【python爬虫】 request模块介绍 http协议版本区别 双token认证 携带cookie的两种方式 requests.session的使用 post请求携带数据编码格式 request.text编码问题 下载图片,视频
上节回顾
# 1 上线架构图
# 2 购买云服务器
# 3 远程链接云服务器
-xshell
-fianlshell
# 4 安装mysql
-下载rpm包
-安装
-修改root用户密码
# 5 redis 源码
-在不同平台编译
-make make install
-做软连接:
# 6 python3.8
-安装前置软件
-下载源码包
-解压
# 7 安装uwsgi
# 8 安装虚拟环境
# 9 安装Nginx
1)启动
>: nginx
2)关闭nginx
>: nginx -s stop
3)重启nginx
>: nginx -s reload
4)查看端口,强行关闭
>: ps -aux|grep nginx
>: kill <pid:进程编号>
# 10 上线前端
编译vue:npm run build---》dist文件夹下
传到服务器:lrzsz
解压zip :unzip
copy到 /home/html
修改nginx配置文件,让它能够代理前端静态文件
# 11 后端上线
-修改后的代码,提交到git上
-云服务器:git clone下来
-logs文件必须要有
-安装所有依赖:先装能装的
-uwsgi上线:虚拟环境也要装
-uwsgi配置文件
-nginx 增加一个新增的server
# 12 数据库配置
-创建数据库
-新增用户
-录入数据
# 13 处理前端静态资源
STATIC_ROOT = ''
python manage_prod.py collectstatic
nginx代理
# 14 域名解析
# 开源项目赏析
https://gitee.com/huap/projects
# 可以写的项目
-1 考试系统
-学生端:
签到签退功能:人脸识别签到,迟到,忘记签到
-补签:老师审批
-日历
考试功能:
-每天早上:考试 10分钟 考昨天学过的内容
-选择题,填空题,简单题---》选择和填空自动阅卷
-简单版 简单题老师打分
-高级版:提交后,同学匿名互相阅卷---》1
-自动阅卷:网上有自动阅卷的方法
-考试分数高有积分功能
-错题本
刷题功能:
-面向对象,网络编程,生成一套试卷,刷题
积分功能
-考试成绩高
-积分兑换功能:学长简历,学长面试录音,学长笔试题带答案
-老师端
-每个班同学签到情况:echars画图
-阅卷
-修改分数
-超级管理员端
-老师和学生管理
-excel导入
-2 有过其他工作经历
-之前使用过的系统,想一下实现
-需求:仓储管理系统---》下午发给你们
-海运管理系统
-医院的管理系统
-会籍管理,客户管理 ,游泳馆:crm 客户关系管理
-3 开心幼儿园:app,幼儿园管理的app
-4 小程序商城,商城app
-二手汽车商城
-二手交易
-5 自动化运维的
-psutils
-paramiko:https://www.cnblogs.com/liuqingzheng/p/13642948.html
-6 自动化测试
-7 觉得哪个项目不错,仿写
-二次元 视频播放
-看漫画app
-小说网站
-8 rbac权限管理系统
-使用别人前端
-自己写后端
-9 数字藏品
-10 微信点单 奈雪的茶 小程序
今日内容
1 爬虫介绍
# 爬虫是什么
-爬虫就是程序---》从互联网中,各个网站上,爬取数据[你能浏览的页面才能爬],做数据清洗,入库
# 爬虫的本质
-现在所有的软件原理:大部分都是基于http请求发送和获取数据的
-pc端的网页
-移动端app
-模拟发送http请求,从别人的服务端获取数据
-绕过反扒:不同程序反扒措施不一样,比较复杂
# 爬虫原理
-发送http请求【requests,selenium】----》第三方服务端----》服务端响应的数据解析出想要的数据【selenium,bs4】---》入库(文件,excel,mysql,redis,mongodb。。)
-scrapy:专业的爬虫框架
# 爬虫是否合法
-爬虫协议:每个网站根路径下都有robots.txt,这个文件规定了,该网站,哪些可以爬取,哪些不能爬
# 补充:百度其实就是一个大爬虫
-百度爬虫一刻不停的在互联网中爬取各个页面---》爬取完后---》保存到自己的数据库中
-你在百度搜索框中搜索---》百度自己的数据库查询关键字---》返回回来
-点击某个页面----》跳转到真正的地址上
-核心:搜索,海量数据中搜索出想要的数据
-seo:免费的搜索,排名靠前
-sem:花钱买关键字
# 内容概述
-模拟发送http请求
- requests模块
