深度学习(十二)——神经网络:搭建小实战和Sequential的使用
一、torch.nn.Sequential代码栗子
# Using Sequential to create a small model. When `model` is run,
# input will first be passed to `Conv2d(1,20,5)`. The output of
# `Conv2d(1,20,5)` will be used as the input to the first
# `ReLU`; the output of the first `ReLU` will become the input
# for `Conv2d(20,64,5)`. Finally, the output of
# `Conv2d(20,64,5)` will be used as input to the second `ReLU`
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
在第一个变量名model中,依次执行
nn.Convd2d(1,20,5)、nn.ReLU()、nn.Conv2d(20,64,5)、nn.ReLU()四个函数。这样写起来的好处是使代码更简洁。由此可见,函数\(Sequential\)的主要作用为依次执行括号内的函数
二、神经网络搭建实战
采用\(CIFAR10\)中的数据,并对其进行简单的分类。以下图为例:
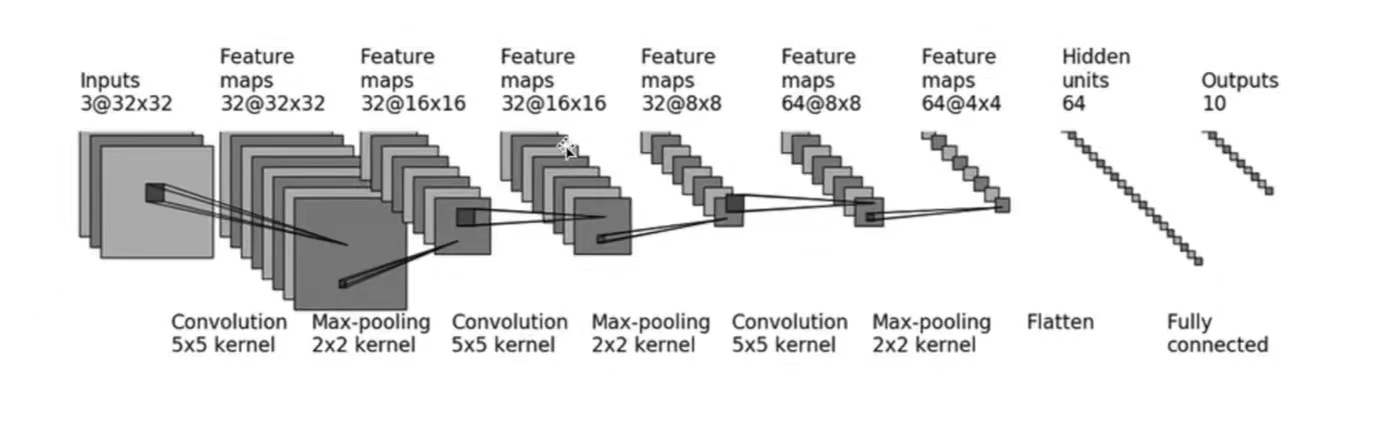
- 输入:3通道,32×32 → 经过一个5×5的卷积 → 变成32通道,32×32的图像 → 经过2×2的最大池化 → 变成32通道,16×16的图像.... → ... → 变成64通道,4×4的图像 → 把图像展平(Flatten)→ 变成64通道,1×1024 (64×4×4) 的图像 → 通过两个线性层,最后\(out\_feature=10\) → 得到最终图像
以上,就是CIFAR10模型的结构。本节的代码也基于CIFAR10 model的结构构建。
1. 神经网络中的参数设计及计算
(1)卷积层的参数设计(以第一个卷积层conv1为例)
输入图像为3通道,输出图像为32通道,故:\(in\_channels=3\);\(out\_channels=32\)
卷积核尺寸为\(5×5\)
图像经过卷积层conv1前后的尺寸均为32×32,根据公式:
\[H_{out}=⌊\frac{H_{in}+2×padding[0]−dilation[0]×(kernel\_size[0]−1)−1}{stride[0]}+1⌋
\]\[W_{out}=⌊\frac{W_{in}+2×padding[1]−dilation[1]×(kernel\_size[1]−1)−1}{stride[1]}+1⌋
\]可得:
\[H_{out}=⌊\frac{32+2×padding[0]−1×(5−1)−1}{stride[0]}+1⌋=32
\]\[W_{out}=⌊\frac{32+2×padding[1]−1×(5−1)−1}{stride[1]}+1⌋=32
\]即:
\[\frac{27+2×padding[0]}{stride[0]}=31
\]\[\frac{27+2×padding[1]}{stride[1]}=31
\]若\(stride[0]\)或\(stride[1]\)设置为2,那么上面的\(padding\)也会随之扩展为一个很大的数,这很不合理。所以这里设置:\(stride[0]=stride[1]=1\),由此可得:\(padding[0]=padding[1]=2\)
