lec-6-Actor-Critic Algorithms
从PG→Policy evaluation
- 更多样本的均值+Causality+Baseline 减少variance
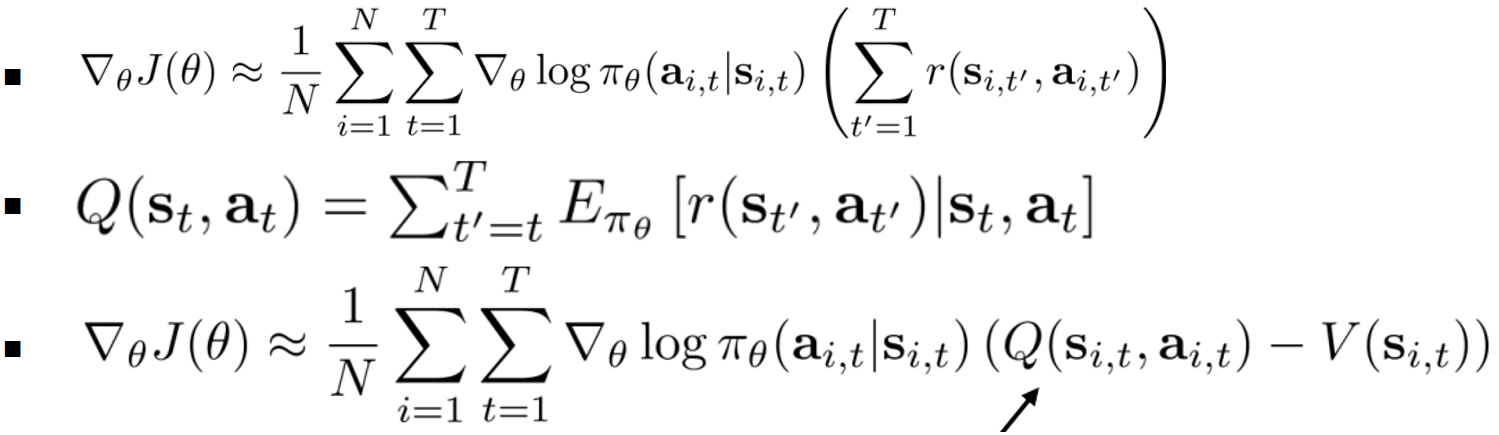
- 只要拟合估计Q、V:这需要两个网络
- Value function fitting(即策略评估)
近似: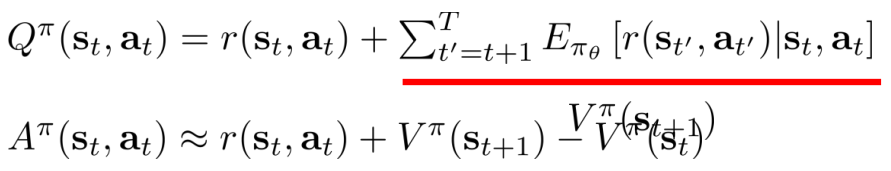
- MC evaluation
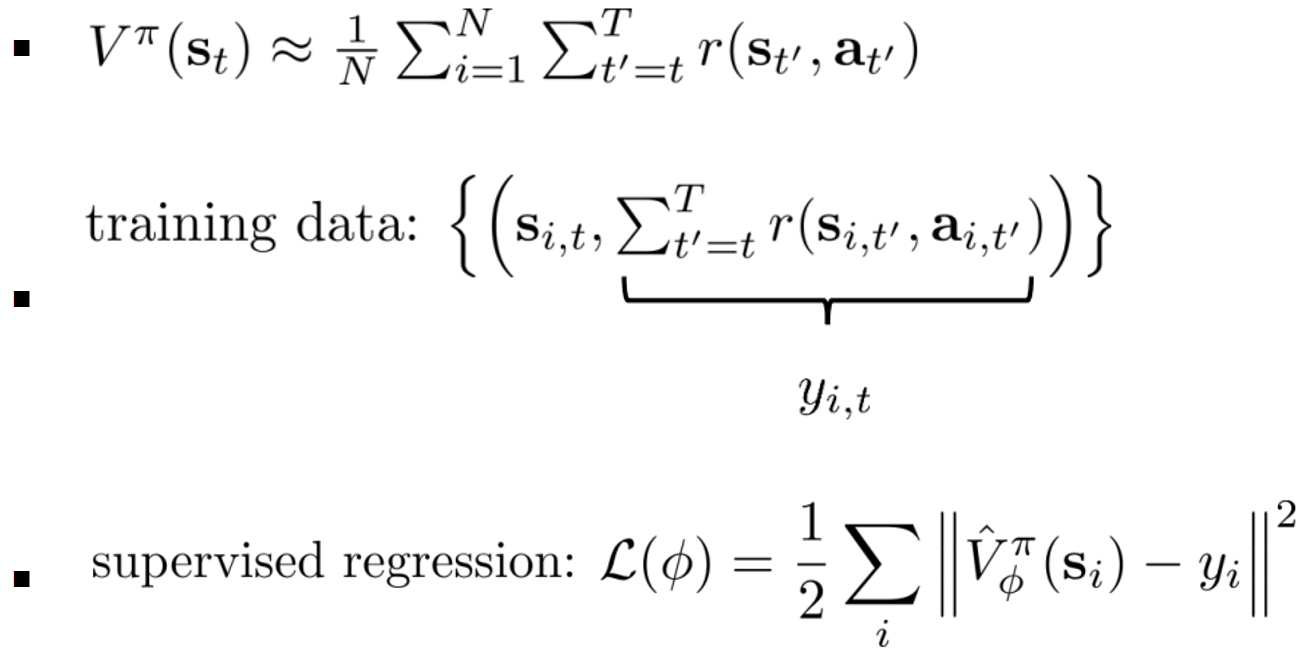
一种更好的方法:自举
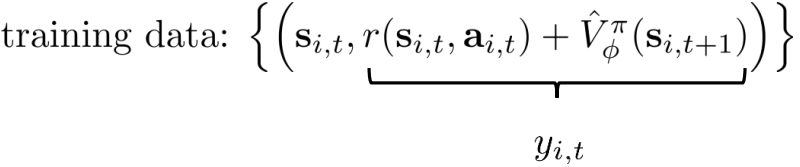
从evaluation→AC
拟合V进行评估,提升policy

- V网络的更新:
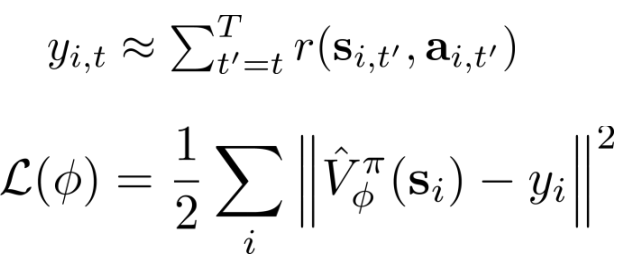
- 策略网络policy的更新:
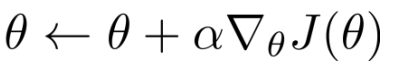