- selenium
-反扒:封ip:ip代理,封账号:cookie池
-解析数据:bs4
-入库:mysql,redis,文件中
-爬虫框架:scrapy
2 request模块介绍
# 使用python如何发送http请求
# 模块:requests模块,封装了python内置模块urllib
使用requests可以模拟浏览器的请求(http),比起之前用到的urllib,requests模块的api更加便捷(本质就是封装了urllib3)
# 安装
pip3 install requests
# 简单使用
import requests
res=requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html')
print(res.text) # http响应体的文本内容
3 request发送get请求
import requests
#
# res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html')
# print(res.text)
# 如果有的网站,发送请求,不返回数据,人家做了反扒---》拿不到数据,学习如何反扒
# res = requests.get('https://dig.chouti.com/')
# print(res.text)
4 request携带参数
import requests
# 方式一:直接拼接到路径中
# res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html?name=lqz&age=19')
# 方式二:使用params参数
res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html',params={'name':"lqz",'age':19})
# print(res.text)
print(res.url)
5 url编码解码
import requests
from urllib.parse import quote,unquote
# res = requests.get('https://www.cnblogs.com/liuqingzheng/p/16005866.html',params={'name':"彭于晏",'age':19})
# # print(res.text)
#
# # 如果是中文,在地址栏中会做url的编码:彭于晏:%E5%BD%AD%E4%BA%8E%E6%99%8F
# print(res.url)
# 'https://www.baidu.com/s?wd=%E5%B8%85%E5%93%A5'
# 编码:
# res=quote('彭于晏')
# print(res)
# 解码
res=unquote('%E5%BD%AD%E4%BA%8E%E6%99%8F')
print(res)
6 携带请求头
# 反扒措施之一,就是请求头
# http请求中,请求头中有一个很重要的参数 User-Agent
-表明了客户端类型是什么:Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36
-request发送请求,没有携带该参数,所以有的网站就禁止了
-后端使用中间件判断是否携带某些请求头,如果没有携带该参数就禁止该请求。
import requests
# http请求头:User-Agent,cookie,Connection
# http协议版本间的区别
# Connection: keep-alive
# http协议有版本:主流1.1 0.9 2.x
# http 基于TCP 如果建立一个http链接---》底层创建一个tcp链接
# 1.1比之前多了keep-alive
# 2.x比1.x多了 多路复用
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
res = requests.get('https://dig.chouti.com/',headers=headers)
print(res.text)
http协议版本之间的区别
http 0.9:两个请求 两个tcp链接(浪费资源)
# http 0.9 --添加keep-alive请求头-> 1.1
http 1.1:短时间实现了多次请求共用一个TCP链接(多请求复用)
# http 1.x --添加多路复用--> http 2.x
http 2.x 的一个tcp链接 可以传输多个http请求!效率更高 多个http请求可以共用一个tcp链接包。http请求包在一个包里但是可以分开!
