influxdb 端点使用http进行sql查询,写数据
转载请注明出处:
InfluxDB有以下几个常用的端点,它们的作用和传参方式如下:
1./ping
端点:
作用:用于检查InfluxDB实例的状态,返回InfluxDB的构建类型和版本信息。
传参:无需传参,仅发送GET请求即可。
调用示例:
curl http://localhost:8086/ping
2./write
端点:
作用:用于将数据写入InfluxDB。
传参:
请求方式:发送POST请求。
请求头:
Content-Type:设置为application/x-www-form-urlencoded或text/plain,表示请求体中的数据格式为InfluxDB的行协议(Line Protocol)。
请求体:需要将要写入的数据按照InfluxDB的行协议格式进行编码,并作为请求体发送。
当有标签(tag)和字段(field)如下所示时,可以通过在数据点中使用逗号分隔并以键值对的形式传递参数:
curl -XPOST 'http://localhost:8086/write?db=my_database' \
--data-binary '
measurement_name,host=example_host,ip=192.168.1.100 name="John Doe",num=42 1627842300000000000
'
也可以添加更多的数据点,每个数据点之间使用换行符进行分隔,以传递多个标签和字段的参数。
3./query
端点:
作用:用于执行查询操作,从InfluxDB中检索数据。
传参:
请求方式:发送POST请求。
请求头:
Content-Type:设置为application/x-www-form-urlencoded或application/json,表示请求体中的数据格式为InfluxDB查询语句的格式(InfluxQL或Flux)。
请求体:将查询语句编写为InfluxQL或Flux格式,并作为请求体发送。
curl -XPOST 'http://localhost:8086/query' \
-H 'Content-Type: application/x-www-form-urlencoded' \
--data-urlencode 'q=SELECT * FROM measurement_name WHERE time > now() - 1h'
4./query
端点(批量查询):
作用:用于在单个请求中执行多个查询操作。
传参:
请求方式:发送POST请求。
请求头:
Content-Type:设置为application/x-www-form-urlencoded或application/json,表示请求体中的数据格式为InfluxDB查询语句的格式(InfluxQL或Flux)。
请求体:将多个查询语句按照InfluxQL或Flux格式编写,并使用分号(;)作为分隔符,将它们放在请求体中一起发送。
curl -XPOST 'http://localhost:8086/query?db=my_database' \
--data-raw '
[
{