- V网络的更新:
在RL基本流程图中:
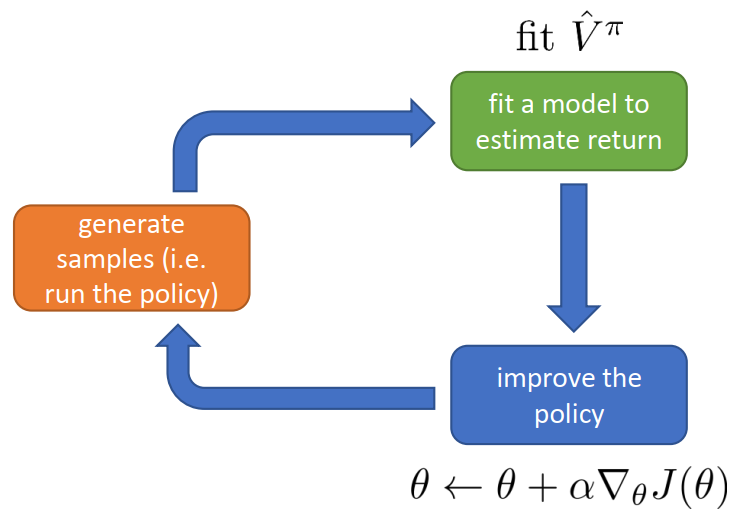
改进方法
- 折扣因子:对近期回报的偏好程度
- 折扣因子(MC方法)的分配:
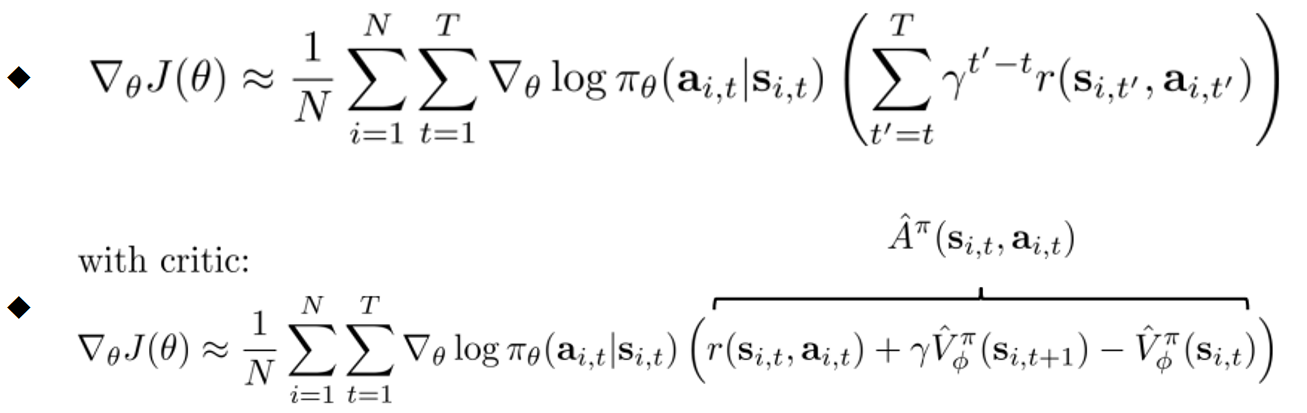
改进设计
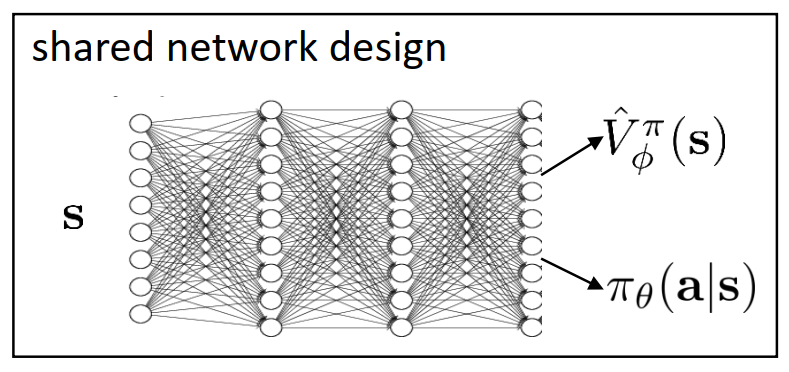
- 网络架构设计:两个独立网络变成共享网络(共享内部信息来加快训练速度)
- Online
- 同步并行A2C
- 异步并行A3C
- Offline
- Replay buffer
- 网络架构设计:两个独立网络变成共享网络(共享内部信息来加快训练速度)
Critics(V) as baselines
- 状态独立baselines(单个样本的期望估计-V):无偏,低variance
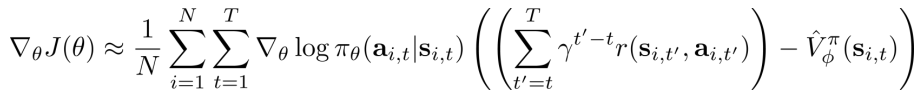
- AC:低variance,有偏(目标值和估计值都由V影响)