http 3.0 底层基于udp
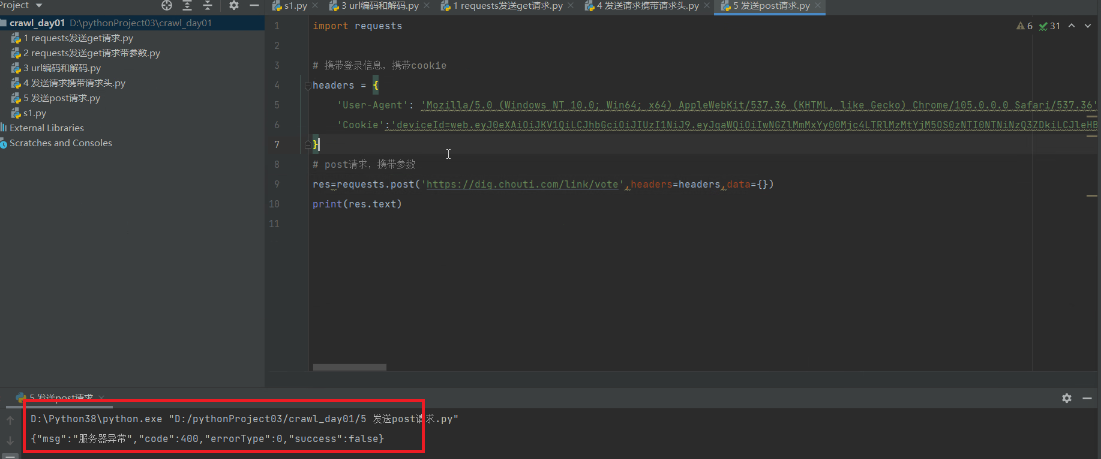
7 发送post请求,携带数据
import requests
# 携带登录信息,携带cookie
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36',
'Cookie': ''
}
# post请求,携带参数
data = {
'linkId': '38063872'
}
res = requests.post('https://dig.chouti.com/link/vote', headers=headers, data=data)
print(res.text)
# 双token认证
对于某接口发送post请求
示例是:点赞接口
不携带请求头:被防火墙拦下
不携带cookies: 返回登录页面,让你去登录
携带cookies: 服务器异常(post请求未携带参数)
post请求携带参数:成功访问接口
双token认证
- token被截获怎么保证安全?
# 方式一
使用双token认证。长token短token 令截获到的token快速过期
# 方式二
在token里面加上当前登录的IP地址,如果被别人拿到了,对比一下IP
8 自动登录,携带cookie的两种方式
# 登录功能,一般都是post
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
res = requests.post('http://www.aa7a.cn/user.php',data=data)
print(res.text)
# 响应中会有登录成功的的cookie,
print(res.cookies) # RequestsCookieJar 跟字典一样
# 拿着这个cookie,发请求,就是登录状态
# 访问首页,get请求,携带cookie,首页返回的数据一定会有 我的账号
# 携带cookie的两种方式:
# 方式一是字符串(带在请求头)、方式二是字典或CookieJar对象
# 方式二:放到cookie参数中
res1=requests.get('http://www.aa7a.cn/',cookies=res.cookies)
print('616564099@qq.com' in res1.text)
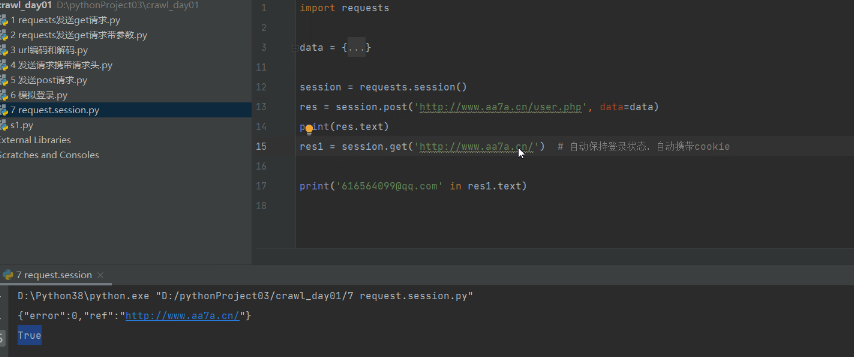
9 requests.session的使用
# 为了保持cookie ,以后不需要携带cookie
import requests
data = {
'username': '',
'password': '',
'captcha': '3456',
'remember': 1,
'ref': 'http://www.aa7a.cn/',
'act': 'act_login'
}
session = requests.session()
res = session.post('http://www.aa7a.cn/user.php', data=data)
print(res.text)
res1 = session.get('http://www.aa7a.cn/') # 自动保持登录状态,自动携带cookie
print('616564099@qq.com' in res1.text)
可以自动维护cookies。
10 补充post请求携带数据编码格式
import requests
# data对应字典,这样写,编码方式是urlencoded
requests.post(url='xxxxxxxx',data={'xxx':'yyy'})
# json对应字典,这样写,编码方式是json格式
requests.post(url='xxxxxxxx',json={'xxx':'yyy'})
# 终极方案,编码就是json格式
requests.post(url='',
data={'':1,},
headers={
'content-type':'application/json'
})
'''
调用第三方服务接口,可能会这样使用。
注意:get请求没有编码格式。
'''
11 响应Response对象
# Response相应对象的属性和方法
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
respone=requests.get('http://www.jianshu.com',headers=headers)
