使用 SQL 的方式查询消息队列数据以及踩坑指南

背景
为了让业务团队可以更好的跟踪自己消息的生产和消费状态,需要一个类似于表格视图的消息列表,用户可以直观的看到发送的消息;同时点击详情后也能查到消息的整个轨迹。
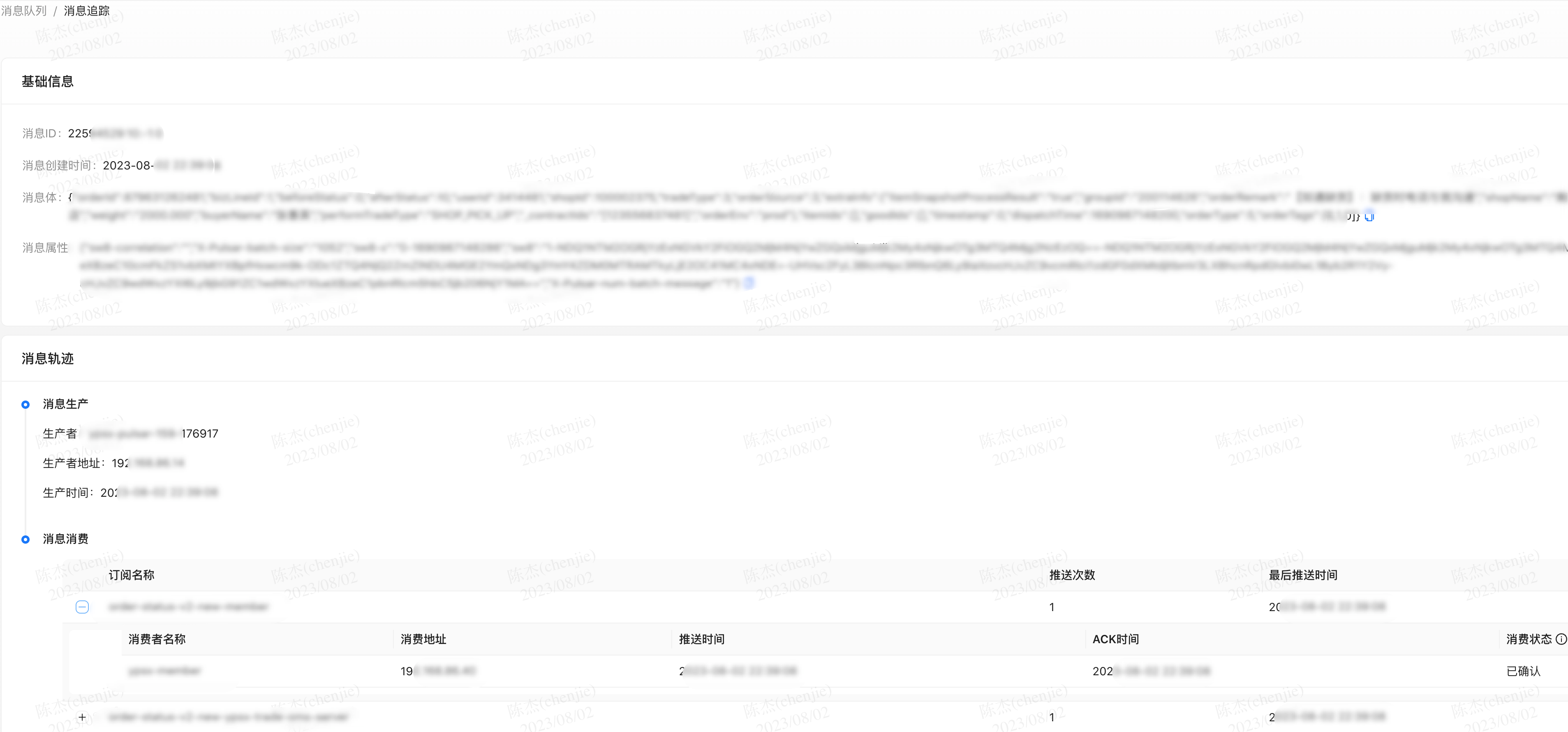
消息列表

点击详情后查看轨迹
原理介绍
由于 Pulsar 并没有关系型数据库中表的概念,所有的数据都是存储在 Bookkeeper 中,为了模拟使用 SQL 查询的效果 Pulsar 提供了 Presto (现在已经更名为 Trino)的插件。
Trino 是一个分布式的 SQL 查询引擎,它也提供了插件能力,如果我们想通过 SQL 从自定义数据源查询数据时,基于它的 SPI 编写一个插件是很方便的。
这样便可以类似于查询数据库一样查询 Pulsar 数据:

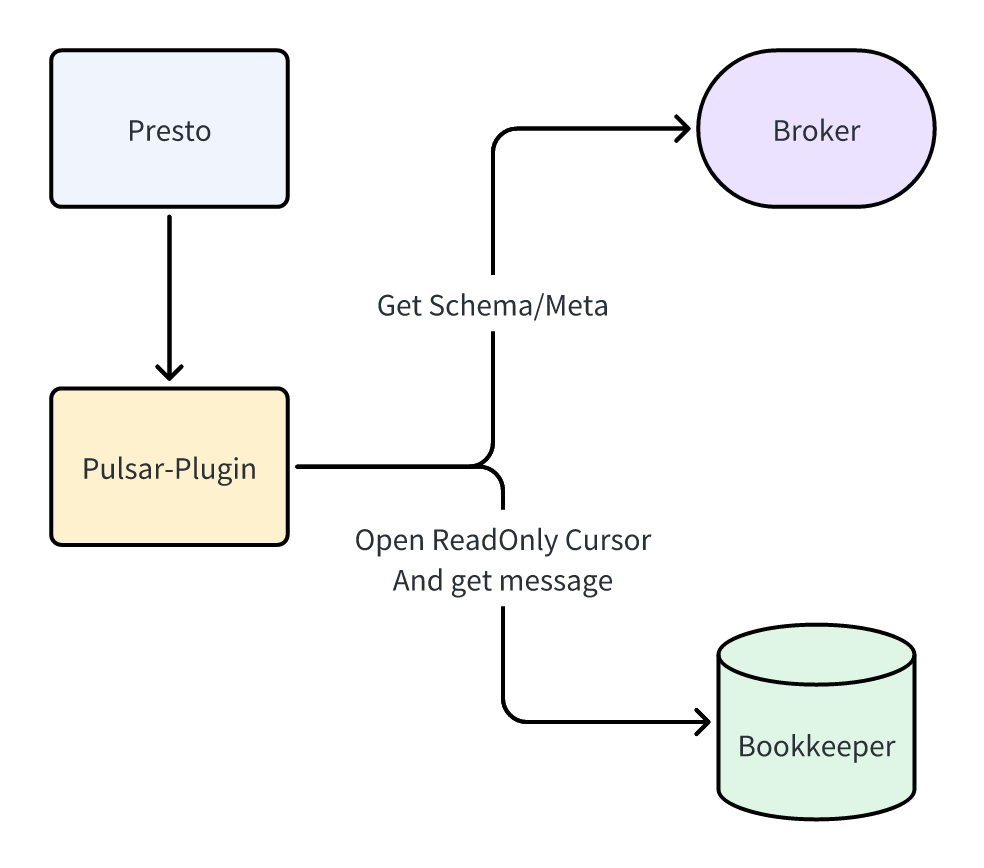
Pulsar 插件的运行流程如上图所示:
- 启动的时候通过
Pulsar-Admin接口获取一些元数据,比如 Scheme,topic 分区信息等。 - 然后会创建一个只读的 Bookkeeper 客户端,用于获取数据。
- 之后根据 SQL 条件过滤数据即可。
相关代码:

使用 Pulsar-SQL
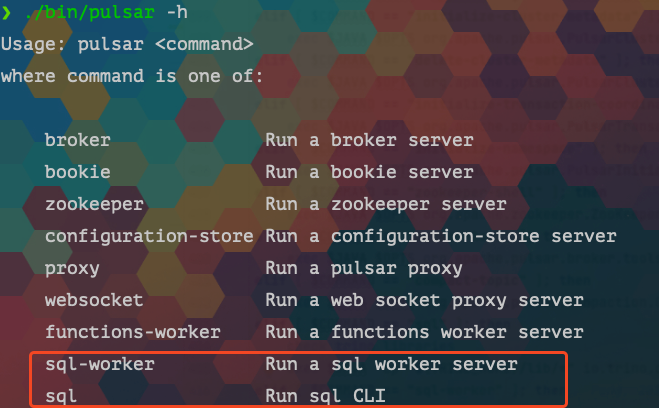
使用起来也很简单,官方提供了两个命令:
- sql-worker: 会启动一个 trino 服务端同时运行了 Pulsar 插件