"measurement": "measurement_name1",
"tags": { "tag_key": "tag_value" },
"fields": [ "field_key1", "field_key2" ],
"time": "2022-01-01T00:00:00Z",
"query": "SELECT field_key1, field_key2 FROM measurement_name1 WHERE tag_key = 'tag_value'"
},
{
"measurement": "measurement_name2",
"tags": { "tag_key": "tag_value" },
"fields": [ "field_key1", "field_key2" ],
"time": "2022-01-01T00:00:00Z",
"query": "SELECT field_key1, field_key2 FROM measurement_name2 WHERE tag_key = 'tag_value'"
}
]
'
对每个部分的详细说明:
-XPOST:指定 HTTP 请求方法为 POST。http://localhost:8086/query?db=my_database:设置目标 URL,其中http://localhost:8086是 InfluxDB 服务地址,query是端点路径,db=my_database是查询参数,指定要查询的数据库名称为my_database。--data-raw:用于发送原始数据的 curl 选项。在这里,我们使用它来传递批量查询的 JSON 数据。这是实际的批量查询 JSON 数据示例。其中包含两个查询对象,每个对象都有以下属性:
measurement:测量名称;tags:标签键值对;fields:字段列表;time:时间戳(可选);query:实际的 InfluxDB 查询语句。
请根据实际需求替换示例中的参数,并确保提供正确的查询语句和数据库名称。
响应将返回多个查询结果,每个查询结果都以 JSON 格式表示。你可以通过解析响应来获取每个查询的结果。
5.异常总结
5.1 unable to parse authentication credentials
报错 "unable to parse authentication credentials" 表明在发送 InfluxDB 查询请求时,认证凭据解析错误。这是由于未正确配置或提供身份验证信息导致的。需要在发送 curl 请求时,提供了正确的用户名和密码来进行身份验证。可以使用 -u 参数来指定用户名和密码。以下是一个示例:
curl -XPOST 'http://localhost:8086/query' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-u username:password \
--data-urlencode 'q=SELECT * FROM measurement_name WHERE time > now() - 1h'
请确保在 InfluxDB 的配置文件中启用了身份验证,并且提供了正确的用户名和密码。默认情况下,InfluxDB 的身份验证是禁用的,因此需要手动启用并配置用户凭据。
