火山引擎 DataTester:0 代码也能实施 A/B 测试的实验平台
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群
近日,火山引擎 DataTester 对 A/B 实验“可视化编辑器”进行了升级,可视化编辑器功能让用户无需编写任何代码,即可在网站或相关产品页面上进行基本的视觉更改,并发起 A/B 实验。
升级后, DataTester 可视化编辑器具有如下新特性:
交互方式优化,页面和实验切换,选择元素可视化编辑,聚焦更顺畅的操作
减少刷新初始化内容,让刷新加载更快捷
沉浸式的预览体验,避免干扰因素影响
Xpath 的层次结构视图,让层级展示更清晰
火山引擎 DataTester 的“可视化编辑器”功能可支持多种类型的 A/B 实验设计,本文将详细介绍其支持的“MVT 多变体可视化实验”功能。
多变体可视化实验(简称 MVT,全称 Multi-variate Visual Test)是同时对一个网页的两个或多个元素变体进行 A/B 实验,以查看哪个组合策略可以产生最好的结果,DataTester 新版“可视化编辑器”让多变体可视化实验的实施更加便捷。
据介绍,多变体可视化实验中的元素(Element),指的是页面中的元素,如页面按钮位置、样式、颜色等,DataTeater 支持针对页面中的多个元素进行 A/B 实验。变体(variant)是针对页面元素中的修改,元素进行修改内容和样式保存之后就是变体。而组合(combination)则是指实验组,即一个元素下可以有多个变体,一个变体下有同一个元素不同修改,元素中不同的变体相互交叉组成的一个版本。
举例而言,如果正在对 3 个元素进行 A/B 测试,每个元素分别有 2 个、3 个、4 个变体,每个变体下都有不同的元素修改内容和样式,则一共有 24 种组合 (2x3x4)。在 DataTester 中即可直接开启 24 组实验,并观测结果。