- sql: 就是一个 SQL 命令行终端。
遇到的问题
自己在本地运行的时候自然是没问题,可是一旦想在生产运行,同时如果你的 Pulsar 集群是运行再 k8s 环境中时就会碰到一些问题。
无法使用现有 Trino 集群
首先第一个问题是如果生产环境已经有了一个 Trino 集群想要复用的时候就会碰到问题,常规流程是将 Pulsar 的插件复制到 Trino 的 Plugin 目录,然后重启 Trino 后就能使用该插件。
当然社区也是支持这么做的:
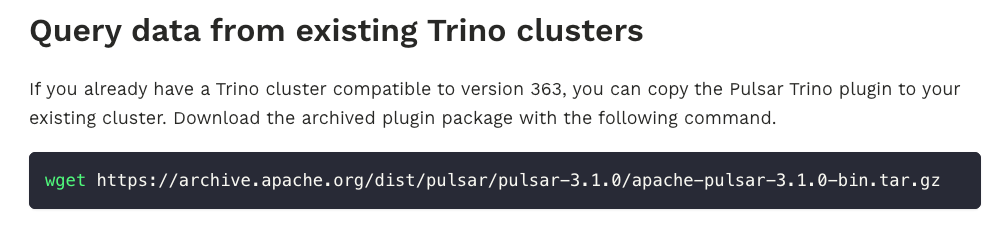
但是当我将 Pulsar-plugin 复制到 Trino 中运行的时候却失败了,整体的流程可以参考这个 issue:
https://github.com/apache/pulsar/discussions/20941
简单来说 Trino 的官方镜像和 pulsar-plugin 并不能兼容,这个问题直接影响到我们是否可以在生产环境使用它。
但是手动编译出来的 Trino 服务和插件是兼容的,可以直接运行。
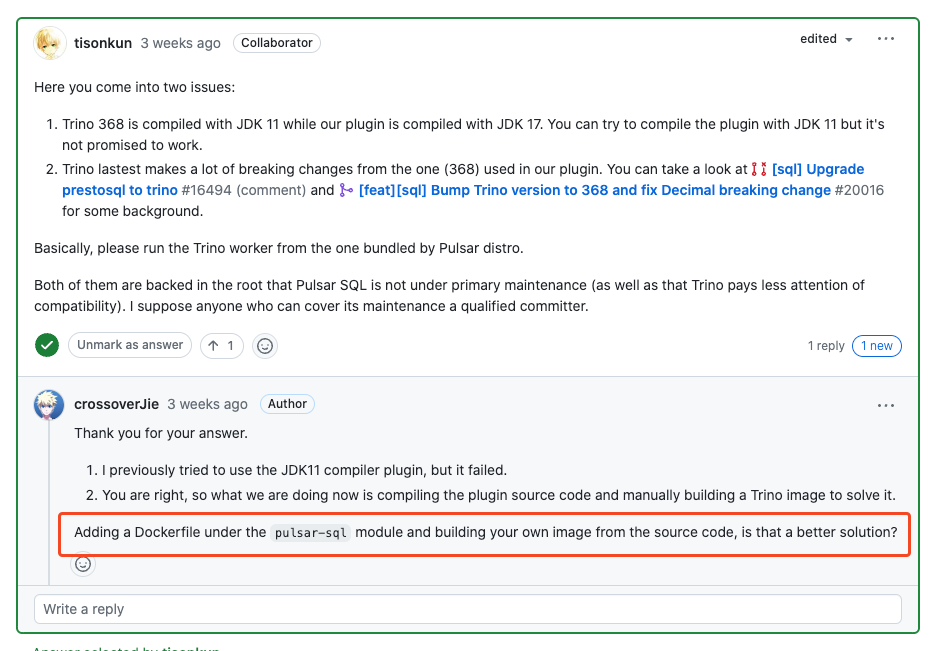
因此我只能在本地编译出 Trino 服务端和 pulsar-plugin 然后打包成一个镜像来运行了,当然这样的坏处就是无法利用到我们现有的 Trino 集群,又得重新部署一个了。
流程也比较麻烦:
- 首先是本地编译
Pulsar-SQL模块 - 将生成物复制到当前目录