- PG:高variance(单样本估计),无偏
- 动作独立的baselines: 会出现不正确的
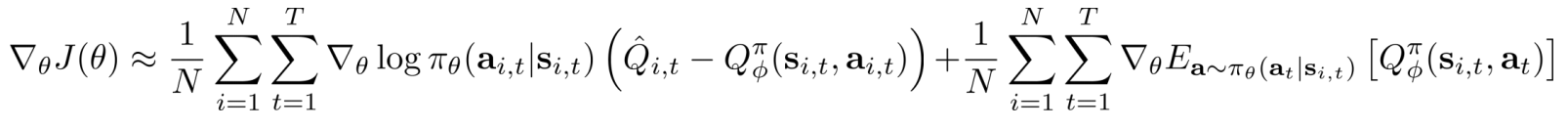
- n-step returns
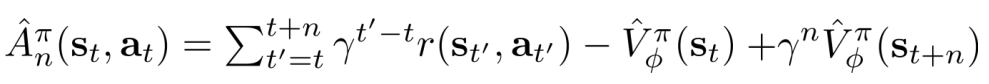
- n越大,偏差越小,方差越高
- GAE

- 状态独立baselines(单个样本的期望估计-V):无偏,低variance
Resource:CS285官网资料
版权归原作者 Lee_ing 所有
未经原作者允许不得转载本文内容,否则将视为侵权;转载或者引用本文内容请注明来源及原作者
lec-6-Actor-Critic Algorithms的更多相关文章
- 深度增强学习--Actor Critic
Actor Critic value-based和policy-based的结合 实例代码 import sys import gym import pylab import numpy as np ...