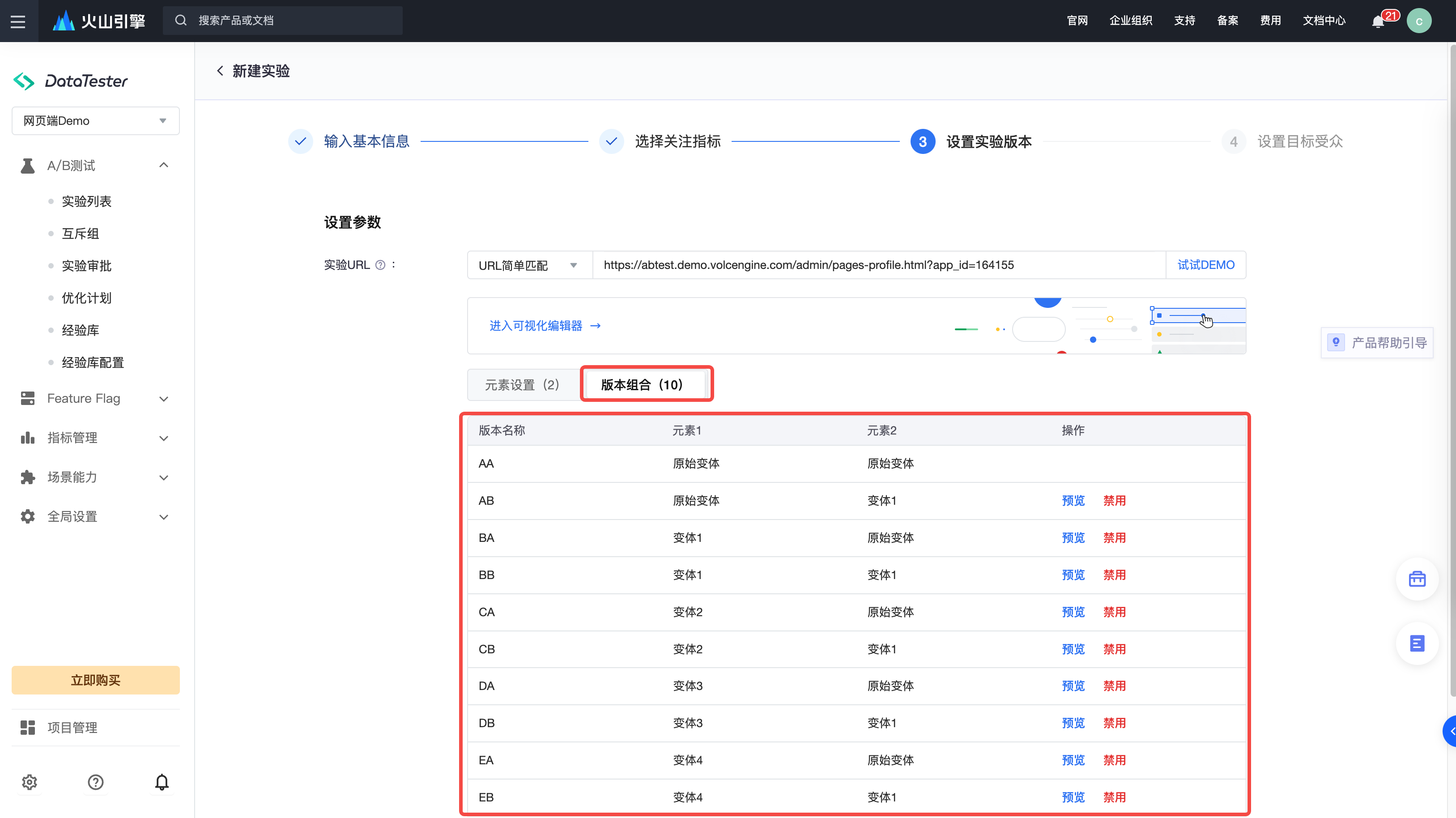
用户在 DataTester 中输入目标网页 URL 后,即可点击进入“可视化编辑器”。DataTester 将基于网站原页面打开可视化编辑器。网页元素配置入口,在可视化编辑器的右上角有 Tooltip 提示,可直接进行元素拖拽操作。
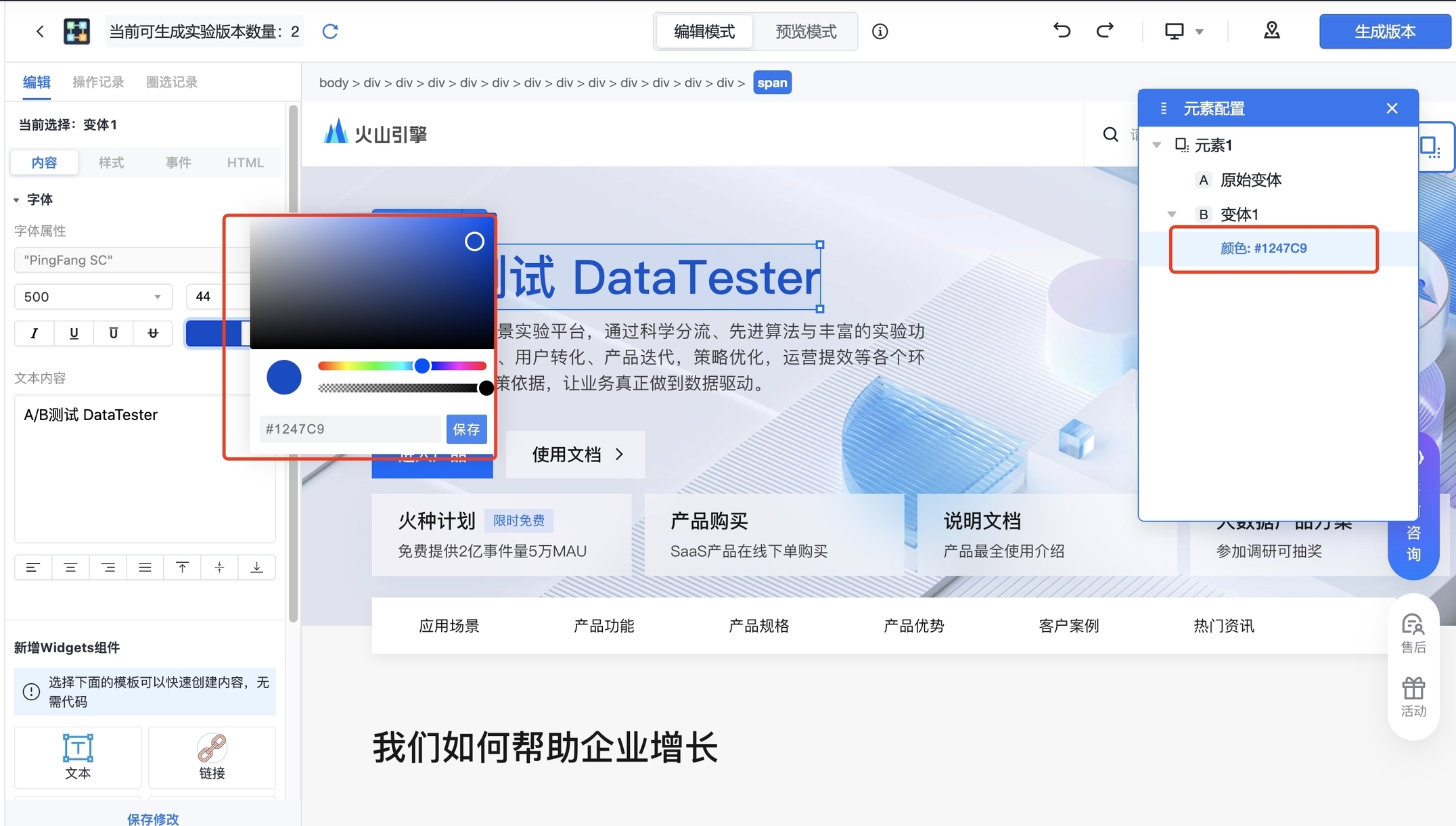
在 DataTester 中选择变体之后,左侧看板联动,显示当前对应的元素和变体,便于用户直接对选中元素进行编辑。如下图所示,支持可视化编辑元素文本、颜色、字体、样式等。
DataTester 多变体可视化实验适用于如下场景:
当 Web 网站/H5/APP 访问量较高时,运行多变体实验尤为有用且有效。
当用户有一个策略假设可以通过多种方式实现变体,但无法决定该测试哪种组合时,则适合多变体实验验证。
DataTester 是火山引擎数智平台旗下产品,作为字节跳动内部使用多年的 A/B 测试平台,DataTester 有支持多种复杂 A/B 实验及精准科学的分流能力,能够深度耦合推荐、广告、搜索、UI、产品功能等多种业务场景需求,为业务增长、转化、产品迭代,策略优化,运营提效等各个环节提供科学的决策依据。
目前,火山引擎 DataTester 已经服务了美的、得到、凯叔讲故事等在内的上百家标杆客户,将成熟的 “数据驱动增长 ” 经验赋能给各行业。
点击跳转火山引擎A/B测试DataTester官网了解详情!
火山引擎 DataTester:0 代码也能实施 A/B 测试的实验平台的更多相关文章
- 火山引擎 DataTester:让企业“无代码”也能用起来的 A/B 实验平台