- 执行
make docker打出 docker 镜像并上传到私服 - 再执行
kubectl将 trino 部署到k8s环境中
整个流程做下来加上和社区的沟通,更加确定这个功能应该是很少有人在生产环境使用的,毕竟第一个坑就很麻烦,更别提后续的问题了。
Presto 插件不支持 AuthToken
第二个问题也是个深坑,当我把 Trino 部署好查询数据的时候直接抛了一个调用 pulsar-admin 接口连接超时的异常。
结果排查了半天发现原来是 pulsar-plugin 里没有提供 JWT 的验证方式,而我们的 Pulsar 集群恰好是打开了 JWT 验证的。
为此我只能先在本地修复了这个问题,同时也提交了 PR,预计会在下一个大版本合并吧:
https://github.com/apache/pulsar/pull/20860
新创建的 topic 查询失败
第二个问题是当查询一个新创建的 topic 时,客户端会直接 block,相关的复现流程在这里:
https://github.com/apache/pulsar/issues/20910
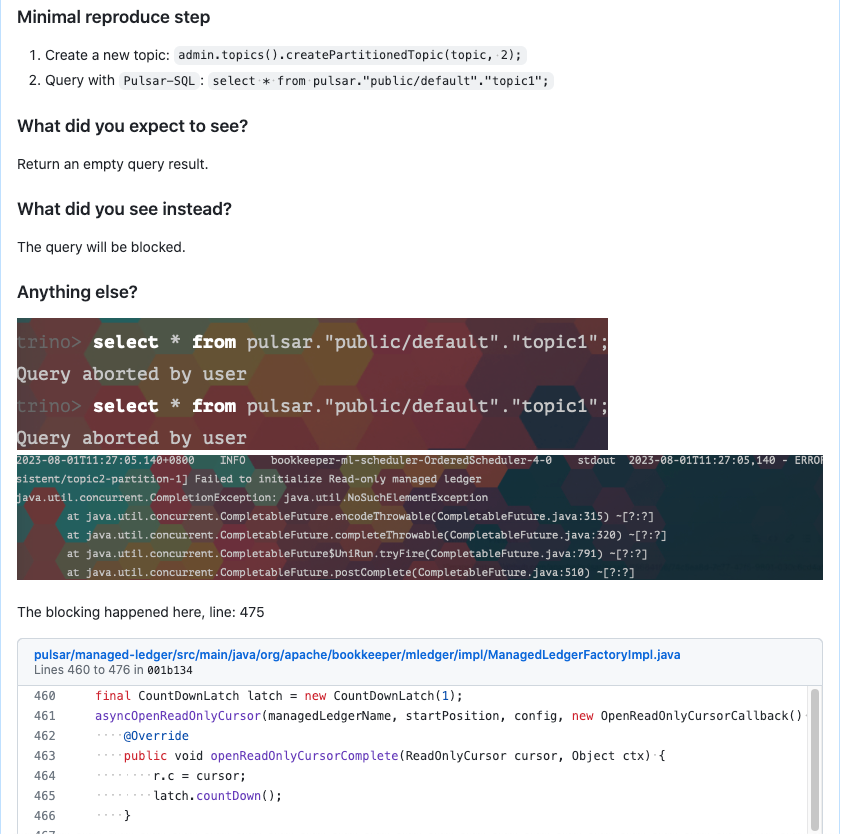
这个问题还好,不是很致命,是我在本地测试的时候无意间发现的。
本地我已经修复了,后面也提交了一个 PR,目前还在讨论中:
https://github.com/apache/pulsar/pull/20911
查询消息会丢失最后一条
