵程度尖峰的发生时间存在很强的相似性,这种相似性在本文中被归为空间相关性。
平稳性
在工程实现中,平稳性一般指宽平稳或循环平稳,即分布的均值以及自相关函数不随时间变化或随时间周期变化。平稳性是自回归预测的潜在假设,当数据非平稳时,预测值可能发生巨大偏差。在时序数据中,非平稳数据是很常见的,例如下图ETT数据集中,数据前后,均值发生较大变化,是典型非平稳数据。常见的预测算法,例如ARIMA采取差分的方式迫使数据平稳。
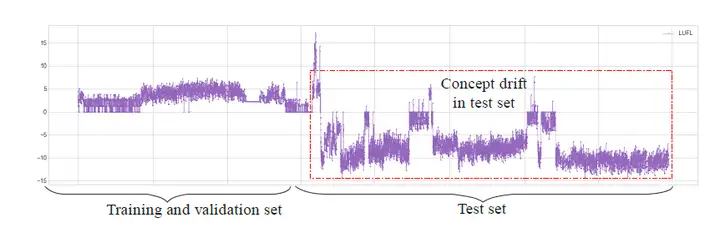
算法设计
归一化方法设计
在设计算法网络之前,首先需要保证网络输入数据的平稳性,即需要限制数据输入的波动范围。ARIMA等算法采取差分的方式做平稳性保证,然而,差分的方式会使噪声叠加,增大噪声干扰。本文提出利用动态归一化(dynamic normalization)的方式对数据进行平稳性保证。
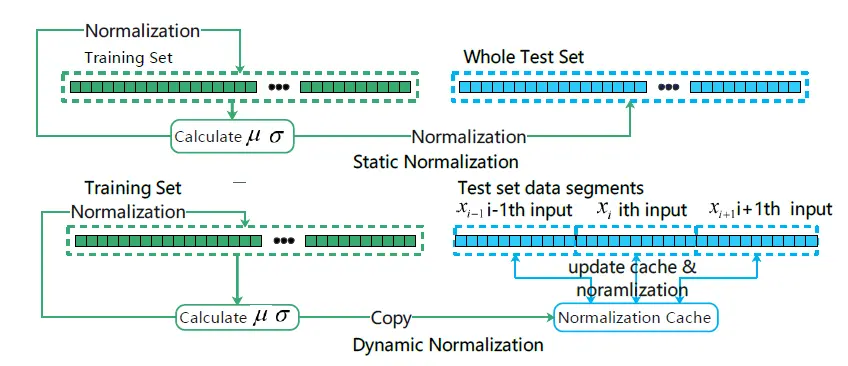
如上图所示,一般的时序归一化方法如上图的上半部分所示,数据分为训练集合测试集两部分,在归一化的过程中,首先计算训练集的均值方差,并用该均值方差归一化训练集自身。在测试集上,则利用训练集的均值方差归一化测试集。这种做法存在的问题是,当数据非平稳时,测试集的值域可能合训练集差距较大,导致测试集上的预测结果非常差。并且此种归一化并未考虑到时序数据的特性,在测试集上,数据实际上是按照滑动窗口顺序输入神经网络进行预测的,滑动窗口之前的所有数据应该被视为已知并可用于帮助后续预测。
基于以上分析,我们提出动态归一化策略。首先,在训练集上,动态归一化与传统归一化采用相同的策略,即训练集计算整体均值方差并用它来归一化自己。在测试集上,归一化过程以网络输入的滑动窗口为单位。如上图下半部分所示,算法维持一个动态的均值,方差,其初始值为训练集的均值方差。每当一个滑动窗口的数据进入归一化算法,首先该算法利用滑动窗口的数据更新当前的均值方差,并用该均值方差归一化滑动窗口的预测输入。该方法的好处是可以动态保证神经网络输入数据的范围,确保输入数据的平稳性,同时不会引入多余噪声。
时间相关性学习模块
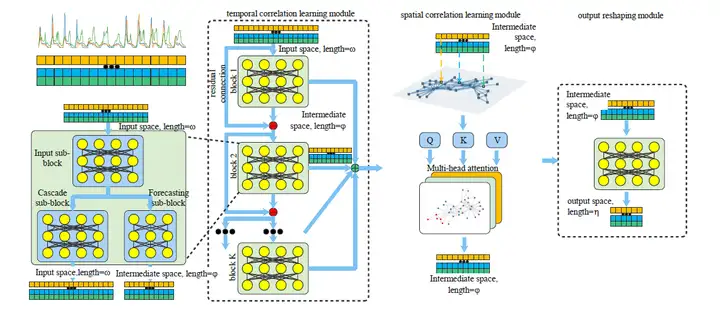
本文的预测网络结构MARINA如上图所示,整个网络结构分为三个模块,时间相关性模块,空间相关性模块,输出整形模块。