其余卷积层的参数设计及计算方法均同上。
(2)最大池化操作的参数设计(以第一个池化操作maxpool1为例)
- 由图可得,\(kennel\_size=2\)
其余最大池化参数设计方法均同上。
(3)线性层的参数设计
通过三次卷积和最大池化操作后,图像尺寸变为64通道4×4。之后使用\(Flatten()\)函数将图像展成一列,此时图像尺寸变为:1×(64×4×4),即\(1×1024\)
因此,之后通过第一个线性层,\(in\_features=1024\),\(out\_features=64\)
通过第二个线性层,\(in\_features=64\),\(out\_features=10\)
2. 构建神经网络实战
import torch
from torch import nn
from torch.nn import Conv2d, MaxPool2d, Flatten, Linear
class Demo(nn.Module):
def __init__(self):
super(Demo,self).__init__()
# 搭建第一个卷积层:in_channels=3,out_channels=32,卷积核尺寸为5×5,通过计算得出:padding=2;stride默认情况下为1,不用设置
self.conv1=Conv2d(3,32,5,padding=2)
# 第一个最大池化操作,kennel_size=2
self.maxpool1=MaxPool2d(2)
# 第二个卷积层及最大池化操作
self.conv2=Conv2d(32,32,5,padding=2)
self.maxpool2=MaxPool2d(2)
# 第三个卷积层及最大池化操作
self.conv3=Conv2d(32,64,5,padding=2)
self.maxpool3=MaxPool2d(2)
# 展开图像
self.flatten=Flatten()
# 线性层参数设计
self.linear1=Linear(1024,64)
self.linear2=Linear(64,10)
# 如果是预测概率,那么取输出结果的最大值(它代表了最大概率)
def forward(self,x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x) #如果线性层的1024和64不会计算,可以在self.flatten之后print(x.shape)查看尺寸,以此设定linear的参数
x = self.linear2(x)
return x
demo=Demo()
print(demo)
"""
[Run]
Demo(
(conv1): Conv2d(3, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(32, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv3): Conv2d(32, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(maxpool3): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(flatten): Flatten(start_dim=1, end_dim=-1)
(linear1): Linear(in_features=1024, out_features=64, bias=True)
(linear2): Linear(in_features=64, out_features=10, bias=True)
)
可以看出,网络还是有模有样的
"""
#构建输入,测试神经网络