这个问题也不是很严重,数据量少的时候会发现,就是在指定了消息发送时间的查询条件时,最后一条消息会被过滤掉,相关 issue 在这里:
https://github.com/apache/pulsar/issues/20919
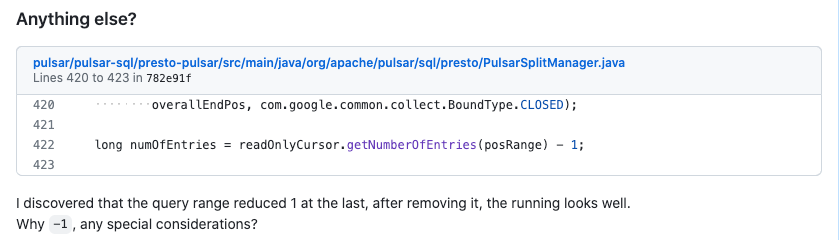
这个我只是定位到了原因,但不太清楚 为什么要这么做(-1),影响也不是很大,就放在这里搁置了。
Schema 不兼容
最后发现的一个问题是我们线上某些 topic 查询数据的时候会抛出 Not a record: "string"的异常,但只是部分 topic,也排查了很久,整个源码中没有任何一个地方有这个异常。
https://github.com/apache/pulsar/issues/20945
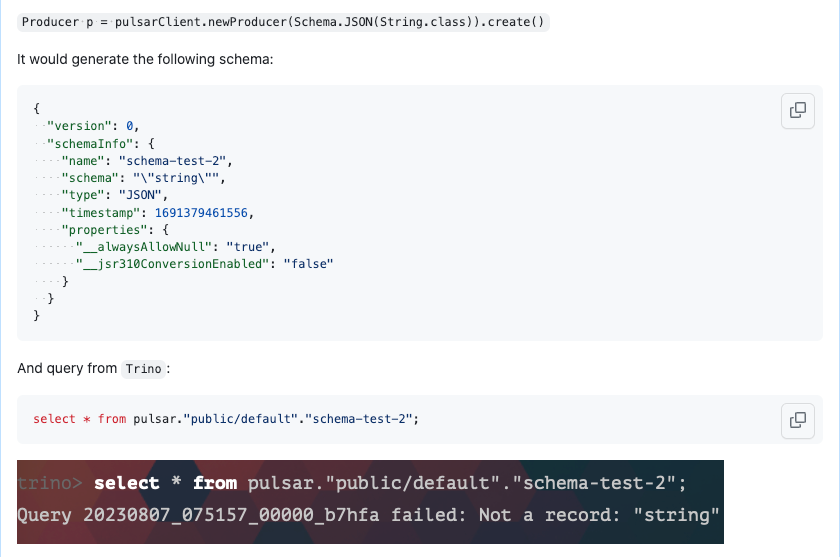
根本原因是生产者生成的 schema 有问题,类型已经是 JSON 了,但是 schema 却是 string,这样导致 pulsar-plugin 在反序列化 schema 的时候抛出了异常,由于是 pb 反序列化抛出的异常,所以源码中都搜索不到。
没有问题的 topic 使用了正确的 schema
后续我也在本地修复了这个问题,当抛出异常后就将 schema 降级为基本类型进行解析。
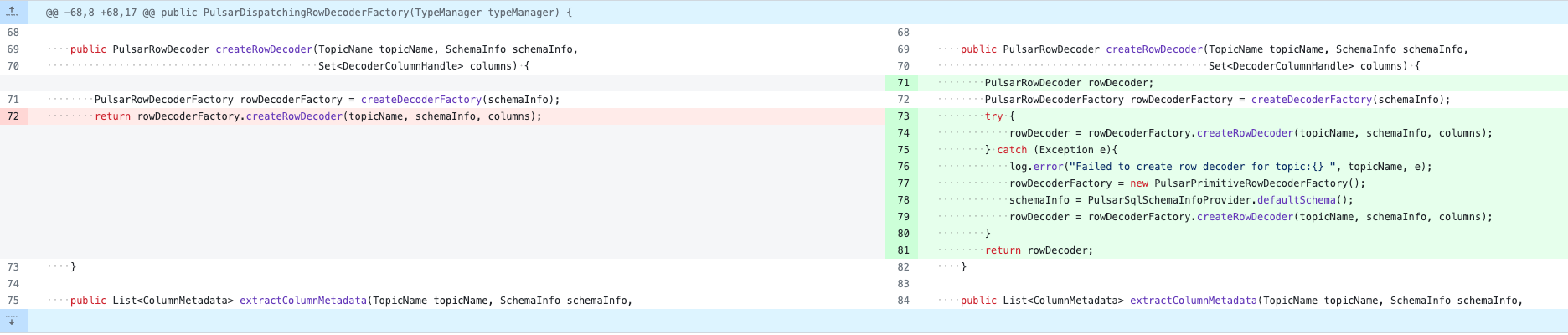
不过本质问题还是客户端使用有误,如果对 schema 理解不准确的话还是建议使用 byte[] 吧,这样至少兼容性不会有问题。