在时间相关性学习中,一般的备选网络结构包含MLP,RNN (GRU, LSTM),TCN,attention等结构。经过在多个数据集上的多次实验对比,我们选择了最高效,预测准确率最高的MLP,即全连接神经网络。为了增加网络的深度以学习到更复杂的时序波形,我们采取了残差连接的方式,把多个MLP模块连接到了一起。具体每个模块之间的传播方式可参见文中的公式3,4,5。
空间相关性模块
需要注意的是,时间相关性模块中,数据点信息的传播仅仅集中在了时间维度上,不同维度之间的信息并没有进行交互。在多维时间序列中,不同维度的数据常常具有相关性,利用好这些相关性可以增加预测准确度。因此,在时间相关性模块后,我们设计了空间相关性模块,我们把时间相关性模块的输出中的每一维度视为视为图中的一个节点,并送入self-attention网络中进行空间相关性学习。在图学习中,信息在图的每个节点中相互传播,以达到学习不同维度相似性的目的。空间相关性模块的传播公式可以参考文中的公式6,7,8。
输出整形模块
预测输出需要调整到用户需要的长度,因此,在网络的尾部我们加入了一个输出整形模块,这个整形模块由一个MLP模块构成,对时间维度进行操作,把时间维度的长度整形到需要的长度。
实验部分
在设计完了预处理算法以及网络结构后,我们做了大量了的实验来验证我们算法的效果。我们的实验分为预测实验,异常检测实验,消融性实验,算法效率实验四部分。
预测实验
预测实验中,我们采用了ETT等三个数据集加上electricity数据集。
baseline我们采用了近5年中一些著名的预测算法,例如LSTMa,Reformer, LogTrans, LSTNet, Informer, 以及HI (historical inertia)。其中需要注意的是,HI是发表在CIKM2021的一个对baseline的研究,它对时间序列不做任何操作,仅仅把输入作为输出(当输出长度小于输入时则需要截断)。这样的baseline的好处是不受任何参数影响,可以作为任意预测算法有效性的基本验证。
在实验结果中,我们利用MSE, MAE两个指标来评估算法预测的准确度。预测长度我们测试了端序列预测24步到长序列预测960步。粗体代表最佳结果,下划线数据代表第二好的结果。
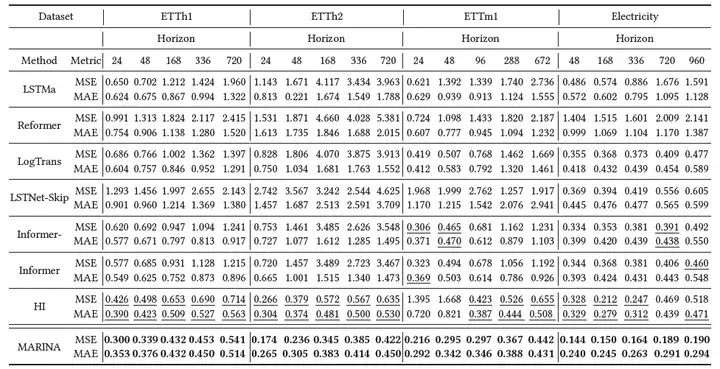
从实验结果可以看出,在所有指标上,MARINA的性能都超过了对比算法。值得一提的是HI算法的性能也超过了绝大部分对比算法。对于这一现象,我们认为是由数据导致,ETT数据集普遍都由很轻的非平稳性,以上其他的对比算法都没有对非平稳数据做处理,导致无法获得合理的预测值。
异常检测实验
