【论文阅读】Causal Imitative Model for Autonomous Driving
Sensor/组织: EPFL Sharif University of Technology
Status: Finished
Summary: 看看框架图就行。高效缓解因果混淆问题,将因果作为学习输出前一层进行判断
Type: arXiv
Year: 2021
参考与前言
主页:
Causal Imitative Model for Autonomous Driving
arxiv地址:
1. Motivation
模仿学习是一种通过利用来自专家驾驶员演示的数据来学习自动驾驶策略的强大方法。然而,通过模仿学习训练的驾驶策略忽略了专家演示的因果结构会产生两种不良行为:inertia and collision
问题场景
参考文献[9] 提出:
- 对于罕见事件的weak performance →datasets bias
- 对于学习策略的高方差 → stochastic learning
- 对于因果混淆问题 → 缺乏 explicit causal model
而这篇文章主要解决的就是第三点 → 提出 causal model,接下来是更为明确的问题场景
inertia problem
在这篇 [9] 提出的问题并没有针对性解决 ICCV2019: Exploring the Limitations of Behavior Cloning for Autonomous Driving
这篇文章主要把inertia problem看做是因果混淆问题 causality 在[10] 中提出了这点但是因为算法复杂度与latent variable是指数级别增长,所以对于自动驾驶来说 [10] 解法可能还是太贵了
有空再套娃 [10] 看看怎么解决因果混淆问题的 Dagger
[10] 摘要部分:通过有针对性的干预——环境交互或专家查询——来确定正确的因果模型来解决因果混淆问题。 我们表明,因果错误识别发生在几个基准控制域以及现实驾驶设置中,并针对 DAgger 和其他基线和消融验证我们的解决方案
collision problem
主要是训练好的agent 并没有躲避其他车辆,就是和其他车辆撞上了
总结起来,论文指出应该要同时考虑这两个东西,因为如果分开考虑的话,就很有可能为了避免一方而牺牲一方,例如:为了解决inertia问题,一种trick是可以在某些情况下加速 开油门; 然而,这样很有可能导致撞车
Contribution

简单图 主要contribution 在高亮 cause discovery 处
在本文中,我们提出了因果模仿模型(CIM)来解决 inertia 和 collision problem。 CIM 显式发现因果模型并利用它来训练策略。 具体来说,CIM 将输入分解为一组 latent variables ,选择因果变量,并通过利用所选变量确定下一个位置。 我们的实验表明,我们的方法在惯性和碰撞率方面优于以前的工作。
此外,由于利用了因果结构,CIM 将输入维度缩小到只有两个,因此可以在几次设置中适应新环境。
2. Method
notation:
- \(t\) 时间步数
- \(O^t\) 高维的 scense 观测
- \(\mathcal T^t\) 专家的未来轨迹
- 专家策略生成的专家轨迹:\(\mathcal T ∼ \pi(\cdot|O)\)
- 我们想使用 \((O^t,\mathcal T^t)\) 来近似出来一个策略 \(\pi\)
模仿学习最简单的形式就是行为克隆 behavior cloning,也把policy learning问题变成了一个监督学习,在这个过程中 是 \(\pi\) 直接将 \(O\) 映射得到 \(\mathcal T\),然后再通过一个low-level controller来进行跟踪轨迹即可