相关 PR:
https://github.com/apache/pulsar/pull/20955
总结
Pulsar-SQL 是一个非常有用的功能,只是我们使用过程中确实发现了一些问题,大部分都已经修复了;
希望对后续使用该功能的朋友有所帮助。
Pulsar
使用 SQL 的方式查询消息队列数据以及踩坑指南的更多相关文章
- C# -- HttpWebRequest 和 HttpWebResponse 的使用 C#编写扫雷游戏 使用IIS调试ASP.NET网站程序 WCF入门教程 ASP.Net Core开发(踩坑)指南 ASP.Net Core Razor+AdminLTE 小试牛刀 webservice创建、部署和调用 .net接收post请求并把数据转为字典格式
C# -- HttpWebRequest 和 HttpWebResponse 的使用 C# -- HttpWebRequest 和 HttpWebResponse 的使用 结合使用HttpWebReq ...
- Linux下进程间通信方式——使用消息队列
一.什么是消息队列 消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法. 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构.我们可以通过发送消息来避免命名管道的 ...
- sql语句,查询昨天的数据
如果在程序中,有前台传来两个时间点:beginTime和endTime,在sql查询中的限制条件就是查询昨天的数据,那么可以这样写: 但是如果在这里要查询昨天的数据的话, 则不能简单地在开始时间的那里 ...
- 【SQL Server数据迁移】64位的机器:SQL Server中查询ORACLE的数据
从SQL Server中查询ORACLE中的数据,可以在SQL Server中创建到ORACLE的链接服务器来实现的,但是根据32位 .64位的机器和软件, 需要用不同的驱动程序来实现. 在64位的机 ...
- 【SQL Server数据迁移】32位的机器:SQL Server中查询ORACLE的数据
从SQL Server中查询ORACLE中的数据,可以在SQL Server中创建到ORACLE的链接服务器来实现的,但是根据32位 .64位的机器和软件,需要用不同的驱动程序来实现. 在32位的机器 ...
- sql语句中查询出的数据添加一列,并且添加默认值
查询出数据,并且要添加一列表中都不存在的数据,且这一列的值都是相等的 select app_id,app_secret from wx_ticket group by app_id; 查询出的数据是 ...
- 将SQL SERVER中查询到的数据导成一个Excel文件
-- ====================================================== T-SQL代码: EXEC master..xp_cmdshell 'bcp 库名. ...