异常检测实验中,我们采用了SMD, SMAP, MSL以及SMAP四个经典数据集。
对比算法中同样包含了近几年提出的著名检测算法,包含AE, EncDec-AD, GANomaly, LSTM-NDT, DAGMM, LSTM-VAE, BeatGan, OmniAnomaly, DAEMON算法。
在实验结果中,我们利用F1-score, Precision, Recall三个异常检测的准确度。
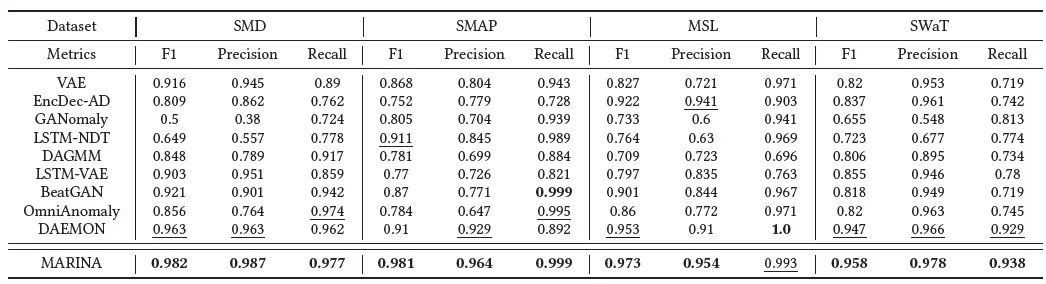
从实验结果来看,MARINA在F1-score指标上可以击败所有的对比算法。
消融性实验
在消融性实验中,我们考虑了归一化策略,时间相关性模块,空间相关性模块对算法预测效果的影响。
归一化策略
在归一化策略的消融性实验中我们对比了算法在ETTh1, ETTh2数据集上的预测结果。
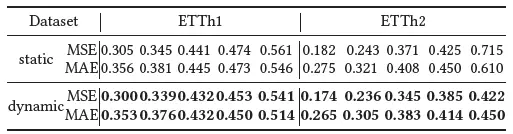
从结果中可以看出,利用动态归一化策略的预测结果均好于用普通静态归一化的预测结果。这种性能提升在ETTh2数据集上尤为明显,原因是ETTh2数据集的非平稳性更加明显。
时间相关性模块
为了证实MLP模块在时间相关性学习中的有效性,我们把MLP模块替换成了LSTM, GRU, attention, TCN四种模块,并与MLP做对比。
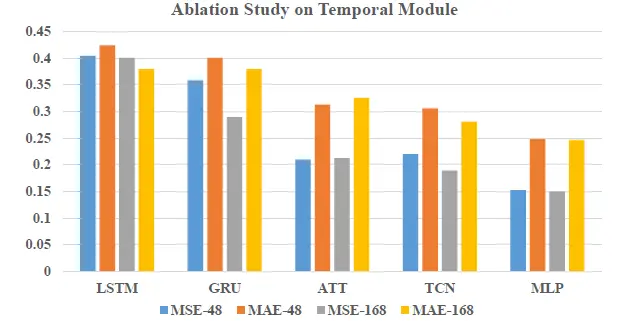
对比效果如上图所示,其中LSTM和GRU的预测效果最差,attention, TCN效果相当,但都低于MLP的预测效果。
空间相关性模块
空间相关性模块的原理是让信息在不同维度之间传递以学习不同维度之间的相关性。在对比实验中,我们对比了其余三种空间相关性模块的实现方案:MLP网络,Mix-Hop网络,无空间相关性模块。
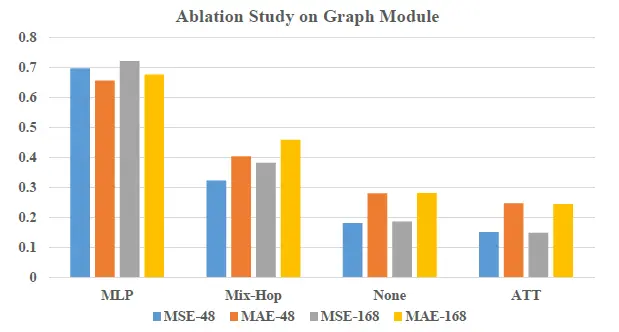
从上图的对比效果可以看出,MLP, Mix-Hop在空间相关性学习中甚至起到了反向效果,性能比没有空间相关性模块还差。self-attention网络相对于无空间相关性学习性能有一定提升。
算法效率对比
在效率对比中,我们对比了MTGNN, LSTNet, Informer, Informer-, MARINA-, MARINA的训练+预测时间。其中MARINA-是指去掉了图学习模块的MARINA。一般,在有空间相关性的多维时序数据中,图学习才能起到显著效果,在没有明显相关性的多维时序数据中,可以把图学习去掉来减少算法训练,检测时间。