input=torch.ones((64,3,32,32)) #构建图像,batch_size=64,3通道,32×32
output=demo(input)
print(output.shape) #[Run] torch.Size([64, 10])
这里的\(forward\)函数写的有点烦,这时候\(Sequential\)函数的优越就体现出来了(墨镜黄豆)。下面是\(class\) \(Demo\)优化后的代码:
class Demo(nn.Module):
def __init__(self):
super(Demo,self).__init__()
self.model1=Sequential(
Conv2d(3,32,5,padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self,x):
x=self.model1(x)
return x
极简主义者看过后表示很满意ε٩(๑> ₃ <)۶з
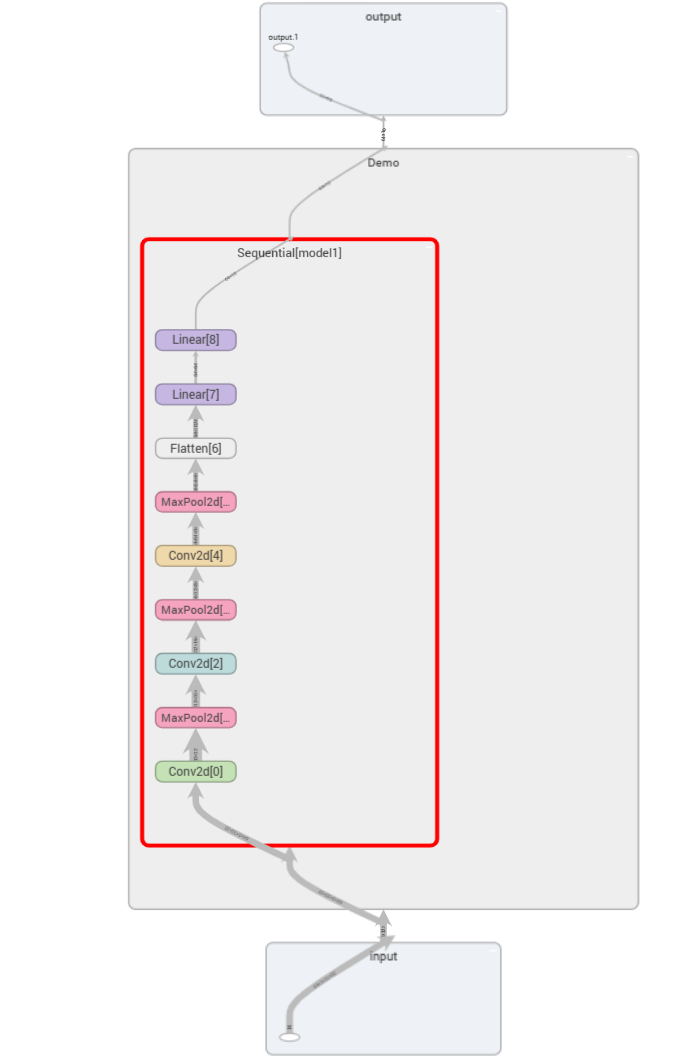
3. 可视化神经网络
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("logs_seq")
writer.add_graph(demo,input)
writer.close()
这样就可以清晰地看到神经网络的相关参数啦
深度学习(十二)——神经网络:搭建小实战和Sequential的使用的更多相关文章
- 深度学习(二十六)Network In Network学习笔记
深度学习(二十六)Network In Network学习笔记 Network In Network学习笔记 原文地址:http://blog.csdn.net/hjimce/article/deta ...
- 深度学习之卷积神经网络CNN及tensorflow代码实现示例
深度学习之卷积神经网络CNN及tensorflow代码实现示例 2017年05月01日 13:28:21 cxmscb 阅读数 151413更多 分类专栏: 机器学习 深度学习 机器学习 版权声明 ...
- 对比深度学习十大框架:TensorFlow 并非最好?
http://www.oschina.net/news/80593/deep-learning-frameworks-a-review-before-finishing-2016 TensorFlow ...
- 深度学习之卷积神经网络CNN及tensorflow代码实例
深度学习之卷积神经网络CNN及tensorflow代码实例 什么是卷积? 卷积的定义 从数学上讲,卷积就是一种运算,是我们学习高等数学之后,新接触的一种运算,因为涉及到积分.级数,所以看起来觉得很复杂 ...
- 推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战 0.8012018.05.19 16:17:18字数 2068阅读 22568 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模 ...
- 【神经网络与深度学习】卷积神经网络(CNN)
[神经网络与深度学习]卷积神经网络(CNN) 标签:[神经网络与深度学习] 实际上前面已经发布过一次,但是这次重新复习了一下,决定再发博一次. 说明:以后的总结,还应该以我的认识进行总结,这样比较符合 ...
- 深度学习(二)--深度信念网络(DBN)
深度学习(二)--深度信念网络(Deep Belief Network,DBN) 一.受限玻尔兹曼机(Restricted Boltzmann Machine,RBM) 在介绍深度信念网络之前需要先了 ...