- Netty构建分布式消息队列(AvatarMQ)设计指南之架构篇
目前业界流行的分布式消息队列系统(或者可以叫做消息中间件)种类繁多,比如,基于Erlang的RabbitMQ.基于Java的ActiveMQ/Apache Kafka.基于C/C++的ZeroMQ等等 ...
- Microsoft SQL Server on Linux 踩坑指南
微软用 SQL Server 在 2016 年的时候搞了一个大新闻,宣传 Microsoft ❤️ Linux 打得一众软粉措手不及.但是这还是好事情,Linux 上也有好用的 SQL Server ...
- SQL Server 在Alwayson上使用内存表"踩坑"
200 ? "200px" : this.width)!important;} --> 介绍 因为线上alwayson环境的一个数据库上使用内存表.经过大概一个星期监控程序发 ...
随机推荐
- .NET 通过源码深究依赖注入原理
依赖注入 (DI) 是.NET中一个非常重要的软件设计模式,它可以帮助我们更好地管理和组织组件,提高代码的可读性,扩展性和可测试性.在日常工作中,我们一定遇见过这些问题或者疑惑. Singleton服 ...
- .NET6 + EF Core + MySQL 创建实体和数据库、EFCore 数据迁移
前言 接上期文章<.NET6项目连接数据库方式方法>,有人问了我几个问题,现在就这几个问题,拓展延申一下创建实体类.数据库.把ORM框架和数据迁移都写进去. 安装ORM框架,这里我们采用E ...
- vue使用iframe嵌入html,js方法互调
前段时间 使用h5搞了个用cesium.js做的地图服务功能,后来想整合到vue项目,当然最简单的就是iframe直接拿来用了. 但html和vue的方法交互就是成了问题,vue调用html种方法还好 ...
- Windows 安装ActiveMq5.16.6
Windows 安装ActiveMq5.16.6 前言 最近因为需要在项目中使用MQ,所以就想在我的老Windows机器上装个ActiveMq. 1. 下载安装 先到Activemq官网下载安装需要版 ...
- 最流行的AI绘图工具Midjourney,你不得不知道的使用技巧
关注文章下方公众号,可免费获取AIGC最新学习资料 本文字数:1500,阅读时长大约:10分钟 Midjourney成为了最受欢迎的生成式AI工具之一.它的使用很简单.输入一些文本,Midjourn ...
- 在 Linux 和 Windows 下源码安装 Perl
Perl 是一种功能丰富的计算机程序语言,运行在超过 100 种计算机平台上,适用广泛,从大型机到便携设备,从快速原型创建到大规模可扩展开发.在生物信息分析领域,Perl 主要是做数据预处理.文本处理 ...
- 我们浏览 GitHub 时,经常看到 "WIP" 的分支,即 Work In Progress,正在开发过程中(尚不能独立的运行)的代码。这部分的代码在 Github/Gitlab 中将禁用“合......
本文分享自微信公众号 - 生信科技爱好者(bioitee).如有侵权,请联系 support@oschina.cn 删除.本文参与"OSC源创计划",欢迎正在阅读的你也加入,一起分 ...
- 「AntV」X6开发实践:踩过的坑与解决方案
长期更新版文档请移步语雀(「AntV」X6开发实践:踩过的坑与解决方案 (yuque.com)) ️ | 如何自定义拖拽源? 相信你们在开发中更多的需求是需要自定义拖拽源,毕竟自定义的功能扩展性高一些 ...
- K8S 证书详解(认证)
K8S 证书介绍 在 Kube-apiserver 中提供了很多认证方式,其中最常用的就是 TLS 认证,当然也有 BootstrapToken,BasicAuth 认证等,只要有一个认证通过,那么 ...
- 逆向之Ja3指纹学习
声明 本文章中所有内容仅供学习交流,抓包内容.敏感网址.数据接口均已做脱敏处理,严禁用于商业用途和非法用途,否则由此产生的一切后果均与作者无关,若有侵权,请联系我立即删除! tls tls实际上前身就 ...