如果问题仍然存在,请检查用户名和密码是否正确,以及 InfluxDB 配置文件中是否正确配置了身份验证。
5.2 database name required
报错 "database name required" 表明在发送 InfluxDB 查询请求时,未提供数据库名称。查询语句需要指定要使用的数据库。
curl -XPOST 'http://localhost:8086/query' \
-H 'Content-Type: application/x-www-form-urlencoded' \
-u username:password \
--data-urlencode 'q=SELECT * FROM measurement_name WHERE time > now() - 1h' \
--data-urlencode 'db=your_database_name'
在上述示例中,将 your_database_name 替换为实际的数据库名称,并确保提供了正确的数据库名称。
6.使用postman请求query
-u 需要转换为 Authorization 的请求头,使用python的base64计算的具体方法为:
import base64 username = 'admin'
password = 'password' credentials = username + ':' + password
base64_credentials = base64.b64encode(credentials.encode()).decode() authorization = 'Basic ' + base64_credentials
print(authorization)
根据 生成的 Authorization 配置到 postman 中。
将 查询 的sql,db配置到查询的body
header部分:
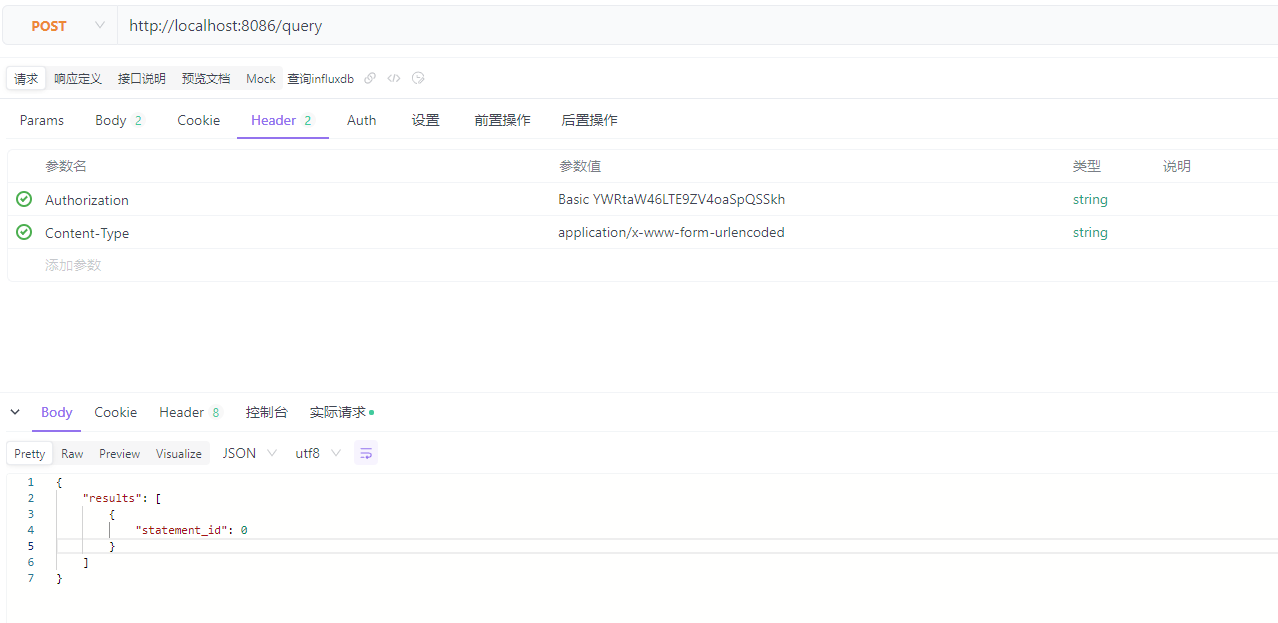
body部分
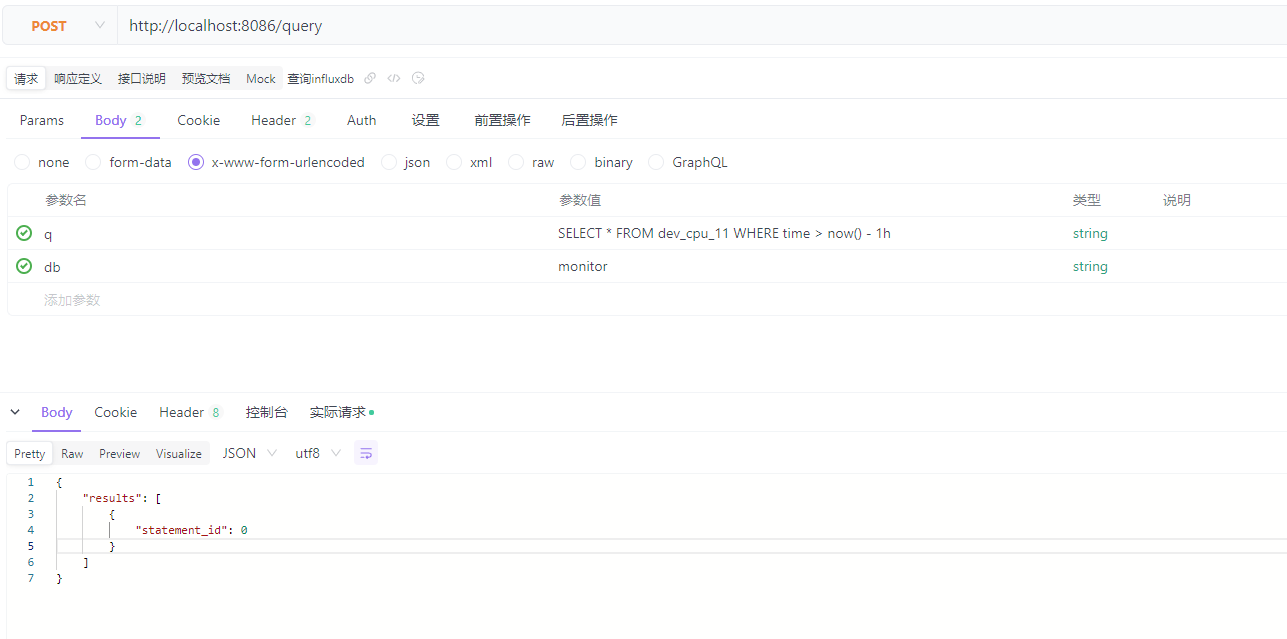
参考:
https://docs.influxdata.com/influxdb/v1.7/tools/api/
influxdb 端点使用http进行sql查询,写数据的更多相关文章
- 视图查询的数据和sql查询的数据不一样
视图查询的数据和sql查询的数据不一样. 手动刷新视图 exec sp_refreshview 视图名称
- sql 查询重复数据,删除重复数据,过滤重复数据
select * from (SELECT titleid,count(titleid) c FROM [DragonGuoShi].[dbo].[ArticleInfo] group by titl ...
- ORACLE和SQL查询库数据量
ORACLE根据账号查询每张表数据量: select t.table_name,t.num_rows from user_tables t ORDER BY NUM_ROWS DESC; SQL SE ...