根据[10] 的启发,首先把专家的demonstrations 看做一个 sequential decision-making process,所以每一个观测 \(O^t\) 都可以分解 disentangled into some generative factors \(Z^t=[Z^t_1,Z^t_2,\dots,Z^t_k]\)
其中 \(k\) 就是生成出来的因子个数,每一步时间t 都有这样的factor对应。为了规划未来的轨迹:
- 通过现在的状态 \(Z^t\) 预测下一步的速度 \(S^t_{\text{forward}}\)
- 根据预测的速度 \(S^t_{\text{forward}}\) 和状态 \(Z^t\) 得到下一步的轨迹
也就是把观测先走到因子 可以直接认为成观测输入 一层MLP 输出? latent variable
是的 只是使用的模型不是单纯的一层FC 走了一个感知模型进行输出
2.1 输入
上帝视角的鸟瞰图和提取其他agent后的渲染图,简述即两幅图
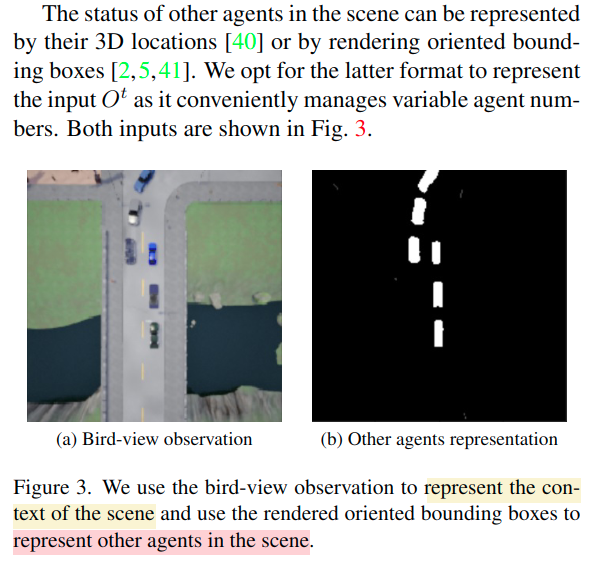
2.2 框架
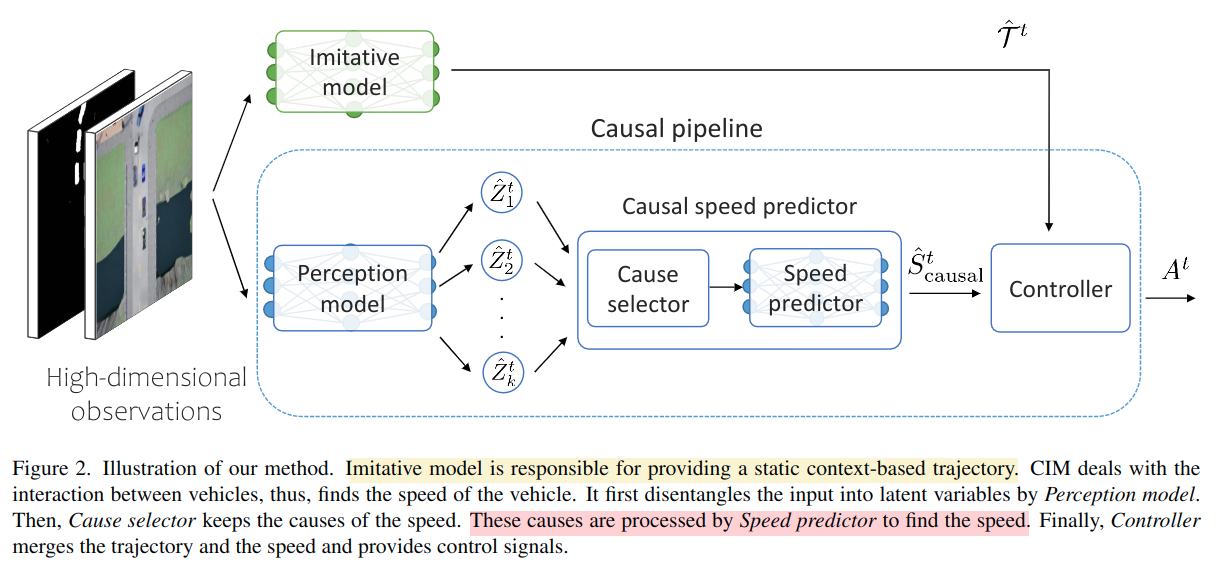
主要分为两个部分:
imitative model:主要处理静态障碍物 的场景导航,无其他agent 交互的考虑,只考虑专家数据的位置分布密度 \(q(\hat{\mathcal{T}} \mid O ; \theta)\) ,主要使用现有的模仿模型,训练取得最大似然估计
\[q(\hat{\mathcal{T}} \mid O ; \theta)\theta^{*}=\underset{\theta}{\arg \max } \mathbb{E}[\log q(\hat{\mathcal{T}} \mid O ; \theta)]
\]causal pipeline:主要预估速度和一下三个部分
感知模型 embeds observation into disentangled representation,整个模块使用的是 \(\beta\)-VAE [16] 的模型 然后输出到128个分解出来的变量 \(Z\)
因果速度预测:识别与速度有关的因果 并找到 the next step speed using them
主要是使用 Granger-cause 的一些定义: \(X^t\) 是 \(Y^t\) 的 Granger-cause,如果知道过去的 \(X^t\) 可以帮助到预测未来的 \(Y^t\)
当下列条件满足,则说明 \(X^t\) 是 \(Y^t\) 的 Granger-cause
\[\exists h>0, \text { s.t. } \sigma_{Y}\left(h \mid \Omega^{t}\right)<\sigma_{Y}\left(h \mid \Omega^{t} \backslash\left\{X^{i}\right\}_{i=0}^{t}\right) \tag{1}
\]其中 \(\sigma_{Y}\left(h \mid \Omega^{t}\right)\) 是 时间 \(t\) 下给\(\Omega^{t}\)信息时 h-step下的预测 \(Y^t\) 的MSE 平均方差误差,\(\Omega^{t}\) 是指全局下所有与 \(Y^t\) 有关的信息
温馨链接:Granger causality wiki page
摘取wiki至:格蘭傑因果關係檢驗(英語:Granger causality test)是一種假設檢定的統計方法,檢驗一組時間序列是否為另一組時間序列{\displaystyle y}的原因。它的基礎是迴歸分析當中的自迴歸模型。迴歸分析通常只能得出不同 變量間的同期 相關性;自迴歸模型只能得出同一 變量前後期 的相關性;但諾貝爾經濟學獎得主克萊夫·格蘭傑(Clive Granger)於1969年論證[1] ,在自迴歸模型中透過一系列的檢定進而揭示不同變量之間的時間落差相關性是可行的。
所以第一部分的现成的是啥模型?输入是啥传感器信息 还是直接是上帝视角?