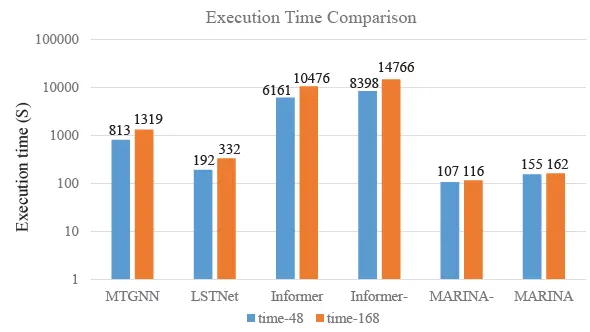
从训练+检测时间对比中可以看出,MARINA相比于主流算法消耗时间最少。在所有算法中,Informer由于其超高的复杂度,训练检测时间最高可以达到MARINA的100倍。
总结
在本论文中,我们提出了MARINA神经网络结构,该结构可以用于预测以及异常检测任务。通过充分的实验,我们可以看出,在预测和异常检测任务上,MARINA都能达到最优的效果,且在训练检测效率上,MARINA也相比对比算法能达到最高效率。由于MARINA的高效,高准确率的特点,其十分适合于云服务中海量监控时间线的场景。目前MARINA已经集成在了云数据库创新lab的时序分析算法库中。
展现领先科研实力,华为云数据库创新LAB三篇论文入选国际数据库顶级会议VLDB’2022
华为云数据库创新lab官网:https://www.huaweicloud.com/lab/clouddb/home.html
We Are Hiring:https://www.huaweicloud.com/lab/clouddb/career.html ,简历发送邮箱:xiangyu9@huawei.com
华为云数据库创新Lab 时序数据库openGemini正式开源,开源地址:https://github.com/openGemini,诚邀开源领域专家加入!
论文解读丨CIKM'22 MARINA:An MLP-Attention Model for Multivariate Time-Series Analysis的更多相关文章
- 论文解读丨基于局部特征保留的图卷积神经网络架构(LPD-GCN)
摘要:本文提出一种基于局部特征保留的图卷积网络架构,与最新的对比算法相比,该方法在多个数据集上的图分类性能得到大幅度提升,泛化性能也得到了改善. 本文分享自华为云社区<论文解读:基于局部特征保留 ...
- 论文解读丨表格识别模型TableMaster
摘要:在此解决方案中把表格识别分成了四个部分:表格结构序列识别.文字检测.文字识别.单元格和文字框对齐.其中表格结构序列识别用到的模型是基于Master修改的,文字检测模型用到的是PSENet,文字识 ...
- 论文解读丨【CVPR 2022】不使用人工标注提升文字识别器性能
摘要:本文提出了一种针对文字识别的半监督方法.区别于常见的半监督方法,本文的针对文字识别这类序列识别问题做出了特定的设计. 本文分享自华为云社区<[CVPR 2022] 不使用人工标注提升文字识 ...