- 关于SQL查询某年数据 和DATEPART 函数的使用
数据库查询某年数据(sql server)select *from 表名 where YEAR(存时间的字段名) =某年select *from News where YEAR(addDate) =2 ...
- PL/SQL 查询的数据出现乱码
解决方法: 1.首先在查询出Oracle数据库的字符集. select userenv('language') from dual; 2.新建系统变量 NLS_LANG,变量值为第一步查询出来的字符集 ...
- [sql查询] 重复数据只取一条
SELECT * FROM tab_init WHERE id IN ( --根据Data分类获取数据最小ID列表 select max(id) from tab_init group by a,b ...
- sql查询当天数据
向数据库中添加日期 MS SQL SERVER: NSERT into student(studentid,time1)values('15',getdate()); MY SQLinsert int ...
- SQL查询遍历数据方法一 [ 临时表 + While循环]
以下以SQL Server 2000中的NorthWind数据库中的Customers表为例, 用 临时表 + While循环 的方法, 对Customers表中的CompanyName列进行遍历 c ...
- 工作 巧遇 sql 查询 一组数据中 最新的一条
SELECT * FROM rsl a, (SELECT CODE, max(time_key) time_key FROM rsl GROUP BY CODE ) b WHERE a. CODE = ...
- sql 查询大数据 常用 50列优化
大数据量的问题是很多面试笔试中经常出现的问题,比如baidu google 腾讯 这样的一些涉及到海量数据的公司经常会问到. 下面的方法是我对海量数据的处理方法进行了一个一般性的总结,当然这些方法可能 ...
随机推荐
- 使用 Power Shell 修改 Hyper-V 虚拟机 UUID 的解决方案
前言 在研究了一下午 k8s 文档的时候,正准备开干,万万没想到一个 uuid 的问题卡了我几个小时,一直想在系统中解决,没想到最后在外部使用PowerSheel解决了,分享记录一二 问题描述与尝试解 ...
- Bugku CTF web题
web2 查看网页源码,发现flag
- 16级C程序设计竞赛C题
问题 C: 回文 时间限制: 1 Sec 内存限制: 128 MB提交: 74 解决: 36[提交][状态][讨论版] 题目描述 给定一个字符串,你可以对字符串做任意改动,你可以在任意地方增加一个 ...
- 【UniApp】-uni-app-自定义组件
前言 经过上个章节的介绍,大家可以了解到 uni-app-网络请求的基本使用方法 那本章节来给大家介绍一下 uni-app-自定义组件 的基本使用方法 原本打算是直接写项目的,在写项目之前还有个内容需 ...
- pytest框架学习-标签@pytest.mark.
标签 自定义标签(区分大小写) 可以标记测试用例,对测试用例进行分组,有利于对测试用例进行筛选. 比如:给用例打标为API,代表接口自动化的用例,打标方法为@pytest.mark.API,打标后,需 ...
- SpringCloud OpenFeign的使用
SpringCloud OpenFeign的使用 是什么: 声明式http客户端. 目的: 使远程调用更简单 作用: 提供了http请求模板,仅需编写简单接口和插入注解,就可以定义好原始http请求的 ...
- SpringMVC中资源路径映射本地文件图片
SpringMVC中资源路径映射本地文件图片 import org.springframework.context.annotation.Configuration; import org.sprin ...
- 文心一言 VS 讯飞星火 VS chatgpt (168)-- 算法导论13.2 1题
一.用go语言,写出 RIGHT-ROTATE 的伪代码. 文心一言: 在计算机科学中,右旋转(RIGHT-ROTATE)是一种常见的操作,通常用于数组或链表.以下是一个使用Go语言实现右旋转的伪代码 ...
- Picker 选择器
WXML 文件中 <view class="container"> <view> <text>选择器的值: {{pickerValue}}< ...
- Cesium中用到的图形技术——Computing the horizon occlusion point
译者注:本文翻译自Cesium官方博文<Computing the horizon occlusion point>,by KEVIN RING. 你厌倦了地平线剔除吗? 太好了,我也没有 ...