见输入,模型使用的是DIM参考文献的
是指下一个step中 使用这些因果的速度吗?
2.3 输出
各自的两部分输出由框架图可知
- imitative model 是 输出轨迹点
- perception model 走到 disentangled gerative factor 然后输出
- cause selector 输出走到 速度预测模块 输出速度,配合前面的轨迹点
- contrller 输出动作:油门 方向盘 刹车
3. 实验
指标:
- Inertia rate:来源于[9] 超过15s的 零速度即视为 inertia rate
- Collision rate:与其他车辆相撞
- Error rate:前两者相加
用DIM [32],RIP [12] 做对比实验
外加两组消融实验,把CIM里面的cause selector直接换成 MLP进行再输出速度的 CIM-MLP;还有感知模型,直接使用原有的VAE而不是 \(\beta\)-VAE的 CIM-entangled
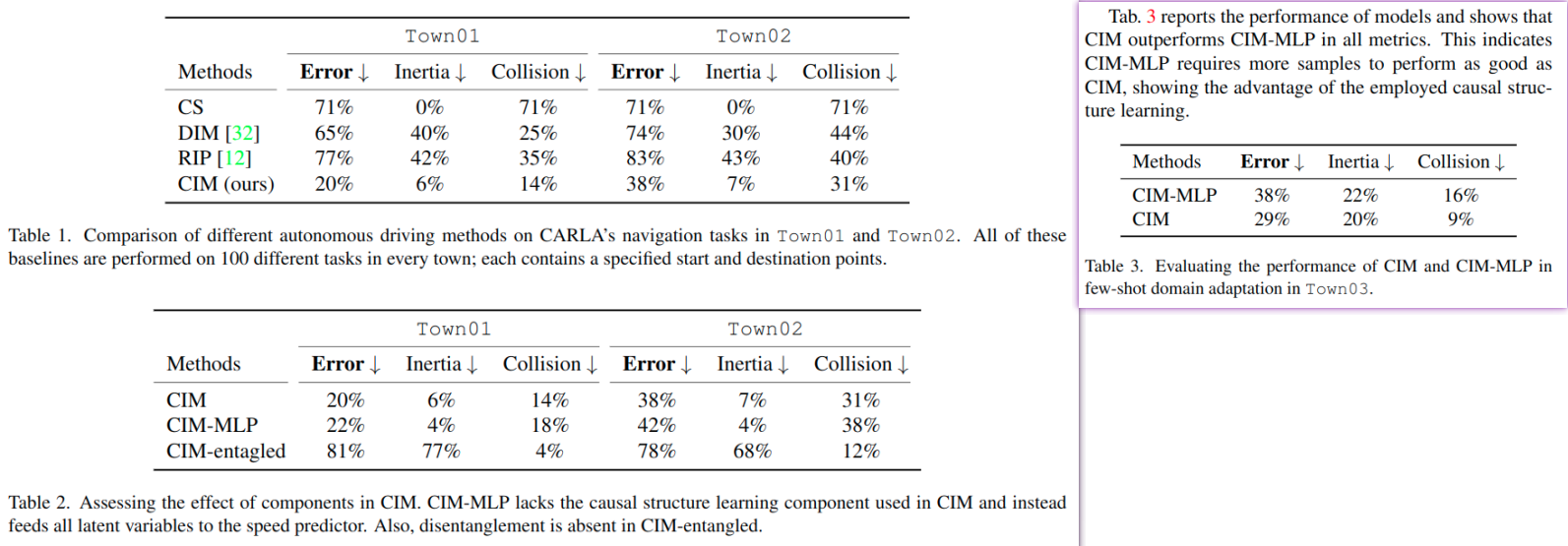
温馨提示RIP:
ICML2020: Can Autonomous Vehicles Identify, Recover From, and Adapt to Distribution Shifts?