- 论文解读(FedGAT)《Federated Graph Attention Network for Rumor Detection》
论文信息 论文标题:Federated Graph Attention Network for Rumor Detection论文作者:Huidong Wang, Chuanzheng Bai, Ji ...
- VLDB'22 HiEngine极致RTO论文解读
摘要:<Index Checkpoints for Instant Recovery in In-Memory Database Systems>是由华为云数据库创新Lab一作发表在数据库 ...
- 论文解读(GraphMAE)《GraphMAE: Self-Supervised Masked Graph Autoencoders》
论文信息 论文标题:GraphMAE: Self-Supervised Masked Graph Autoencoders论文作者:Zhenyu Hou, Xiao Liu, Yukuo Cen, Y ...
- 论文解读(USIB)《Towards Explanation for Unsupervised Graph-Level Representation Learning》
论文信息 论文标题:Towards Explanation for Unsupervised Graph-Level Representation Learning论文作者:Qinghua Zheng ...
- zz扔掉anchor!真正的CenterNet——Objects as Points论文解读
首发于深度学习那些事 已关注写文章 扔掉anchor!真正的CenterNet——Objects as Points论文解读 OLDPAN 不明觉厉的人工智障程序员 关注他 JustDoIT 等 ...
- NIPS2018最佳论文解读:Neural Ordinary Differential Equations
NIPS2018最佳论文解读:Neural Ordinary Differential Equations 雷锋网2019-01-10 23:32 雷锋网 AI 科技评论按,不久前,NeurI ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
随机推荐
- 微信小程序image图片自适应宽度比例显示的方法
我们都知道微信小程序的组件image是用来显示图片的,它有一下几个属性:1.src 图片资源地址2.mode 图片裁剪.缩放的模式3.binderror ...
- 一元多项式求和(c++源码)
LinkList.h #ifndef LINKLIST_H_ #define LINKLIST_H_ #include<stdio.h> template<class T> s ...
- HarmonyOS UI 开发
引言 HarmonyOS 提供了强大的 UI 开发工具和组件,使开发者能够创建吸引人的用户界面.本章将详细介绍在 HarmonyOS 中应用 JS.CSS.HTML,HarmonyOS 的 UI 组件 ...
- jenkins原理篇——成员权限管理
大家好,我是蓝胖子,前面几节我讲述了jenkins的语法以及我是如何使用jenkins对测试和正式环境进行发布的.但正式环境使用jenkins还有一点很重要,那就是权限管理.正式环境的权限往往不能对所 ...
- 25. 干货系列从零用Rust编写正反向代理,序列化之serde是如何工作的
wmproxy wmproxy已用Rust实现http/https代理, socks5代理, 反向代理, 静态文件服务器,四层TCP/UDP转发,内网穿透,后续将实现websocket代理等,会将实现 ...
- CSP-S 考前备战——常考知识点串烧
1.树形结构 与 树形dp PS :在CSP-S 2019,CSP-J 2020,CSP-S 2020,CSP-S 2021 均有考查 此类问题的做题方法就是将问题转化成树上的问题,然后进行深度优先遍 ...
- 匿名远程启动jenkins的job
安装jenkins插件Build Authorization Token Root job配置中的构建触发器,勾选触发远程构建,输入要用的令牌,如soul 通过jenkins地址调用触发 非参数化jo ...
- C++20语言核心特性的变化
using for Enumeration Values 对比一下C++20前后的区别: enum class State { open, progress, done = 9 }; // Bef ...
- Optional源码分析(涉及Objects源码和Stream源码)
研究Optional源码之前先谈一谈Objects源码. 主要代码: @ForceInline public static <T> T requireNonNull(T obj) { if ...
- tryhackme进攻性渗透测试-Advanced Exploitation 高级利用
Steel Mountain 侦察 Nmap -sC -sV -O $IP -oN basic_scan.nmap Nmap -script=vuln $IP -oN vuln_scan.nmap 总 ...