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 当数字化变革方兴未艾,无代码正受到前所未有的关注.Salesforce 的数据显示,52%的 IT 部门表示,公司 ...
- 还原火山引擎 A/B 测试产品——DataTester 私有化部署实践经验
作为一款面向ToB市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向ToB客户私有化的实际落地中,火 ...
- 火山引擎 A/B 测试产品——DataTester 私有化架构分享
作为一款面向 ToB 市场的产品--火山引擎A/B测试(DataTester)为了满足客户对数据安全.合规问题等需求,探索私有化部署是产品无法绕开的一条路. 在面向 ToB 客户私有化的实际落地中,火 ...
- 火山引擎MARS-APM Plus x 飞书 |降低线上OOM,提高App性能稳定性
通过使用火山引擎MARS-APM Plus的memory graph功能,飞书研发团队有效分析定位问题线上case多达30例,线上OOM率降低到了0.8‰,降幅达到60%.大幅提升了用户体验,为飞书的 ...
- 火山引擎 DataLeap 的 Data Catalog 系统公有云实践
Data Catalog 通过汇总技术和业务元数据,解决大数据生产者组织梳理数据.数据消费者找数和理解数的业务场景.本篇内容源自于火山引擎大数据研发治理套件 DataLeap 中的 Data Ca ...
- 火山引擎 DataLeap:一家企业,数据体系要怎么搭建?
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 导读:经过十多年的发展,数据治理在传统行业以及新兴互联网公司都已经产生落地实践.字节跳动也在探索一种分布式的数据治 ...