- 语义分割:基于openCV和深度学习(二)
语义分割:基于openCV和深度学习(二) Semantic segmentation in images with OpenCV 开始吧-打开segment.py归档并插入以下代码: Semanti ...
- 深度学习之卷积神经网络(CNN)的应用-验证码的生成与识别
验证码的生成与识别 本文系作者原创,转载请注明出处:https://www.cnblogs.com/further-further-further/p/10755361.html 目录 1.验证码的制 ...
- 深度学习之循环神经网络RNN概述,双向LSTM实现字符识别
深度学习之循环神经网络RNN概述,双向LSTM实现字符识别 2. RNN概述 Recurrent Neural Network - 循环神经网络,最早出现在20世纪80年代,主要是用于时序数据的预测和 ...
随机推荐
- Linux 内存管理 pt.3
哈喽大家好,我是咸鱼 在<Linux 内存管理 pt.2>中我们学习了多级页表和大页,我们知道了由于历史遗留的问题,Linux 的页通常为 4KB 这样就会导致一个页表里面会有特别多页,为 ...
- drf——序列化之source(了解)、定制字段的两种方式(重要)、多表关联反序列化保存、反序列化字段校验、ModelSerializer使用
1 序列化高级用法之source(了解) # 1.创建了5个表(图书管理的5个) # 2.对book进行序列化 # 总结:source的用法 1.修改前端看到的字段key值--->source指 ...
- 在DevExpress中使用BandedGridView表格实现多行表头的处理
在之前较早随笔中介绍过实现多行表头的处理,通过手工创建字段以及映射数据源字段属性的方式实现,有些客户反映是否可以通过代码方式更方便的创建对应的处理操作,因此本篇随笔继续探讨这个多行表头的处理的操作,使 ...
- 连接内网 SSH 新姿势,告别慢速度及防火墙限制
近些年,因为某些原因,我们常常在家远程研发业务,当某些程序或业务代码在公司电脑上时,就需要访问公司电脑远程操作, SSH 登录 Linux 是一种非常常见的方式,但是在一些情况下,SSH 无法直接连接 ...
- 基于SqlSugar的开发框架循序渐进介绍(31)-- 在查询接口中实现多表联合和单表对象的统一处理
在一些复杂的业务表中间查询数据,有时候操作会比较复杂一些,不过基于SqlSugar的相关操作,处理的代码会比较简单一些,以前我在随笔<基于SqlSugar的开发框架循序渐进介绍(2)-- 基于中 ...
- Springboot+actuator+prometheus+Grafana集成
本次示例以Windows示例 推荐到官网去下载:Windows版的应用程序 下载最新版 prometheus-2.37.8.windows-amd64 压缩包:解压就行 下载最新版 grafana-9 ...
- AI 协助办公 |记一次用 GPT-4 写一个消息同步 App
GPT-4 最近风头正劲,作为 NebulaGraph 的研发人员的我自然是跟进新技术步伐.恰好,现在有一个将 Slack channel 消息同步到其他 IM 的需求,看看 GPT-4 能不能帮我完 ...
- 一文搞懂V8引擎的垃圾回收机制
前言 我们平时在写代码的过程中,好像很少需要自己手动进行垃圾回收,那么V8是如何来减少内存占用,从而避免内存溢出而导致程序崩溃的情况的.为了更高效地回收垃圾,V8引入了两个垃圾回收器,它们分别针对不同 ...
- .Net7基础类型的优化和循环克隆优化
前言 .Net7里面对于基础类型的优化,是必不可少的.因为这些基础类型基本上都会经常用到,本篇除了基础类型的优化介绍之外,还有一个循环克隆的优化特性,也一并看下. 概括 1.基础类型优化 基础类型的优 ...
- 如何在矩池云上安装和使用 Stata
Stata是一款功能强大的统计分析软件,本文提供了如何在矩池云安装使用 Stata,以及如何在 Jupyter 中使用 Stata 的简要教程. 安装 Stata 时需要确保按照官方指南进行操作,St ...