# respone属性
print(respone.text) # 响应体转成了字符串
print(respone.content) # 响应体的二进制内容
print(respone.status_code) # 响应状态码
print(respone.headers) # 响应头
print(respone.cookies) # cookie是在响应头,cookie很重要,它单独做成了一个属性
print(respone.cookies.get_dict()) # cookieJar对象---》转成字段
print(respone.cookies.items()) # cookie的键值对
print(respone.url) # 请求地址
print(respone.history) # 不用关注
print(respone.encoding) # 响应编码格式
'''响应头里面有cookies.'''
12 编码问题
# 有的网站,打印
res.text --->发现乱码---》请求回来的二进制---》转成了字符串---》默认用utf8转---》
# request.text会默认帮你转成utf-8
response.encoding='gbk'
再打印res.text它就用gbk转码
13 下载图片,视频
import requests
# res=requests.get('http://pic.imeitou.com/uploads/allimg/230224/7-230224151210-50.jpg')
# # print(res.content)
# with open('美女.jpg','wb') as f:
# f.write(res.content)
#
res=requests.get('https://vd3.bdstatic.com/mda-pcdcan8afhy74yuq/sc/cae_h264/1678783682675497768/mda-pcdcan8afhy74yuq.mp4')
with open('致命诱惑.mp4','wb') as f:
for line in res.iter_content(): # 视频可能很大、所有需要逐行存储:
f.write(line)
练习
图片防盗链:如何解决?
【python爬虫】 request模块介绍 http协议版本区别 双token认证 携带cookie的两种方式 requests.session的使用 post请求携带数据编码格式 request.text编码问题 下载图片,视频的更多相关文章
- Python与数据库[2] -> 关系对象映射/ORM[2] -> 建立声明层表对象的两种方式
建立声明层表对象的两种方式 在对表对象进行建立的时候,通常有两种方式可以完成,以下是两种方式的建立过程对比 首先导入需要的模块,获取一个声明层 from sqlalchemy.sql.schema i ...
- python 爬虫 urllib模块介绍
一.urllib库 概念:urllib是Python自带的一个用于爬虫的库,其主要作用就是可以通过代码模拟浏览器发送请求.其常被用到的子模块在Python3中的为urllib.request和urll ...
- python 爬虫 urllib模块 目录
python 爬虫 urllib模块介绍 python 爬虫 urllib模块 url编码处理 python 爬虫 urllib模块 反爬虫机制UA python 爬虫 urllib模块 发起post ...
- Python爬虫教程-08-post介绍(百度翻译)(下)
Python爬虫教程-08-post介绍(下) 为了更多的设置请求信息,单纯的通过urlopen已经不太能满足需求,此时需要使用request.Request类 构造Request 实例 req = ...
- Python爬虫教程-07-post介绍(百度翻译)(上)
Python爬虫教程-07-post介绍(百度翻译)(上) 访问网络两种方法 get: 利用参数给服务器传递信息 参数为dict,使用parse编码 post :(今天给大家介绍的post) 一般向服 ...
- python爬虫 urllib模块url编码处理
案例:爬取使用搜狗根据指定词条搜索到的页面数据(例如爬取词条为‘周杰伦'的页面数据) import urllib.request # 1.指定url url = 'https://www.sogou. ...