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor 20 ...
- (转) Using the latest advancements in AI to predict stock market movements
Using the latest advancements in AI to predict stock market movements 2019-01-13 21:31:18 This blog ...
- (zhuan) 一些RL的文献(及笔记)
一些RL的文献(及笔记) copy from: https://zhuanlan.zhihu.com/p/25770890 Introductions Introduction to reinfor ...
- Awesome TensorFlow
Awesome TensorFlow A curated list of awesome TensorFlow experiments, libraries, and projects. Inspi ...
- DRL强化学习:
IT博客网 热点推荐 推荐博客 编程语言 数据库 前端 IT博客网 > 域名隐私保护 免费 DRL前沿之:Hierarchical Deep Reinforcement Learning 来源: ...
- 学习笔记TF053:循环神经网络,TensorFlow Model Zoo,强化学习,深度森林,深度学习艺术
循环神经网络.https://github.com/aymericdamien/TensorFlow-Examples/blob/master/examples/3_NeuralNetworks/re ...
- David Silver强化学习Lecture1:强化学习简介
课件:Lecture 1: Introduction to Reinforcement Learning 视频:David Silver深度强化学习第1课 - 简介 (中文字幕) 强化学习的特征 作为 ...
- 强化学习--Actor-Critic---tensorflow实现
完整代码:https://github.com/zle1992/Reinforcement_Learning_Game Policy Gradient 可以直接预测出动作,也可以预测连续动作,但是无 ...
- 论文笔记:Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments
Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments 2017-10-25 16:38:23 [Proj ...
随机推荐
- 解密Prompt系列3. 冻结LM微调Prompt: Prefix-Tuning & Prompt-Tuning & P-Tuning
这一章我们介绍在下游任务微调中固定LM参数,只微调Prompt的相关模型.这类模型的优势很直观就是微调的参数量小,能大幅降低LLM的微调参数量,是轻量级的微调替代品.和前两章微调LM和全部冻结的pro ...
- Javaweb基础复习------Cookie+Session案例的实现(登录注册案例)
Cookie对象的创建--Cookie cookie=new Cookie("key","value"); 发送Cookie:resp.addCookie(); ...
- web初始:html记忆
12.13html框架 <! DOCTYPE html> <html lang="zh-CN"> <head> <meta charset ...
- (数据科学学习手札150)基于dask对geopandas进行并行加速
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,geopandas作为我们非常 ...
- Mybatis分页插件PageHelper的配置及使用方法
尊重人家的知识成果 推荐 该作者总结的不错! --->> --->> @author 扎心了老铁 Mybatis分页插件PageHelper的配置及使用方法
- 简单入门echart方法
图表用echart, 然后前端的 HTML 跟 nodejs , nodejs 去调用 后端PHP的接口 链接:https://www.jianshu.com/p/1f2c37c5c02f 官网:h ...
- 谁能真正替代你?AI辅助编码工具深度对比(chatGPT/Copilot/Cursor/New Bing)
写在开头 这几个月AI相关新闻的火爆程度大家都已经看见了,作为一个被裹挟在AI时代浪潮中的程序员,在这几个月里我也是异常兴奋和焦虑.甚至都兴奋的不想拖更了.不仅仅兴奋于AI对于我们生产力的全面提升,也 ...
- vue 之 computed方法自带缓存踩坑1
使用场景:ant-vue 穿梭框使用 页面使用computed方法处理组织结构数据,退出页面时,对加载数据做了set null 操作,再次进入页面时,穿梭框只显示数据,无法做左右穿梭功能. 原因:co ...
- 【Spring专题】「技术原理」从源码角度去深入分析关于Spring的异常处理ExceptionHandler的实现原理
ExceptionHandler的作用 ExceptionHandler是Spring框架提供的一个注解,用于处理应用程序中的异常.当应用程序中发生异常时,ExceptionHandler将优先地拦截 ...
- 高可用(keepalived)部署方案
前言:为了减少三维数据中心可视化管理系统的停工时间,保持其服务的高度可用性.同时部署多套同样的三维可视化系统,让三维数据中心可视化系统同时部署并运行到多个服务器上.同时提供一个虚拟IP,然后外面通过这 ...