- 套娃读一下DIM 对比一下
4. Conclusion
贡献如上,主要是做了一层分解的latent variables 选择因果变量,limitation也指出:
- 根据原文5.5 可知分解效果 the performance of the disentabglement method 是本文的一个局限性,更好的 分解方式 可能带来更好的结果
- 本文仅针对inertia和collision 这两个问题,并没有扩展到整个 scene navigation 问题
- 是指传统的行为规划问题吗? behaviour planning
碎碎念
自己提出一个问题 and 解决一个问题,另外标准也由自己定,比较特别的是关于causal selector的选择和使用,就是没对着代码看 还没特别理解这个步骤,但是大概知道了 噢,原来可以这么玩。
- 看了一眼代码 只给出了MLP的 CIM-MLP... 走
model = MLP().to(device)
【论文阅读】Causal Imitative Model for Autonomous Driving的更多相关文章
- #论文阅读# Universial language model fine-tuing for text classification
论文链接:https://aclweb.org/anthology/P18-1031 对文章内容的总结 文章研究了一些在general corous上pretrain LM,然后把得到的model t ...
- tensorfolw配置过程中遇到的一些问题及其解决过程的记录(配置SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real-Time Object Detection for Autonomous Driving)
今天看到一篇关于检测的论文<SqueezeDet: Unified, Small, Low Power Fully Convolutional Neural Networks for Real- ...
- 论文阅读笔记 Word Embeddings A Survey
论文阅读笔记 Word Embeddings A Survey 收获 Word Embedding 的定义 dense, distributed, fixed-length word vectors, ...
- 论文阅读笔记三十九:Accurate Single Stage Detector Using Recurrent Rolling Convolution(RRC CVPR2017)
论文源址:https://arxiv.org/abs/1704.05776 开源代码:https://github.com/xiaohaoChen/rrc_detection 摘要 大多数目标检测及定 ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- Autonomous driving - Car detection YOLO
Andrew Ng deeplearning courese-4:Convolutional Neural Network Convolutional Neural Networks: Step by ...
- 论文阅读笔记 Improved Word Representation Learning with Sememes
论文阅读笔记 Improved Word Representation Learning with Sememes 一句话概括本文工作 使用词汇资源--知网--来提升词嵌入的表征能力,并提出了三种基于 ...
- Event StoryLine Corpus 论文阅读
Event StoryLine Corpus 论文阅读 本文是对 Caselli T, Vossen P. The event storyline corpus: A new benchmark fo ...
- Behavior Trees for Path Planning (Autonomous Driving)
Behavior Trees for Path Planning (Autonomous Driving) 2019-11-13 08:16:52 Path planning in self-driv ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
随机推荐
- Golang、python中MD5、SHA512、base64编码等
在GO中处理的话,比较方便. func main() { fmt.Println(md5Str("woGo")) fmt.Println(sha512Str("woGo& ...
- google账户配置foxmail和使用foxmail
最近想把邮件分门别类,创建一些个人文件夹,更好的筛选邮件,可以尝试使用foxmail 1. 如果你有google账户,在配置foxmail之前需打开google账户的安全设置 https://myac ...
- Oracle数据库下的DDL、DML、DQL、TCL、DCL
首发微信公众号:SQL数据库运维 原文链接:https://mp.weixin.qq.com/s?__biz=MzI1NTQyNzg3MQ==&mid=2247485212&idx=1 ...
- 将自己喜欢的网页保存为单个文件包括图片(mhtml文件)
from selenium import webdriver driver = webdriver.Chrome(r'C:\chromedriver_win32\chromedriver.exe') ...
- 利用FileReader进行二进制文件传输
一.读取本地二进制文件,上传(数据库文件为例) 二进制文件读取的时候应当直接读取成字节数组,以免在调试时造成误解.比如数据库文件里面的有些字段是utf8编码,因此,采用utf-8编码读出来也能看到一些 ...
- GROK 表达式
GROK 表达式 常用表达式 标识:USERNAME 或 USER 正则:[a-zA-Z0-9._-]+ 名称:用户名 描述:由数字.大小写及特殊字符(._-)组成的字符串 例子:1234.Bob.A ...
- C# wpf 实现Converter定义与使用
1. 本身的值0, 如何转换为"男" 或"女"呢,可以定义sexConverter继承自IValueConverter即可,代码如下: [ValueConve ...
- C# 实现中文转颜色 - 实现根据名字自动生成头像
一.C#实现中文转颜色 - 实现根据名字自动生成头像 原理说明: 由于名字图像是自动生成,背景颜色不一样,可以考虑一下几种方法: 1)使用随机数来自动生成一个16进制颜色字符串,作为头像的背景颜色: ...
- SQL KEEP 窗口函数等价改写案例
一哥们出条sql题给我玩,将下面sql改成不使用keep分析函数的写法. select deptno, ename, sal, hiredate, min(sal) keep(dense_rank f ...
- 一文搞懂C++继承、多继承、菱形继承、虚继承
继承 目录 继承 继承 继承的访问权限 子类赋值给父类 赋值兼容规则 "天然"的行为 验证: 1. 其他权限继承能否支持赋值兼容规则 2.是否"天然",有没有产 ...