- Python 爬虫利器 Selenium 介绍
Python 爬虫利器 Selenium 介绍 转 https://mp.weixin.qq.com/s/YJGjZkUejEos_yJ1ukp5kw 前面几节,我们学习了用 requests 构造页 ...
- python 时间time模块介绍和应用
1.其中format_string 类型的时间和struct_time之间可以转换,timestamp时间戳可以和struct_time之间进行转化,但是时间戳和格式化时间是不能直接转换的. time ...
- 基础知识:编程语言介绍、Python介绍、Python解释器安装、运行Python解释器的两种方式、变量、数据类型基本使用
2018年3月19日 今日学习内容: 1.编程语言的介绍 2.Python介绍 3.安装Python解释器(多版本共存) 4.运行Python解释器程序两种方式.(交互式与命令行式)(♥♥♥♥♥) 5 ...
- python模块的导入的两种方式区别详解
Python 有两种导入模块的方法.两种都有用,你应该知道什么时候使用哪一种方法.一种方法,import module,另一种是from module import,下面是 from module i ...
随机推荐
- 本地Stackedit Markdown编辑器设置远程访问
StackEdit是一个受欢迎的Markdown编辑器,在GitHub上拥有20.7k Star!,它支持将Markdown笔记保存到多个仓库,包括Gitee.GitHub和Gitea.此在线笔记工具 ...
- Leetcode旋转图像
上C语言代码,矩阵先转置再左右对称就是旋转图像的答案啦 void rotate(int** matrix, int matrixSize, int* matrixColSize){ int i,j,n ...
- 【报错:For input string: ""报错: get connection error! 报错:java.lang.NullPointerException 报错:java.lang.NumberFormatException: For input string: "id"】解决方案
原因:没有input数据进入,但是当我填写数据进入的时候 get connection error! 这个消息,是我要抛出去的异常,源代码下 我一开始觉得是代码书写的问题,找.......... 应该 ...
- weblogic端口号和内存怎么修改?
在WebLogic中修改端口号和内存分配是一项重要的任务,它涉及到服务器性能和应用程序的可靠性.下面我将详细介绍如何修改WebLogic的端口号和内存设置. 修改端口号 WebLogic使用多个端口来 ...
- keil 5 安装教程
一.下载 keil 官网 二.安装教程 1.开始安装 双击安装包,开始安装,直接下一步 2.勾选同意,下一步 3.选择软件安装路径,下一步 4.填写信息 可以随意填写,下一步. 5.等待安装 6.安装 ...
- mysql之慢sql配置与分析
mysql的慢查询sql是通过日志记录慢SQL--(俗称慢查询日志)默认的情况下,MySQL数据库不开启慢查询日志(slow query log),需要手动把它打开 开启慢查询日志 SET GLOBA ...
- 吉特日化MES & SQL Server 无法执行数据库脚本
打开服务器打算远程执行一下脚本,突发发现数据库无法执行脚本,就想着是不是安装了 海康AGV 控制系统的问题导致,问题如下: 问题截图如下: 报错信息如下: ====================== ...
- MySQL运维10-Mycat分库分表之一致性哈希分片
一.一致性哈希分片 一致性哈希分片的实现思路和我们之前介绍的水平分表中的取模分片是类似的.只不过取模分片,采用的是利用主键和分片数进行取模运算,然后根据取模后的结果,将数据写入到不同的分片数据中.但是 ...
- LR(0)分析法
LR(0)是一种自底向上的语法分析方法.两个基本动作是移进和规约. 具体例子如下 已知文法G[E] (1) E→aА (2) E→bB (3) A→cА (4) A→d (5) B→cB (6) B→ ...
- nginx下的proxy_pass使用
之前的文章说到了,return,rewrite的使用,以及它们的使用场景,今天再来说一种代理的使用,proxy_pass,它属于nginx下的ngx_http_proxy_module模块,没有显示的 ...