- [19/04/19-星期五] Java的动态性_脚本(Script,脚本)引擎执行JavaScript代码
一.概念 Java脚本引擎是jdk 6.0之后的新功能. 使得Java应用程序可以通过一套固定的接口与各种脚本引擎交互,从而达到在Java平台上调用各种脚本语言的目的. Java脚本API是连接Jav ...
- Scut游戏服务器引擎6.0.5.0发布-支持C#脚本
1. 增加C#脚本支持2. 增加Pay和Sns中间件对Mysql数据库支持3. 精简布署步骤,取消Redis写入程序,将其移到游戏底层运行4. 修正Mysql对中文可能会出现乱码的BUG 点击下载:S ...
- 火山引擎 DataLeap:3 个关键步骤,复制字节跳动一站式数据治理经验
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,并进入官方交流群 DataLeap 是火山引擎数智平台 VeDI 旗下的大数据研发治理套件产品,帮助用户快速完成数据集成.开发.运维.治理. ...
- JuiceFS 在火山引擎边缘计算的应用实践
火山引擎边缘云是以云计算基础技术和边缘异构算力结合网络为基础,构建在边缘大规模基础设施之上的云计算服务,形成以边缘位置的计算.网络.存储.安全.智能为核心能力的新一代分布式云计算解决方案. 01- 边 ...
随机推荐
- vscode编写keil工程项目
vscode 前言 1 安装vscode 2 安装插件 2.1 设置中文 2.2 安装Keil Assistant 2.3 常用安装 3 快捷键 前言 我使用vscode只是用来为了弥补keil编写的 ...
- 如何解决Asp.Net Core 3.1上传文件出现跨域
这个问题挺奇怪的,明明就是文件过大的问题,却出现了跨域的错误,搞不懂,有了解的大佬请指教. 但问题还是解决了,其实就是Nginx默认上传大小限制为1M,如果超出了,则出现跨域的错误. 一.自定义Ngi ...
- [Python急救站课程]温度转换程序
华氏温度转换为摄氏度的温度转换程序共有三种写法 一.简单的温度转换程序 TempStr = input("请输入带有符号的温度值: ") # TemStr表示命令,表示占位符.=为 ...
- 【pwn】ez_pz_hackover_2016 --pwngdb和pwntools的结合,动态调试
首先checksec 没开nx,说明堆栈可执行,初步考虑需要shellcode,然后拖进ida看主函数逻辑 看chall函数 printf("Yippie, lets crash: %p ...
- 两个对于电影片段的情绪研究(中国&国外)
1.国内的研究(A new standardized emotional film database for Asian culture) 测试片使用了8种情绪类型,每部片子有4个维度的分数,分数是从 ...
- Net 高级调试之九:SOSEX 扩展命令介绍
一.介绍 今天是<Net 高级调试>的第九篇文章.这篇文章设计的内容挺多的,比如:扩展的断点支持,如何查找元数据,栈回溯,对象检查,死锁检测等等,内容挺多的.功能特别强大,使用特别方便,但 ...
- 最小的k个数 (3.20 leetcode每日打卡)
输入整数数组 arr ,找出其中最小的 k 个数.例如,输入4.5.1.6.2.7.3.8这8个数字,则最小的4个数字是1.2.3.4. 示例 1: 输入:arr = [3,2,1], k = 2 输 ...
- 分享我对DiscuzQ这款现代化开源轻社区的二次开发成果。DiscuzQ依然是站长的最佳选择!
简要说一下二开的功能:贴文列表样式优化.增加国内 AI 大模型功能.增加社区 AI 助手(会自动发帖和回帖).编辑器功能优化.pc 端导航优化.h5 端导航优化.修复各种加载不出来加载缓慢的问题等等细 ...
- 通过计算巢轻松部署 Ansible Semaphore
概述 Ansible Semaphore 是一个现代化的 Ansible 用户界面.可以轻松运行 Ansible Playbook,获取有关失败的通知,并控制部署系统的访问权限.如果你的项目已经发展壮 ...
- [ABC280G] Do Use Hexagon Grid 2
Problem Statement A hexagonal cell is represented as $(i,j)$ with two integers $i$ and $j$. Cell $(i ...